Kafka实战
01、Kafka:为什么要使用消息队列
02、Kafka:消息队列的流派
03、Kafka:安装Kafka服务器
04、Kafka:实现生产者和消费者
05、Kafka:消息的偏移量和顺序消费原理
06、Kafka:单播和多播消息的实现
07、Kafka:主题和分区的概念
08、Kafka:搭建Kafka集群
09、Kafka:副本的概念
10、Kafka:集群消费问题
11、Kafka:Java中Kafka生产者的基本实现
12、Kafka:生产者端的同步发送和异步发送
13、Kafka:生产者中的ack配置
14、Kafka:发送消息的缓冲区机制
15、Kafka:消费者消费消息的基本实现
16、Kafka:Offset的自动提交和手动提交
17、Kafka:消费者poll消息的细节与消费者心跳配置
18、Kafka:指定分区和偏移量,时间消费
19、Kafka:新消费组的消费offset规则
20、Kafka:SpringBoot中使用Kafka的基本实现
21、Kafka:消费者的配置细节
22、Kafka:Kafka中Controller,Rebalance,HW,LEO的概念
23、Kafka:Kafka优化之防止消息丢失和重复消费
24、Kafka:Kafka优化之顺序消费的实现
25、Kafka:Kafka优化之解决消息积压问题
26、Kafka:Kafka优化之实现延时队列
27、Kafka:Kafka-eagle监控平台
28、Kafka:Linux部署Kafka集群
29、Kafka:Docker-compose部署Kafka集群
本文档使用 MrDoc 发布
-
+
首页
29、Kafka:Docker-compose部署Kafka集群
### **Docker-compose部署Kafka集群** **删除Docker** ```python #停止所有容器 docker stop $(docker ps -a -q) #删除所有容器 docker rm $(docker ps -aq) #删除所有镜像 docker rmi -f $(docker images -qa) #删除旧Docker sudo yum remove docker \ docker-client \ docker-client-latest \ docker-common \ docker-latest \ docker-latest-logrotate \ docker-logrotate \ docker-engine ``` **安装Docker** ```python #安装Docker yum install docker -y #启动Docker service docker start #停止Docker service docker stop #重启Docker service docker restart #配置Docker镜像加速器 sudo tee /etc/docker/daemon.json <<-'EOF' { "registry-mirrors": ["https://mirror.ccs.tencentyun.com"] } EOF #查看Docker运行状态 systemctl status docker ``` **安装Docker-Compose** ```python #安装docker-compose curl -L https://get.daocloud.io/docker/compose/releases/download/1.29.2/docker-compose-uname \ -s-uname -m >` \ /usr/local/bin/docker-compose chmod +x /usr/local/bin/docker-compose docker-compose --version ``` **上传Docker-Compose文件** docker-compose.yml ```python version: '3.1' services: zookeeper: image: wurstmeister/zookeeper container_name: zookeeper ports: - 2181:2181 environment: ZOOKEEPER_CLIENT_PORT: 2181 ZOOKEEPER_TICK_TIME: 2000 KAFKA_JMX_PORT: 39999 restart: always kafka1: image: wurstmeister/kafka container_name: kafka1 depends_on: - zookeeper ports: - 9092:9092 environment: KAFKA_BROKER_ID: 0 KAFKA_NUM_PARTITIONS: 2 KAFKA_ZOOKEEPER_CONNECT: 81.68.232.188:2181 # 这里不能写zookeeper,要写ip KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://81.68.232.188:9092 # 这里不能写zookeeper,要写ip KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:9092 KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 3 KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0 KAFKA_JMX_PORT: 49999 volumes: - /data/docker-compose/kafka/broker1/logs:/opt/kafka/logs - /var/run/docker.sock:/var/run/docker.sock restart: always kafka2: image: wurstmeister/kafka container_name: kafka2 depends_on: - zookeeper ports: - 9093:9093 environment: KAFKA_BROKER_ID: 1 KAFKA_NUM_PARTITIONS: 2 KAFKA_ZOOKEEPER_CONNECT: 81.68.232.188:2181 # 这里不能写zookeeper,要写ip KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://81.68.232.188:9093 # 这里不能写zookeeper,要写ip KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:9093 KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 3 KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0 KAFKA_JMX_PORT: 49999 volumes: - /data/docker-compose/kafka/broker2/logs:/opt/kafka/logs - /var/run/docker.sock:/var/run/docker.sock restart: always kafka3: image: wurstmeister/kafka container_name: kafka3 depends_on: - zookeeper ports: - 9094:9094 environment: KAFKA_BROKER_ID: 2 KAFKA_NUM_PARTITIONS: 2 KAFKA_ZOOKEEPER_CONNECT: 81.68.232.188:2181 # 这里不能写zookeeper,要写ip KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://81.68.232.188:9094 # 这里不能写zookeeper,要写ip KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:9094 KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 3 KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0 KAFKA_JMX_PORT: 49999 volumes: - /data/docker-compose/kafka/broker3/logs:/opt/kafka/logs - /var/run/docker.sock:/var/run/docker.sock restart: always ``` **启动集群** ```python cd /root docker-compose up -d docker ps ``` 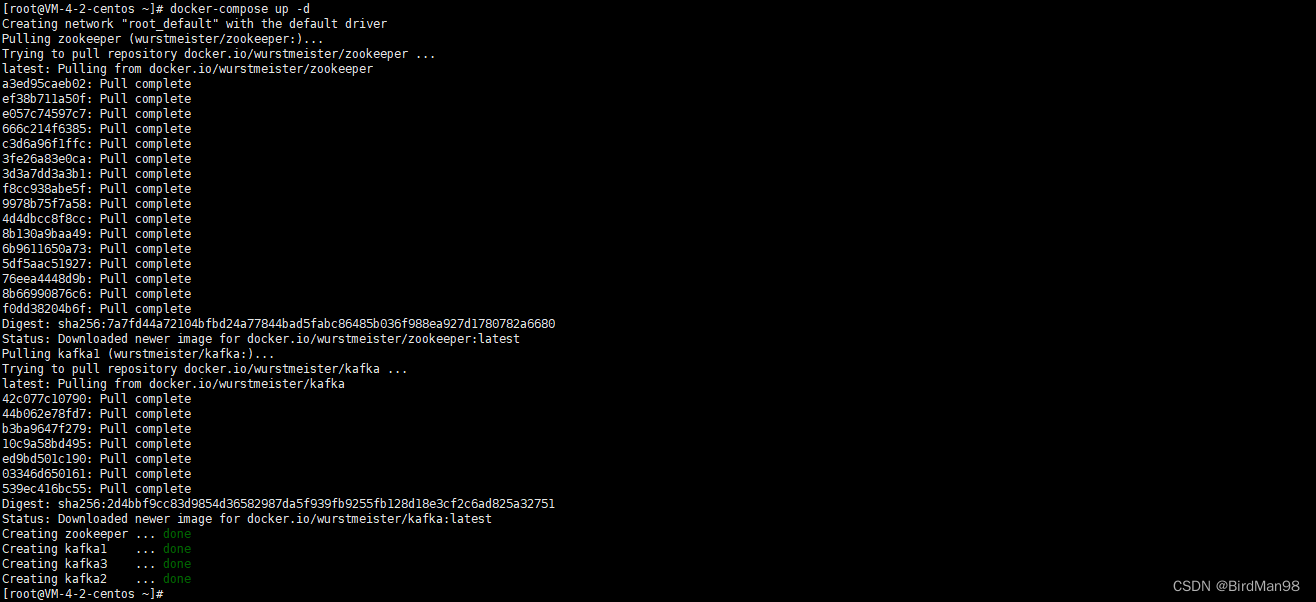 **测试** 创建主题 ```python docker exec -it kafka1 bash cd /opt/kafka/bin/ ./kafka-topics.sh \ --create \ --zookeeper 81.68.232.188:2181 \ --replication-factor 3 \ --partitions 2 \ --topic test ``` 查看主题 ```python #查看主题详情 ./kafka-topics.sh \ --zookeeper 81.68.232.188:2181 \ --describe \ --topic test ``` 删除主题 ```python ./kafka-topics.sh \ --delete \ --zookeeper 81.68.232.188:2181 \ --topic test ``` 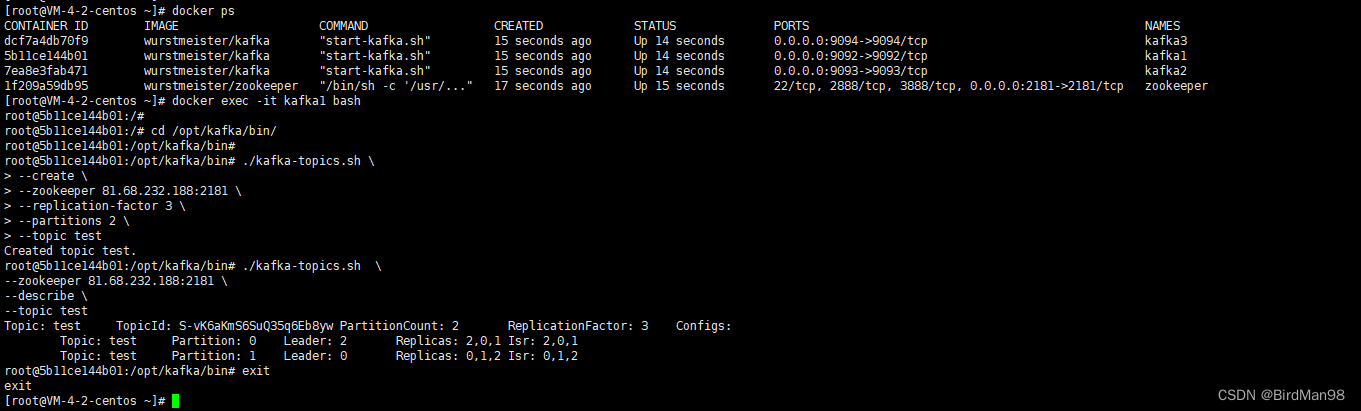 ### **SpringBoot** 可以连接SpringBoot做测试 - YML ```python server: port: 80 spring: kafka: bootstrap-servers: 81.68.232.188:9092,81.68.232.188:9093,81.68.232.188:9094 producer: retries: 3 batch-size: 16384 buffer-memory: 33554432 acks: 1 key-serializer: org.apache.kafka.common.serialization.StringSerializer value-serializer: org.apache.kafka.common.serialization.StringSerializer consumer: group-id: default-group enable-auto-commit: false auto-offset-reset: earliest key-deserializer: org.apache.kafka.common.serialization.StringDeserializer value-deserializer: org.apache.kafka.common.serialization.StringDeserializer max-poll-records: 500 listener: ack-mode: MANUAL_IMMEDIATE # redis: # host: 172.16.253.21 ``` - POM ```python <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.7.8</version> <relativePath/> <!-- lookup parent from repository --> </parent> .... <dependency> <groupId>org.springframework.kafka</groupId> <artifactId>spring-kafka</artifactId> </dependency> ``` - 生产者 ```python @RestController @RequestMapping("/msg") public class MyKafkaController { private final static String TOPIC_NAME = "test"; @Resource private KafkaTemplate<String,String> kafkaTemplate; @RequestMapping("/send") public String sendMessage(){ kafkaTemplate.send(TOPIC_NAME,0,"key","this is a message!"); return "send success!"; } } ``` - 消费者 ```python @Component public class MyConsumer { @KafkaListener(topics = "test",groupId = "default-group") public void listenGroup(ConsumerRecord<String, String> record, Acknowledgment ack) { String value = record.value(); System.out.println(value); System.out.println(record); //⼿动提交offset ack.acknowledge(); } // @KafkaListener(groupId = "default-group", topicPartitions = { // //@TopicPartition(topic = "test", partitions = { "0", "1" }), // @TopicPartition(topic = "test", partitions = "0", // partitionOffsets = @PartitionOffset(partition = "1", initialOffset = "100")) // }, concurrency = "3") //concurrency就是同组下的消费者个数,就是并发消费数,建议⼩于等于分区总数 // public void listenGroup(ConsumerRecord < String, String > record, // Acknowledgment ack) { // String value = record.value(); // System.out.println(value); // System.out.println(record); // //⼿动提交offset // ack.acknowledge(); // } } ``` **测试** 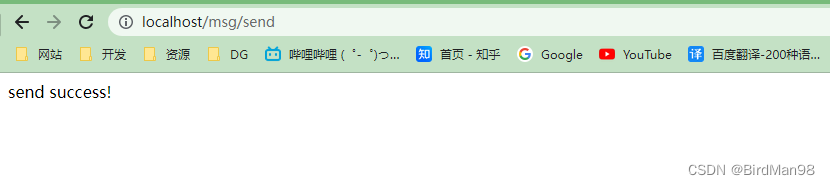 
李智
2025年3月17日 13:29
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
分享
链接
类型
密码
更新密码