Kafka实战
01、Kafka:为什么要使用消息队列
02、Kafka:消息队列的流派
03、Kafka:安装Kafka服务器
04、Kafka:实现生产者和消费者
05、Kafka:消息的偏移量和顺序消费原理
06、Kafka:单播和多播消息的实现
07、Kafka:主题和分区的概念
08、Kafka:搭建Kafka集群
09、Kafka:副本的概念
10、Kafka:集群消费问题
11、Kafka:Java中Kafka生产者的基本实现
12、Kafka:生产者端的同步发送和异步发送
13、Kafka:生产者中的ack配置
14、Kafka:发送消息的缓冲区机制
15、Kafka:消费者消费消息的基本实现
16、Kafka:Offset的自动提交和手动提交
17、Kafka:消费者poll消息的细节与消费者心跳配置
18、Kafka:指定分区和偏移量,时间消费
19、Kafka:新消费组的消费offset规则
20、Kafka:SpringBoot中使用Kafka的基本实现
21、Kafka:消费者的配置细节
22、Kafka:Kafka中Controller,Rebalance,HW,LEO的概念
23、Kafka:Kafka优化之防止消息丢失和重复消费
24、Kafka:Kafka优化之顺序消费的实现
25、Kafka:Kafka优化之解决消息积压问题
26、Kafka:Kafka优化之实现延时队列
27、Kafka:Kafka-eagle监控平台
28、Kafka:Linux部署Kafka集群
29、Kafka:Docker-compose部署Kafka集群
本文档使用 MrDoc 发布
-
+
首页
21、Kafka:消费者的配置细节
### **消费者的配置细节** **配置** 我们可以指定多个主题,分区,偏移量和消费者的并发数 ```python @KafkaListener(groupId = "testGroup", topicPartitions = { //@TopicPartition(topic = "test", partitions = { "0", "1" }), @TopicPartition(topic = "test", partitions = "0", partitionOffsets = @PartitionOffset(partition = "1", initialOffset = "100")) }, concurrency = "3") //concurrency就是同组下的消费者个数,就是并发消费数,建议⼩于等于分区总数 public void listenGroup(ConsumerRecord < String, String > record, Acknowledgment ack) { String value = record.value(); System.out.println(value); System.out.println(record); //⼿动提交offset ack.acknowledge(); } ``` **测试** 我们启动项目后,消费者从test主题的1号分区的offset为100的地方开始消费 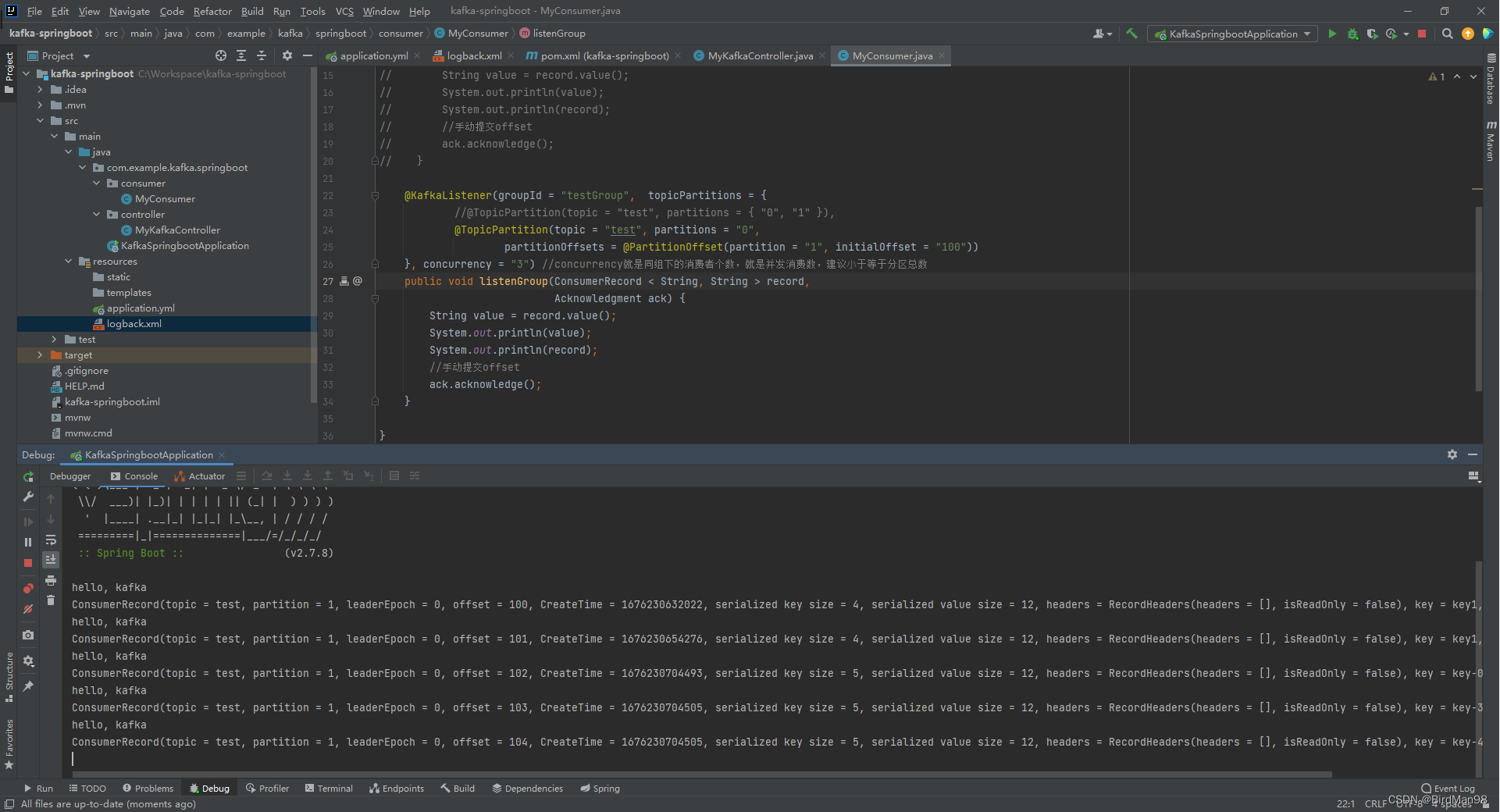
李智
2025年3月17日 13:29
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
分享
链接
类型
密码
更新密码