Kafka实战
01、Kafka:为什么要使用消息队列
02、Kafka:消息队列的流派
03、Kafka:安装Kafka服务器
04、Kafka:实现生产者和消费者
05、Kafka:消息的偏移量和顺序消费原理
06、Kafka:单播和多播消息的实现
07、Kafka:主题和分区的概念
08、Kafka:搭建Kafka集群
09、Kafka:副本的概念
10、Kafka:集群消费问题
11、Kafka:Java中Kafka生产者的基本实现
12、Kafka:生产者端的同步发送和异步发送
13、Kafka:生产者中的ack配置
14、Kafka:发送消息的缓冲区机制
15、Kafka:消费者消费消息的基本实现
16、Kafka:Offset的自动提交和手动提交
17、Kafka:消费者poll消息的细节与消费者心跳配置
18、Kafka:指定分区和偏移量,时间消费
19、Kafka:新消费组的消费offset规则
20、Kafka:SpringBoot中使用Kafka的基本实现
21、Kafka:消费者的配置细节
22、Kafka:Kafka中Controller,Rebalance,HW,LEO的概念
23、Kafka:Kafka优化之防止消息丢失和重复消费
24、Kafka:Kafka优化之顺序消费的实现
25、Kafka:Kafka优化之解决消息积压问题
26、Kafka:Kafka优化之实现延时队列
27、Kafka:Kafka-eagle监控平台
28、Kafka:Linux部署Kafka集群
29、Kafka:Docker-compose部署Kafka集群
本文档使用 MrDoc 发布
-
+
首页
07、Kafka:主题和分区的概念
### **主题和分区的概念** **主题Topic** 主题-topic在kafka中是⼀个逻辑的概念,kafka通过topic将消息进⾏分类。不同的topic会被订阅该topic的消费者消费。 但是有⼀个问题,如果说这个topic中的消息⾮常⾮常多,多到需要⼏T来存,因为消息是会被保存到log⽇志⽂件中的。为了解决这个⽂件过⼤的问题,kafka提出了Partition分区的概念 **分区Partition** **分区的概念** 通过partition将⼀个topic中的消息分区来存储。这样的好处有多个: - 分区存储,可以解决统⼀存储⽂件过⼤的问题 - 提供了读写的吞吐量:读和写可以同时在多个分区中进⾏ 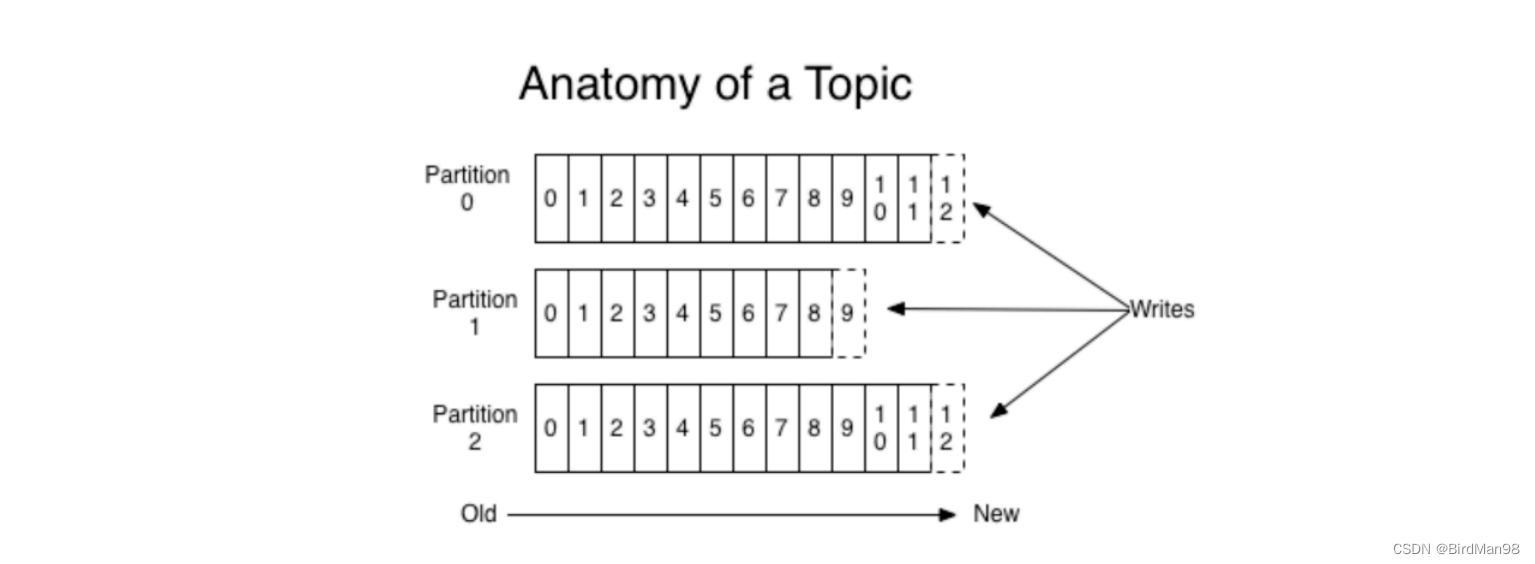 ⼀个主题中的消息量是⾮常⼤的,因此可以通过分区的设置,来分布式存储这些消息。⽐如⼀个topic创建了3个分区。那么topic中的消息就会分别存放在这三个分区中。 **创建多分区的主题** ```python ./kafka-topics.sh \ --create \ --zookeeper 172.16.253.35:2181 \ --replication-factor 1 \ --partitions 2 \ --topic test1 ``` **可以通过这样的命令查看topic的分区信息** ```python ./kafka-topics.sh \ --describe \ --zookeeper 172.16.253.35:2181 \ --topic test1 ``` **kafka中消息⽇志⽂件中保存的内容** - 00000.log: 这个⽂件中保存的就是消息 - __consumer_offsets-49: kafka内部⾃⼰创建了__consumer_offsets主题包含了50个分区。这个主题⽤来存放消费者消费某个主题的偏移量。因为每个消费者都会⾃⼰维护着消费的主题的偏移量,也就是说每个消费者会把消费的主题的偏移量⾃主上报给kafka中的默认主题:consumer_offsets。因此kafka为了提升这个主题的并发性,默认设置了50个分区。 - 提交到哪个分区:通过hash函数:hash(consumerGroupId) % __consumer_offsets主题的分区数 - 提交到该主题中的内容是:key是consumerGroupId+topic+分区号,value就是当前offset的值 - ⽂件中保存的消息,默认保存7天。七天到后消息会被删除。 
李智
2025年3月17日 13:29
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
分享
链接
类型
密码
更新密码