Kafka实战
01、Kafka:为什么要使用消息队列
02、Kafka:消息队列的流派
03、Kafka:安装Kafka服务器
04、Kafka:实现生产者和消费者
05、Kafka:消息的偏移量和顺序消费原理
06、Kafka:单播和多播消息的实现
07、Kafka:主题和分区的概念
08、Kafka:搭建Kafka集群
09、Kafka:副本的概念
10、Kafka:集群消费问题
11、Kafka:Java中Kafka生产者的基本实现
12、Kafka:生产者端的同步发送和异步发送
13、Kafka:生产者中的ack配置
14、Kafka:发送消息的缓冲区机制
15、Kafka:消费者消费消息的基本实现
16、Kafka:Offset的自动提交和手动提交
17、Kafka:消费者poll消息的细节与消费者心跳配置
18、Kafka:指定分区和偏移量,时间消费
19、Kafka:新消费组的消费offset规则
20、Kafka:SpringBoot中使用Kafka的基本实现
21、Kafka:消费者的配置细节
22、Kafka:Kafka中Controller,Rebalance,HW,LEO的概念
23、Kafka:Kafka优化之防止消息丢失和重复消费
24、Kafka:Kafka优化之顺序消费的实现
25、Kafka:Kafka优化之解决消息积压问题
26、Kafka:Kafka优化之实现延时队列
27、Kafka:Kafka-eagle监控平台
28、Kafka:Linux部署Kafka集群
29、Kafka:Docker-compose部署Kafka集群
本文档使用 MrDoc 发布
-
+
首页
13、Kafka:生产者中的ack配置
### **生产者中的ack配置** 在同步发送的前提下,⽣产者在获得集群返回的ack之前会⼀直阻塞。那么集群什么时候返回ack呢?此时ack有3个配置: - ack = 0 kafka-cluster不需要任何的broker收到消息,就⽴即返回ack给⽣产者,最容易丢消息的,效率是最⾼的 - ack=1(默认): 多副本之间的leader已经收到消息,并把消息写⼊到本地的log中,才会返回ack给⽣产者,性能和安全性是最均衡的 - ack=-1/all。⾥⾯有默认的配置min.insync.replicas=2(默认为1,推荐配置⼤于等于2),此时就需要leader和⼀个follower同步完后,才会返回ack给⽣产者(此时集群中有2个broker已完成数据的接收),这种⽅式最安全,但性能最差。 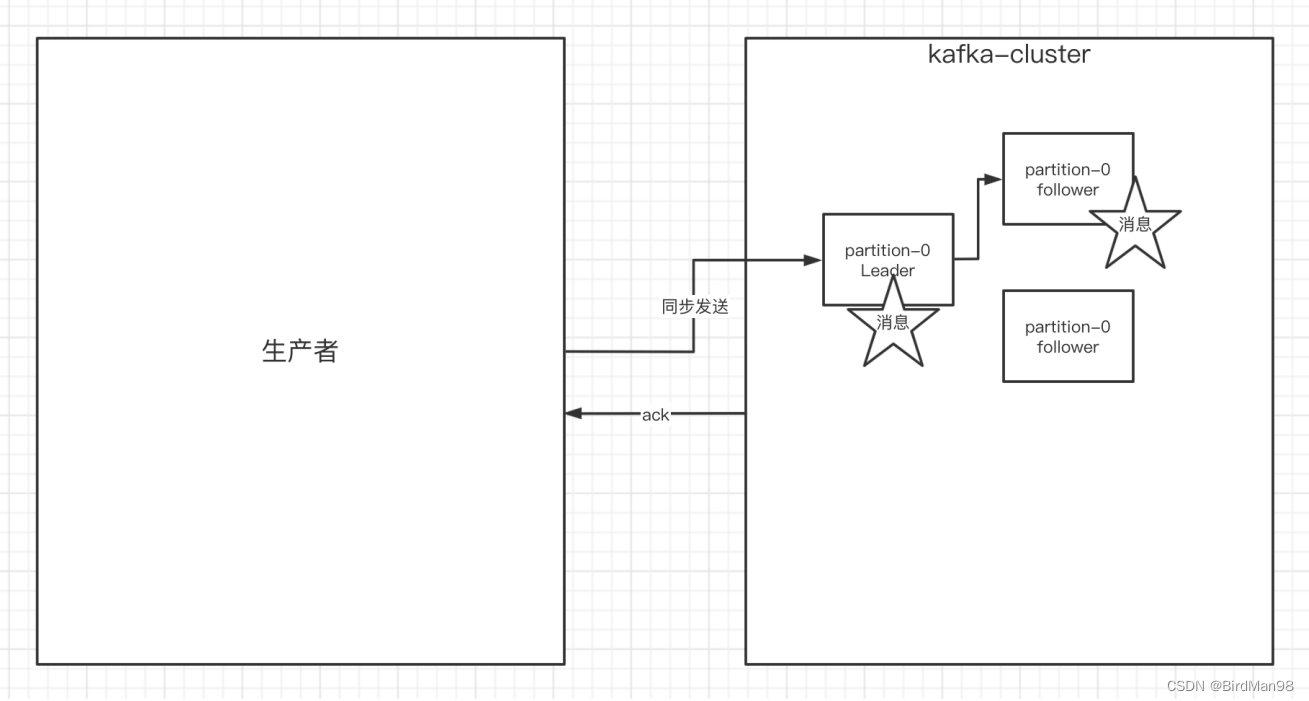 下⾯是关于ack和重试(如果没有收到ack,就开启重试)的配置 ```python props.put(ProducerConfig.ACKS_CONFIG, "1"); /* 发送失败会重试,默认重试间隔100ms,重试能保证消息发送的可靠性,但是也可能造成消息重复发送, ⽐如⽹络抖动,所以需要在接收者那边做好消息接收的幂等性处理 */ props.put(ProducerConfig.RETRIES_CONFIG, 3); //重试间隔设置 props.put(ProducerConfig.RETRY_BACKOFF_MS_CONFIG, 300); ``` 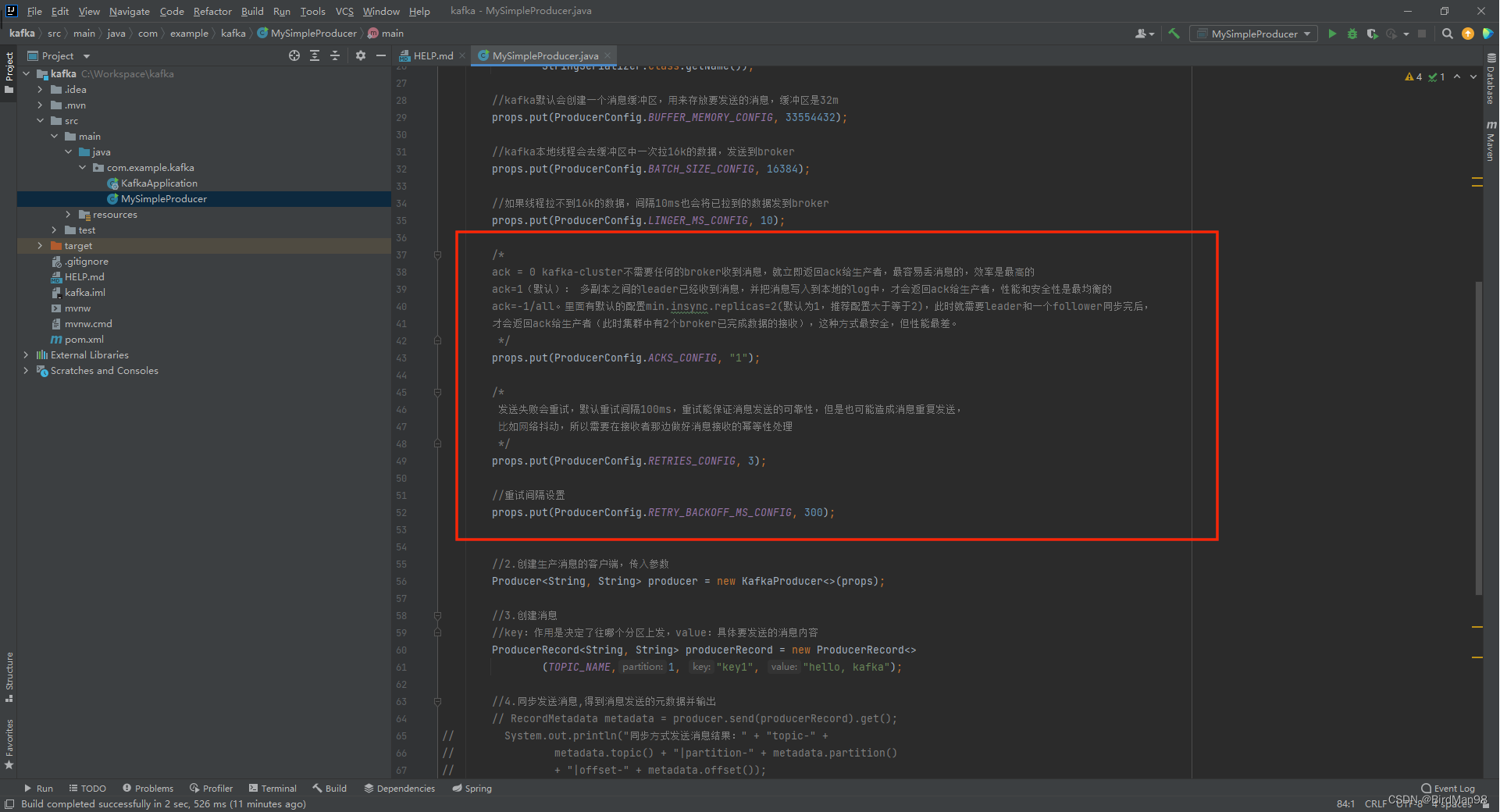
李智
2025年3月17日 13:29
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
分享
链接
类型
密码
更新密码