AI大模型学习
1、环境搭建
2、Embedding与向量数据库
3、RAG技术与应用
4、RAG高级技术与实践
5、LlamaIndex知识管理与信息检索
6、基于LlamaIndex开发的中医临床诊疗助手
7、LangChain多任务应用开发
8、Function Calling与Agent 智能体
9、Agent应用与图状态编排框架LangGraph
10、基于LangGraph实现智能分诊系统
11、MCP应用技术开发
12、AI 应用开发新范式 MCP 技术详解
13、基于LangGraph的多智能体交互系统
14、企业级智能分诊系统RAG项目
15、LangGraph与Agno-AGI深度对比分析
本文档使用 MrDoc 发布
-
+
首页
4、RAG高级技术与实践
# RAG高级技术与实践 ## 💡 学习目标 1. RAG技术树 2. RAFT方法论 3. RAG高效召回方法 4. Qwen-Agent构建RAG 5. RAG质量评估 6. 商业落地实施RAG工程核心步骤 ## 1. RAG技术树 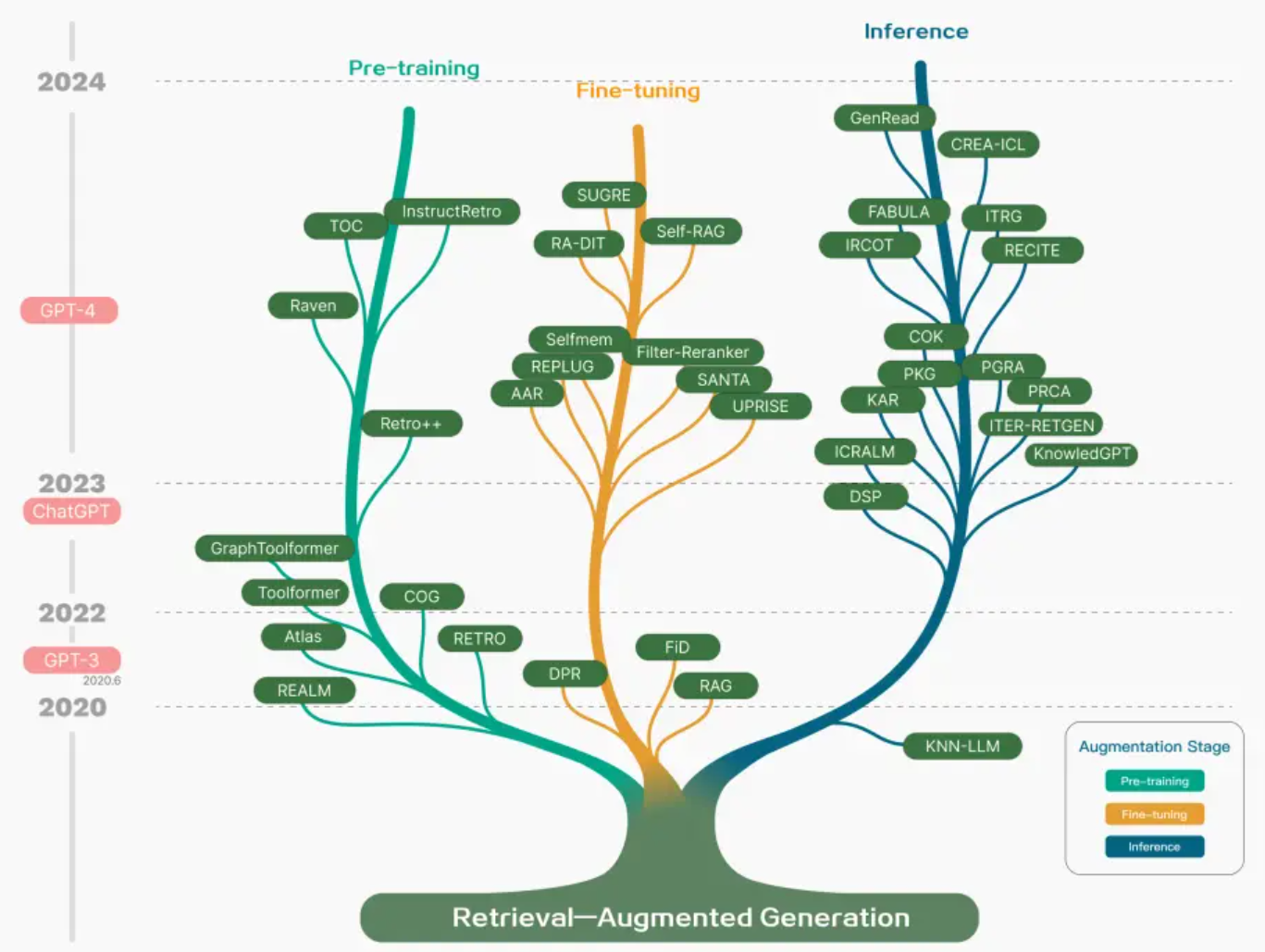 - RAG研究的技术树主要涉及预训练(Pre-training)、微调(Fine-tuning)和推理(Inference)等阶段。 - 随着LLM的出现,RAG的研究最初侧重于利用LLMs强大的上下文学习能力,主要集中在推理阶段。 - 随后的研究进一步深入,逐渐与LLMs的微调阶段更加融合。研究人员也在探索通过检索增强技术来提升预训练阶段的语言模型性能。 参考文章:https://www.promptingguide.ai/research/rag ## 2. RAFT 方法 RAFT方法(Retrieval Augmented Fine Tuning) RAFT: Adapting Language Model to Domain Specific RAG, 2024 https://arxiv.org/pdf/2403.10131 如何最好地准备考试? - 基于微调的方法通过“学习”来实现“记忆”输入文档或回答练习题而不参考文档。 - 或者,基于上下文检索的方法未能利用固定领域所提供的学习机会,相当于参加开卷考试但没有事先复习。 - 相比之下,我们的方法RAFT利用了微调与问答对,并在一个模拟的不完美检索环境中参考文档——从而有效地为开卷考试环境做准备。 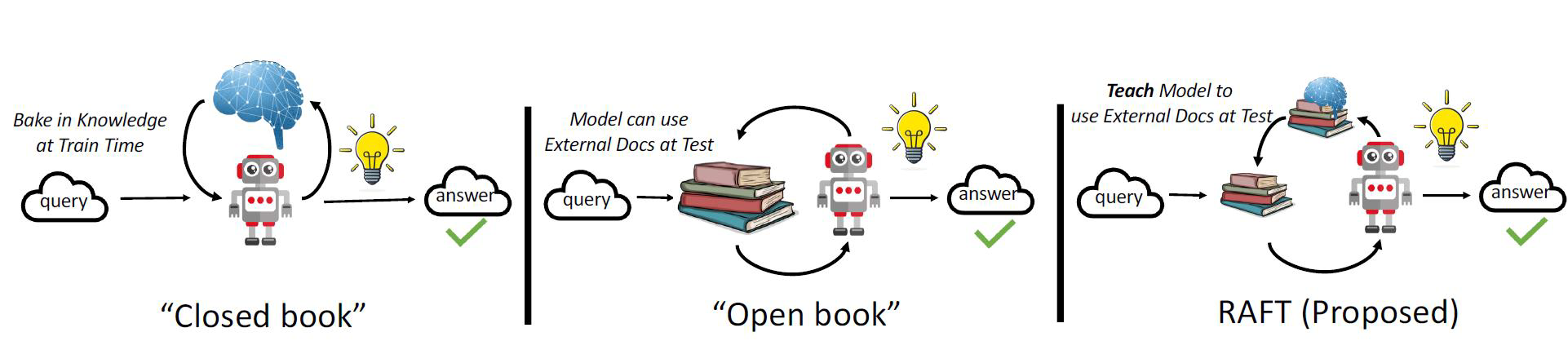 让LLMs从一组正面和干扰文档中读取解决方案,这与标准的RAG设置形成对比,因为在标准的RAG设置中,模型是基于检索器输出进行训练的,这包含了记忆和阅读的混合体。在测试时,所有方法都遵循标准的RAG设置,即提供上下文中排名前k的检索文档。 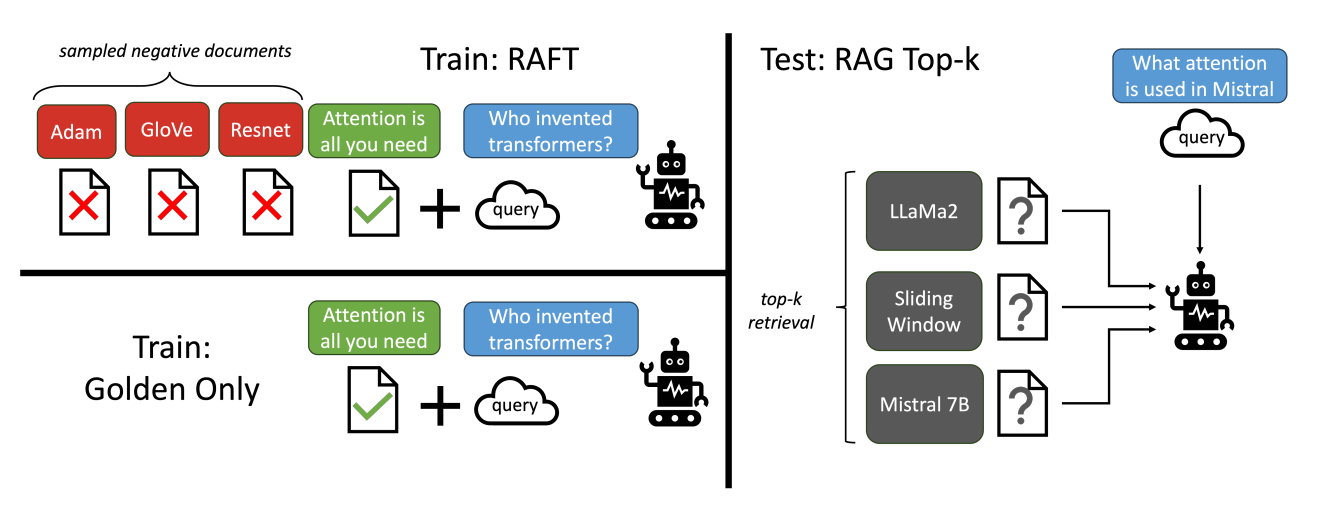 微调数据集准备样例: 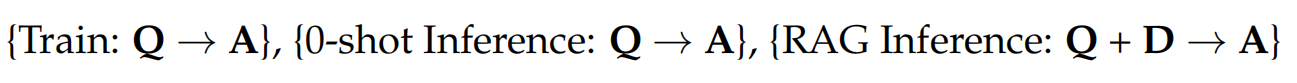 RAFT在所有专业领域的RAG性能上有所提升(在PubMed、HotPot、HuggingFace、Torch Hub和TensorflowHub等多个领域),领域特定的微调提高了基础模型的性能,RAFT无论是在有RAG的情况下还是没有RAG的情况下,都持续优于现有的领域特定微调方法。这表明了需要在上下文中训练模型。 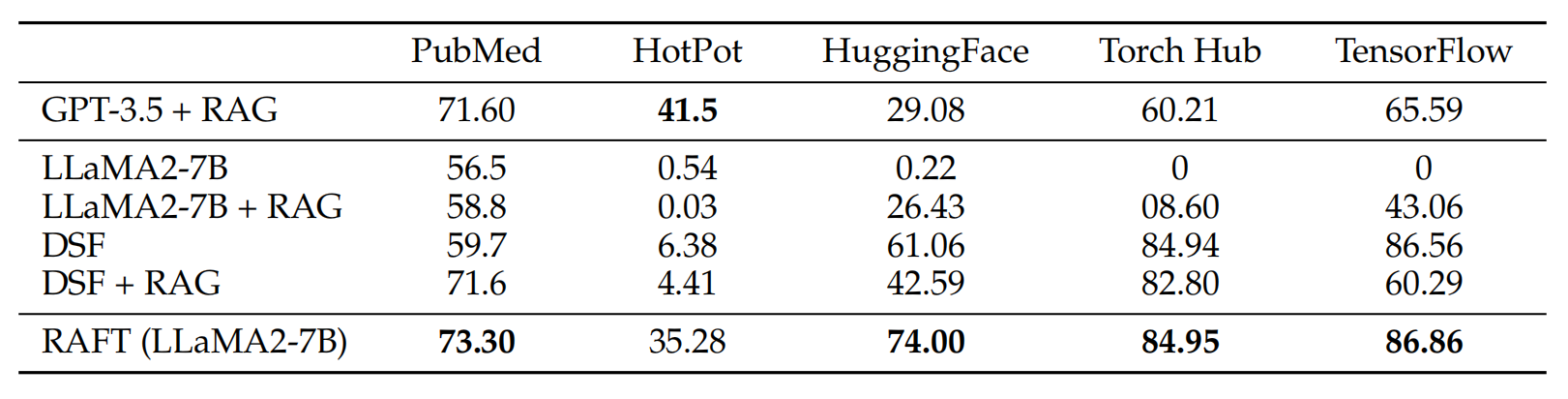 **总结:** RAFT方法(Retrieval Augmented Fine Tuning): - 适应特定领域的LLMs对于许多新兴应用至关重要,但如何有效融入信息仍是一个开放问题。 - RAFT结合了检索增强生成(RAG)和监督微调(SFT),从而提高模型在特定领域内回答问题的能力。 - 训练模型识别并忽略那些不能帮助回答问题的干扰文档,只关注和引用相关的文档。 - 通过在训练中引入干扰文档,提高模型对干扰信息的鲁棒性,使其在测试时能更好地处理检索到的文档。 训练示例:https://github.com/lumpenspace/raft ## 3. RAG高效召回方法 <div class="alert alert-success"> Thinking:都有哪些RAG召回的策略,提升召回的质量? </div> ### 3.1. 合理设置TOP_K ```python # docs = knowledgeBase.similarity_search(query, k=10) # pip install pypdf2 # pip install dashscope # pip install langchain # pip install langchain-openai # pip install langchain-community # pip install faiss-cpu ``` ```python import os import logging import pickle from PyPDF2 import PdfReader from langchain.chains.question_answering import load_qa_chain from langchain_community.embeddings import DashScopeEmbeddings from langchain_community.callbacks.manager import get_openai_callback from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain_community.vectorstores import FAISS from typing import List, Tuple def extract_text_with_page_numbers(pdf) -> Tuple[str, List[int]]: """ 从PDF中提取文本并记录每行文本对应的页码 参数: pdf: PDF文件对象 (需支持.pages属性迭代) 返回: text: 提取的文本内容 (行之间用\\n分隔) page_numbers: 每行文本对应的页码列表 (与text.split('\\n')严格对应) """ all_lines = [] # 存储所有文本行 page_numbers = [] # 存储每行对应的页码 for page_number, page in enumerate(pdf.pages, start=1): extracted_text = page.extract_text() if not extracted_text or extracted_text.isspace(): logging.warning(f"No text found on page {page_number}.") continue # 跳过空页面 # 按行分割并保留空行 (关键: keepends=False 确保不保留换行符) lines = extracted_text.splitlines(keepends=False) # 过滤掉纯空白行 (可选,根据需求决定是否保留空行) # lines = [line for line in lines if line.strip() != ""] # 记录有效行及其页码 all_lines.extend(lines) page_numbers.extend([page_number] * len(lines)) # 重建完整文本 (行之间用\\n连接) text = "\n".join(all_lines) return text, page_numbers def process_text_with_splitter(text: str, page_numbers: List[int], save_path: str = None) -> FAISS: """ 处理文本并创建向量存储 参数: text: 提取的文本内容 page_numbers: 每行文本对应的页码列表 save_path: 可选,保存向量数据库的路径 返回: knowledgeBase: 基于FAISS的向量存储对象 """ # 创建文本分割器(递归字符文本分割器),用于将长文本分割成小块 text_splitter = RecursiveCharacterTextSplitter( separators = ["\n\n", "\n", ".", " ", ""], chunk_size = 512, chunk_overlap = 128, length_function = len, ) # 分割文本 chunks = text_splitter.split_text(text) # logging.debug(f"Text split into {len(chunks)} chunks.") print(f"文本被分割成 {len(chunks)} 个块。") # 创建嵌入模型,OpenAI嵌入模型,配置环境变量 OPENAI_API_KEY # embeddings = OpenAIEmbeddings() # 调用阿里百炼平台文本嵌入模型,配置环境变量 DASHSCOPE_API_KEY embeddings = DashScopeEmbeddings( model = "text-embedding-v4" ) # 从文本块创建知识库 knowledgeBase = FAISS.from_texts(chunks, embeddings) print("已从文本块创建知识库...") # 存储每个文本块对应的页码信息 page_info = {chunk: page_numbers[i] for i, chunk in enumerate(chunks)} knowledgeBase.page_info = page_info # 如果提供了保存路径,则保存向量数据库和页码信息 if save_path: # 确保目录存在 os.makedirs(save_path, exist_ok=True) # 保存FAISS向量数据库 knowledgeBase.save_local(save_path) print(f"向量数据库已保存到: {save_path}") # 保存页码信息到同一目录 with open(os.path.join(save_path, "page_info.pkl"), "wb") as f: pickle.dump(page_info, f) print(f"页码信息已保存到: {os.path.join(save_path, 'page_info.pkl')}") return knowledgeBase def load_knowledge_base(load_path: str, embeddings = None) -> FAISS: """ 从磁盘加载向量数据库和页码信息 参数: load_path: 向量数据库的保存路径 embeddings: 可选,嵌入模型。如果为None,将创建一个新的DashScopeEmbeddings实例 返回: knowledgeBase: 加载的FAISS向量数据库对象 """ # 如果没有提供嵌入模型,则创建一个新的 if embeddings is None: embeddings = DashScopeEmbeddings( model="text-embedding-v4" ) # 加载FAISS向量数据库,添加allow_dangerous_deserialization=True参数以允许反序列化 knowledgeBase = FAISS.load_local(load_path, embeddings, allow_dangerous_deserialization=True) print(f"向量数据库已从 {load_path} 加载。") # 加载页码信息 page_info_path = os.path.join(load_path, "page_info.pkl") if os.path.exists(page_info_path): with open(page_info_path, "rb") as f: page_info = pickle.load(f) knowledgeBase.page_info = page_info print("页码信息已加载。") else: print("警告: 未找到页码信息文件。") return knowledgeBase # 读取PDF文件 pdf_reader = PdfReader('./浦发上海浦东发展银行西安分行个金客户经理考核办法.pdf') # 提取文本和页码信息 text, page_numbers = extract_text_with_page_numbers(pdf_reader) print(f"提取的文本长度: {len(text)} 个字符。") # 处理文本并创建知识库,同时保存到磁盘 save_dir = "./vector_db" knowledgeBase = process_text_with_splitter(text, page_numbers, save_path=save_dir) # 处理文本并创建知识库 knowledgeBase = process_text_with_splitter(text, page_numbers) knowledgeBase ``` ```python 提取的文本长度: 3889 个字符。 文本被分割成 10 个块。 已从文本块创建知识库... 向量数据库已保存到: ./vector_db 页码信息已保存到: ./vector_db\page_info.pkl 文本被分割成 10 个块。 已从文本块创建知识库... <langchain_community.vectorstores.faiss.FAISS at 0x20523f22410> ``` ```python import os from langchain_community.llms import Tongyi # 设置查询问题 query = "客户经理被投诉了,投诉一次扣多少分?" # query = "客户经理每年评聘申报时间是怎样的?" if query: # 调用阿里百炼平台文本嵌入模型,配置环境变量 DASHSCOPE_API_KEY embeddings = DashScopeEmbeddings( model = "text-embedding-v4" ) # 初始化对话大模型 llm = Tongyi( model_name="qwen-max", dashscope_api_key=os.getenv("DASHSCOPE_API_KEY") ) # 从磁盘加载向量数据库 loaded_knowledgeBase = load_knowledge_base("./vector_db", embeddings) # 使用加载的知识库进行查询 top_k 和 top_n # 一般比较优的文档个数 5 个左右 docs = loaded_knowledgeBase.similarity_search(query, k=5) print(docs) # 加载问答链 chain = load_qa_chain(llm, chain_type="stuff") # 准备输入数据 input_data = {"input_documents": docs, "question": query} # 执行问答链 response = chain.invoke(input=input_data) print(response["output_text"]) ``` ```python 向量数据库已从 ./vector_db 加载。 页码信息已加载。 [Document(id='bde1d167-116b-4847-ab40-604cf8e78541', metadata={}, page_content='4.个贷业务(季新增发放个贷)为中级以上客户经理考核进入的最低标准。 \n5.超出最低考核标准可相互折算,折算标准: 50万储蓄 =50万个贷 =50张有效卡 =5分(折算以 5分为单位) \n \n \n百度文库 - 好好学习,天天向上 \n-5 第五章 工作质量考核标准 \n第九条 工作质量考核实行扣分制。工作质量指个金客户经理在\n从事所有个人业务时出现投诉、差错及风险。该项考核最多扣 50分,\n如发生重大差错事故,按分行有关制度处理。 \n(一)服务质量考核: \n1、工作责任心不强,缺乏配合协作精神;扣 5分 \n2、客户服务效率低,态度生硬或不及时为客户提供维护服务,\n有客户投诉的 ,每投诉一次扣 2分 \n3、不服从支行工作安排,不认真参加分(支)行宣传活动的,\n每次扣 2分; \n4、未能及时参加分行(支行)组织的各种业务培训、考试和专\n题活动的每次扣 2分; \n5、未按规定要求进行贷前调查、贷后检查工作的,每笔扣 5分; \n6、未建立信贷台帐资料及档案的每笔扣 5分; \n7、在工作中有不廉洁自律情况的每发现一次扣 50分。 \n(二)个人资产质量考核:'), Document(id='28eaa412-8e56-4bd0-9e56-dc27906f0390', metadata={}, page_content='题活动的每次扣 2分; \n5、未按规定要求进行贷前调查、贷后检查工作的,每笔扣 5分; \n6、未建立信贷台帐资料及档案的每笔扣 5分; \n7、在工作中有不廉洁自律情况的每发现一次扣 50分。 \n(二)个人资产质量考核: \n当季考核收息率 97%以上为合格,每降 1个百分点扣 2分;不\n良资产零为合格,每超一个个百分点扣 1分。 \nA.发生跨月逾期,单笔不超过 10万元,当季收回者,扣 1分。 \nB.发生跨月逾期, 2笔以上累计金额不超过 20万元,当季收回\n者,扣 2分;累计超过 20万元以上的,扣 4分。 \n百度文库 - 好好学习,天天向上 \n-6 C.发生逾期超过 3个月,无论金额大小和笔数,扣 10分。 \n \n第六章 聘任考核程序 \n第十条 凡达到本办法第三章规定的该技术职务所要求的行内职\n工,都可向分行人力资源部申报个金客户经理评聘。 \n第十一条 每年一月份为客户经理评聘的申报时间,由分行人力\n资源部、个人业务部每年二月份组织统一的资格考试。考试合格者由\n分行颁发个金客户经理资格证书,其有效期为一年。 \n第十二条 客户经理聘任实行开放式、浮动制,即:本人申报 —'), Document(id='a530fd9d-af75-44a9-9c51-5104edb9073a', metadata={}, page_content='类别 行员级别 考核分值 准入标准 \n储蓄业务 个贷业务 卡业务 \n客户经理助理 5 90 300万 500张 \n4 95 \n百度文库 - 好好学习,天天向上 \n-4 3 100 \n2 105 \n1 110 \n客户经理 5 115 300万 500张 \n4 120 \n3 125 \n2 130 \n1 135 \n高级客户经理 5 140 500万 800万 \n4 145 \n3 150 \n2 155 \n1 160 \n资深客户经理 5 165 500万 800万 \n4 170 \n3 175 \n2 180 \n1 185 \n说明: 1.储蓄业务(季日均余额)为各类个金客户经理考核进入的最低标准。 \n2.卡业务(季新增发有效卡量)为见习、 D类、初级客户经理进入的最低标准。 \n3.有效卡的概念:每张卡月均余额为 100元以上。 \n4.个贷业务(季新增发放个贷)为中级以上客户经理考核进入的最低标准。 \n5.超出最低考核标准可相互折算,折算标准: 50万储蓄 =50万个贷 =50张有效卡 =5分(折算以 5分为单位)'), Document(id='ace98e39-356b-42c6-ad37-017e23217b1c', metadata={}, page_content='构成中基础薪点不低于 40%。 \n \n第八章 管理与奖惩 \n第十八条 个金客户经理管理机构为分行客户经理管理委员会。\n管理委员会组成人员:行长或主管业务副行长,个人业务部、人力资\n源部、风险管理部负责人。 \n第十九条 客户经理申报的各种信息必须真实。分行个人业务部\n需对其工作业绩数据进行核实,并对其真实性负责;分行人事部门需\n对其学历、工作阅历等基本信息进行核实,并对其真实性负责。 \n第二十条 对因工作不负责任使资产质量产生严重风险或造成损\n失的给予降级直至开 除处分,构成渎职罪的提请司法部门追究刑事责\n任。 \n \n百度文库 - 好好学习,天天向上 \n-9 第九章 附 则 \n第二十一条 本办法自发布之日起执行。 \n第二十二条 本办法由上海浦东发展银行西安分行行负责解释和\n修改。'), Document(id='e816182b-61fc-474d-82a5-9c0d8d9de040', metadata={}, page_content='事部门对正科级的待遇标准。 \n业绩奖励收入是指客户经理每个业绩考核期间的实际业绩所给\n与兑现的奖金部分。 \n日常工作绩效收入是按照个金客户经理所从事的事务性工作进\n行定量化考核,经过工作的完成情况进行奖金分配。该项奖金主要由\n个人金融部总经理和各支行的行长其从事个人金融业务的人员进行\n分配,主要侧重分配于从事个金业务的基础工作和创新工作。 \n百度文库 - 好好学习,天天向上 \n-8 第十五条 各项考核分值总计达到某一档行员级别考核分值标\n准,个金客户经理即可在下一季度享受该级行员的薪资标准。下一季\n度考核时,按照已享受行员级别考核折算比值进行考核,以次类推。 \n第十六条 对已聘为各级客户经理的人员,当工作业绩考核达不\n到相应技术职务要求下限时,下一年技术职务相应下调 。 \n第十七条 为保护个人业务客户经理创业的积极性,暂定其收入\n构成中基础薪点不低于 40%。 \n \n第八章 管理与奖惩 \n第十八条 个金客户经理管理机构为分行客户经理管理委员会。\n管理委员会组成人员:行长或主管业务副行长,个人业务部、人力资\n源部、风险管理部负责人。')] 根据提供的信息,客户经理被投诉的扣分标准如下: - 如果客户经理因为服务效率低、态度生硬或未及时为客户提供维护服务而被投诉,**每次投诉扣2分**。 因此,**客户经理被投诉一次扣2分**。 ``` ### 3.2. 改进索引算法 **知识图谱:** 利用知识图谱中的语义信息和实体关系,增强对查询和文档的理解,提升召回的相关性 ### 3.3. 引入重排序(Reranking) **重排序模型:** 对召回结果进行重排,提升问题和文档的相关性。常见的重排序模型有 `BGE-Rerank` 和 `Cohere Rerank`。 - 场景:用户查询“如何提高深度学习模型的训练效率?” - 召回结果:初步召回10篇文档,其中包含与“深度学习”、“训练效率”相关的文章。 - 重排序:BGE-Rerank对召回的10篇文档进行重新排序,将与“训练效率”最相关的文档(如“优化深度学习训练的技巧”)排在最前面,而将相关性较低的文档(如“深度学习基础理论”)排在后面。 **混合检索:** 结合向量检索和关键词检索的优势,通过重排序模型对结果进行归一化处理,提升召回质量。 ### 3.4. 优化查询扩展 **相似语义改写:** 使用大模型将用户查询改写成多个语义相近的查询,提升召回多样性。 - 例如,LangChain的 `MultiQueryRetriever` 支持多查询召回,再进行回答问题。 ```python import os from langchain.retrievers import MultiQueryRetriever from langchain_community.vectorstores import FAISS from langchain_community.embeddings import DashScopeEmbeddings from langchain_community.llms import Tongyi # 初始化大语言模型 DASHSCOPE_API_KEY = os.getenv("DASHSCOPE_API_KEY") llm = Tongyi( model_name="qwen-max", dashscope_api_key=DASHSCOPE_API_KEY ) # 创建嵌入模型 embeddings = DashScopeEmbeddings( model="text-embedding-v3", dashscope_api_key=DASHSCOPE_API_KEY ) # 加载向量数据库,添加allow_dangerous_deserialization=True参数以允许反序列化 vectorstore = FAISS.load_local("./vector_db", embeddings, allow_dangerous_deserialization=True) # 创建MultiQueryRetriever retriever = MultiQueryRetriever.from_llm( retriever=vectorstore.as_retriever(), llm=llm ) # 示例查询 query = "客户经理的考核标准是什么?" # 执行查询 results = retriever.get_relevant_documents(query) # 打印结果 print(f"查询: {query}") print(f"找到 {len(results)} 个相关文档:") for i, doc in enumerate(results): print(f"\n文档 {i+1}:") print(doc.page_content[:200] + "..." if len(doc.page_content) > 200 else doc.page_content) ``` ```python 查询: 客户经理的考核标准是什么? 找到 4 个相关文档: 文档 1: 百度文库 - 好好学习,天天向上 -7 入围,并由所在行制定临时奖励办法。 第七章 考核待遇 第十五条 个人金融业务客户经理的收入基本由三部分组成: 客 户经理等级基本收入、业绩奖励收入和日常工作绩效收入。 客户经理等级基本收入是指客户经理的每月基本收入, 基本分为 助理客户经理、客户经理、高级客户经理和资深客户经理四大层面, 在每一层面分为若干等级。 客户经理的... 文档 2: 4.个贷业务(季新增发放个贷)为中级以上客户经理考核进入的最低标准。 5.超出最低考核标准可相互折算,折算标准: 50万储蓄 =50万个贷 =50张有效卡 =5分(折算以 5分为单位) 百度文库 - 好好学习,天天向上 -5 第五章 工作质量考核标准 第九条 工作质量考核实行扣分制。工作质量指个金客户经理在 从事所有个人业务时出现投诉、差错及风险。该项考核最多扣 5... 文档 3: 事部门对正科级的待遇标准。 业绩奖励收入是指客户经理每个业绩考核期间的实际业绩所给 与兑现的奖金部分。 日常工作绩效收入是按照个金客户经理所从事的事务性工作进 行定量化考核,经过工作的完成情况进行奖金分配。该项奖金主要由 个人金融部总经理和各支行的行长其从事个人金融业务的人员进行 分配,主要侧重分配于从事个金业务的基础工作和创新工作。 百度文库 - 好好学习,天天向上 -8 第十... 文档 4: 类别 行员级别 考核分值 准入标准 储蓄业务 个贷业务 卡业务 客户经理助理 5 90 300万 500张 4 95 百度文库 - 好好学习,天天向上 -4 3 100 2 105 1 110 客户经理 5 115 300万 500张 4 120 3 125 2 130 1 135 高级客户经理 5 140 500万 800万 4 145... ``` ### 3.5. 双向改写 将查询改写成文档(Query2Doc)或为文档生成查询(Doc2Query),缓解短文本向量化效果差的问题 **1. Query2Doc:将查询改写成文档** - 用户查询:“如何提高深度学习模型的训练效率?” - Query2Doc 改写: - 原始查询较短,可能无法充分表达用户意图。 - 通过 Query2Doc 生成一段扩展文档: 提高深度学习模型的训练效率可以从以下几个方面入手: 1. 使用更高效的优化算法,如AdamW或LAMB。 2. 采用混合精度训练(Mixed Precision Training),减少显存占用并加速计算。 3. 使用分布式训练技术,如数据并行或模型并行。 4. 对数据进行预处理和增强,减少训练时的冗余计算。 5. 调整学习率调度策略,避免训练过程中的震荡。 **2. Doc2Query:为文档生成关联查询** - 文档内容: 本文介绍了深度学习模型训练中的优化技巧,包括: 1. 使用AdamW优化器替代传统的SGD。 2. 采用混合精度训练,减少显存占用。 3. 使用分布式训练技术加速大规模模型的训练…… - 通过 Doc2Query 生成一组可能的查询: 1. 如何选择深度学习模型的优化器? 2. 混合精度训练有哪些优势? 3. 分布式训练技术如何加速深度学习? 4. 如何减少深度学习训练中的显存占用? 5. 深度学习模型训练的最佳实践是什么? ### 3.5. 索引扩展 - **离散索引扩展:** 使用关键词抽取、实体识别等技术生成离散索引,与向量检索互补,提升召回准确性。 - **连续索引扩展:** 结合多种向量模型(如OpenAI的Ada、智源的BGE)进行多路召回,取长补短。 - **混合索引召回:** 将BM25等离散索引与向量索引结合,通过Ensemble Retriever实现混合召回,提升召回多样性 #### 3.5.1. 离散索引 使用关键词抽取、实体识别等技术生成离散索引,与向量检索互补,提升召回准确性。 **1. 关键词抽取:** 从文档中提取出重要的关键词,作为离散索引的一部分,用于补充向量检索的不足。 文档内容: <div style="background:#eee;padding:20px"> 本文介绍了深度学习模型训练中的优化技巧,包括:<br> 1. 使用AdamW优化器替代传统的SGD。<br> 2. 采用混合精度训练,减少显存占用。<br> 3. 使用分布式训练技术加速大规模模型的训练。 </div> 通过关键词抽取技术(如TF-IDF、TextRank)提取出以下关键词: <div style="background:#eee;padding:10px"> ["深度学习", "模型训练", "优化技巧", "AdamW", "混合精度训练", "分布式训练"] </div> <div class="alert alert-info"> 当用户查询“如何优化深度学习模型训练?”时,离散索引中的关键词能够快速匹配到相关文档。 </div> **2. 实体识别:** 从文档中识别出命名实体(如人名、地点、组织等),作为离散索引的一部分,增强检索的精确性。 文档内容: <div style="background:#eee;padding:10px"> 2023年诺贝尔物理学奖授予了三位科学家,以表彰他们在量子纠缠领域的研究成果。 </div> 通过实体识别技术(如SpaCy、BERT-based NER)提取出以下实体: <div style="background:#eee;padding:10px"> ["2023年", "诺贝尔物理学奖", "量子纠缠"] </div> <div class="alert alert-info"> 当用户查询“2023年诺贝尔物理学奖的获奖者是谁?”时,离散索引中的实体能够快速匹配到相关文档。 </div> #### 3.5.2. 混合索引召回 将离散索引(如关键词、实体)与向量索引结合,通过混合召回策略提升检索效果。 文档内容: <div style="background:#eee;padding:10px"> 本文介绍了人工智能在医疗领域的应用,包括:<br> 1. 使用深度学习技术进行医学影像分析。<br> 2. 利用自然语言处理技术提取电子病历中的关键信息。<br> 3. 开发智能诊断系统辅助医生决策。 </div> 关键词抽取:["人工智能", "医疗领域", "深度学习", "医学影像分析", "自然语言处理", "电子病历", "智能诊断系统"] 实体识别:["人工智能", "医疗领域", "深度学习", "自然语言处理"] <div class="alert alert-info"> 当用户查询“人工智能在医疗领域的应用有哪些?”时: 离散索引通过关键词和实体匹配到相关文档。 向量索引通过语义相似度匹配到相关文档。 综合两种召回结果,提升检索的准确性和覆盖率。 </div> #### 3.5.3. Small-to-Big **Small-to-Big 索引策略:** 一种高效的检索方法,特别适用于处理长文档或多文档场景。核心思想是通过小规模内容(如摘要、关键句或段落)建立索引,并链接到大规模内容主体中。这种策略的优势在于能够快速定位相关的小规模内容,并通过链接获取更详细的上下文信息,从而提高检索效率和答案的逻辑连贯性。 小规模内容(索引部分): 摘要:从每篇论文中提取摘要作为索引内容。 - 摘要1:本文介绍了Transformer 模型在机器翻译任务中的应用,并提出了改进的注意力机制。 - 摘要2:本文探讨了Transformer 模型在文本生成任务中的性能,并与RNN 模型进行了对比。 关键句:从论文中提取与查询相关的关键句。 - 关键句1:Transformer 模型通过自注意力机制实现了高效的并行计算。 - 关键句2:BERT 是基于Transformer 的预训练模型,在多项NLP 任务中取得了显著效果。 大规模内容(链接部分): 每篇论文的完整内容作为大规模内容,通过链接与小规模内容关联。 - 论文1:链接到完整的PDF 文档,包含详细的实验和结果。 - 论文2:链接到完整的PDF 文档,包含模型架构和性能分析。 **Small-to-Big机制:** **1. 小规模内容检索:** 用户输入查询后,系统首先在小规模内容(如摘要、关键句或段落)中检索匹配的内容。小规模内容通常是通过摘要生成、关键句提取等技术从大规模内容中提取的,并建立索引。 **2. 链接到大规模内容:** 当小规模内容匹配到用户的查询后,系统会通过预定义的链接(如文档ID、URL 或指针)找到对应的大规模内容(如完整的文档、文章)。大规模内容包含更详细的上下文信息,为RAG 提供丰富的背景知识。 **3. 上下文补充:** 将大规模内容作为RAG 系统的上下文输入,结合用户查询和小规模内容,生成更准确和连贯的答案。 **实现原理:** 1. **文档 -> 生成摘要(LLM + Prompt)** 原始文档文件夹 -> 向量数据库 faiss-1 摘要文档文件夹 -> 向量数据库 faiss-2 两者建立1v1对应关系 3. **Small-to-Big 检索策略** query -> faiss-2 -> faiss-1 ## 4. Qwen-Agent 构建 RAG ### 4.1. 基本介绍 Qwen-Agent是一个开发框架。充分利用基于通义千问模型(Qwen)的指令遵循、工具使用、规划、记忆能力。 Qwen-Agent支持的模型形式: - DashScope服务提供的Qwen模型服务 - 支持通过OpenAI API方式接入开源的Qwen模型服务 Github:https://github.com/QwenLM/Qwen-Agent ### 4.2. 构建智能体 Qwen-Agent构建的智能体包含三个复杂度级别,每一层都建立在前一层的基础上 #### 4.2.1. Level-1:检索 处理100万字上下文的一种朴素方法是简单采用增强检索生成(RAG)。 RAG将上下文分割成较短的块,每块不超过512个字,然后仅保留最相关的块在8k字的上下文中。 挑战在于如何精准定位最相关的块。经过多次尝试,我们提出了一种基于关键词的解决方案: - **步骤1:指导聊天模型将用户查询中的指令信息与非指令信息分开。** - 例如,将用户查询"回答时请用2000字详尽阐述,我的问题是,自行车是什么时候发明的?请用英文回复。"转化为{"信息": ["自行车是什么时候发明的"], "指令": ["回答时用2000字", "尽量详尽", "用英文回复"]}。 - **步骤2:要求聊天模型从查询的信息部分推导出多语言关键词。** - 例如,短语"自行车是什么时候发明的"会转换为{"关键词_英文": ["bicycles", "invented", "when"], "关键词_中文": ["自行车", "发明", "时间"]}。 - **步骤3:运用BM25这一传统的基于关键词的检索方法,找出与提取关键词最相关的块。** 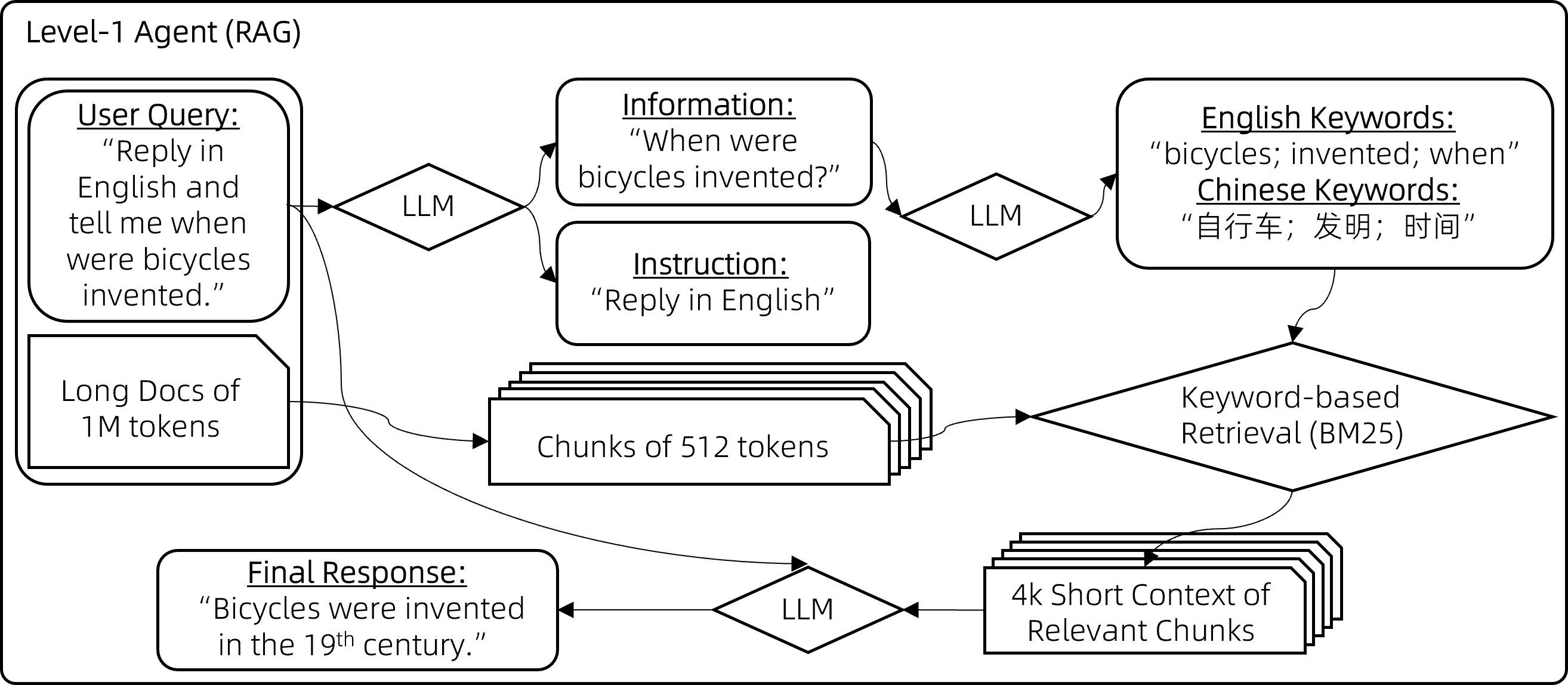 RAG CODE:https://github.com/QwenLM/Qwen-Agent/blob/main/examples/assistant_rag.py #### 4.2.2. Level-2:分块检索 上述RAG方法很快速,但常在相关块与用户查询关键词重叠程度不足时失效,导致这些相关的块未被检索到、没有提供给模型。尽管理论上向量检索可以缓解这一问题,但实际上效果有限。 为了解决这个局限,我们采用了一种暴力策略来减少错过相关上下文的几率: - **步骤1:对于每个512字块,让聊天模型评估其与用户查询的相关性,** 如果认为不相关则输出"无", 如果相关则输出相关句子。这些块会被并行处理以避免长时间等待。 - **步骤2:然后,取那些非"无"的输出(即相关句子),用它们作为搜索查询词,通过BM25检索出最相关的块** (总的检索结果长度控制在8k上下文限制内)。 - **步骤3:最后,基于检索到的上下文生成最终答案,** 这一步骤的实现方式与通常的RAG相同。 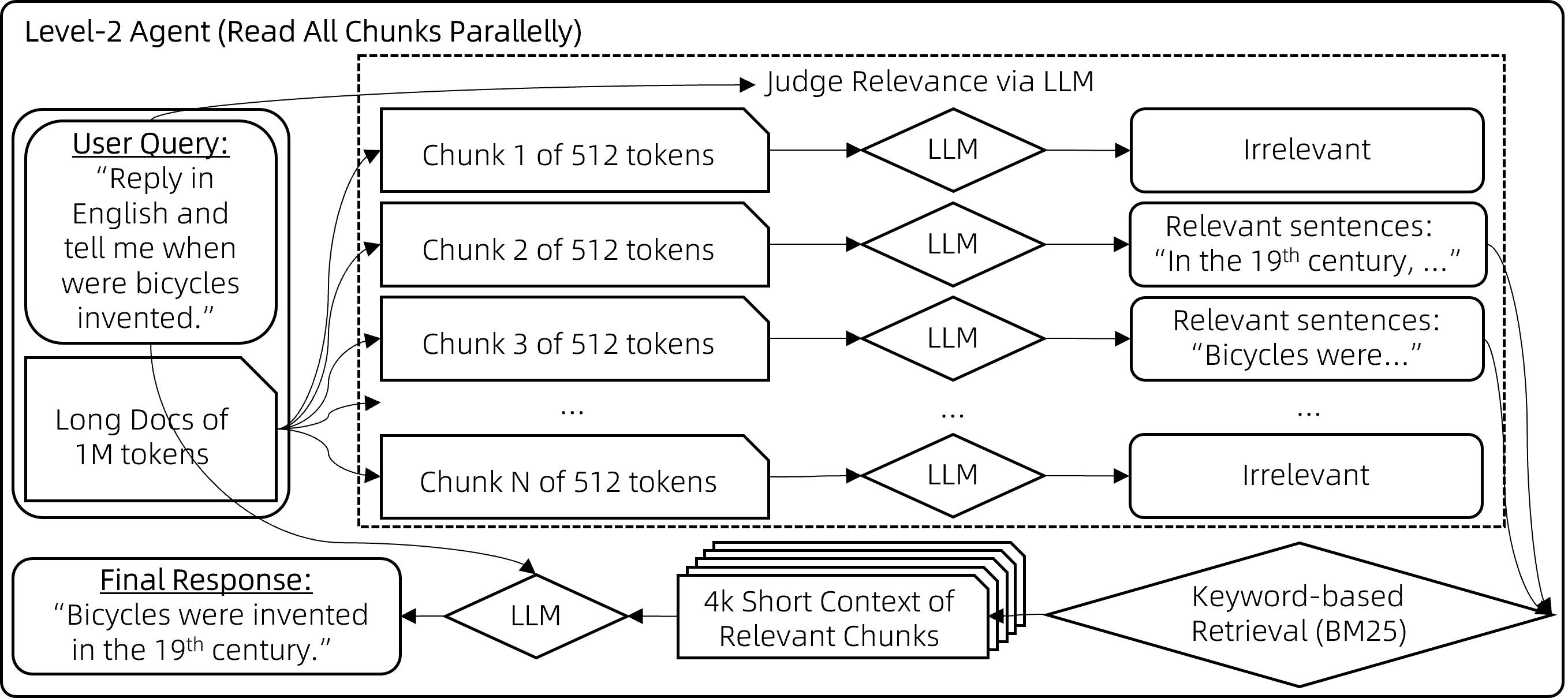 AGENT CODE:https://github.com/QwenLM/Qwen-Agent/blob/main/examples/parallel_doc_qa.py #### 4.2.3. Level-3:逐步推理 **在基于文档的问题回答中,一个典型的挑战是多跳推理。** - 例如,考虑回答问题:“与第五交响曲创作于同一世纪的交通工具是什么? - ”模型首先需要确定子问题的答案,“第五交响曲是在哪个世纪创作的?”即19世纪。 - 然后,它才可以意识到包含“自行车于19世纪发明”的信息块实际上与原始问题相关的。 工具调用(也称为函数调用)智能体或ReAct智能体是经典的解决方案,它们内置了问题分解和逐步推理的能力。因此,我们将前述级别二的智能体(Lv2-智能体)封装为一个工具,由工具调用智能体(Lv3-智能体)调用。工具调用智能体进行多跳推理的流程如下: <pre style="background:#eee;padding:20px"> 向Lv3-智能体提出一个问题。 while (Lv3-智能体无法根据其记忆回答问题) { Lv3-智能体提出一个新的子问题待解答。 Lv3-智能体向Lv2-智能体提问这个子问题。 将Lv2-智能体的回应添加到Lv3-智能体的记忆中。 } Lv3-智能体提供原始问题的最终答案。 </pre>  例如,Lv3-智能体最初向Lv2-智能体提出子问题:“贝多芬的第五交响曲是在哪个世纪创作的? - ”收到“19世纪”的回复后,Lv3-智能体提出新的子问题:“19世纪期间发明了什么交通工具?” - 通过整合Lv2-智能体的所有反馈,Lv3-智能体便能够回答原始问题:“与第五交响曲创作于同一世纪的交通工具是什么?” ### 4.3. RAG评测结果 我们在两个针对256k上下文设计的基准测试上进行了实验: - NeedleBench,一个测试模型是否能在充满大量无关句子的语境中找到最相关句子的基准,类似于“大海捞针”。回答一个问题可能需要同时找到多根“针”,并进行多跳逐步推理。 - LV-Eval是一个要求同时理解众多证据片段的基准测试。我们对LV-Eval原始版本中的评估指标进行了调整,因为其匹配规则过于严苛,导致了许多假阴性结果。 我们比较了以下方法: - 32k-模型:这是一个7B对话模型,主要在8k上下文样本上进行微调,并辅以少量32k上下文样本。为了扩展到256k上下文,我们采用了无需额外训练的方法,如基于RoPE的外推。 - 4k-RAG:使用与32k-模型相同的模型,但采取了Lv1-智能体的RAG策略。它仅检索并处理最相关的4k上下文。 - 4k-智能体:同样使用32k-模型的模型,但采用前文描述的更复杂的智能体策略。该智能体策略会并行处理多个片段,但每次请求模型时至多只使用模型的4k上下文。 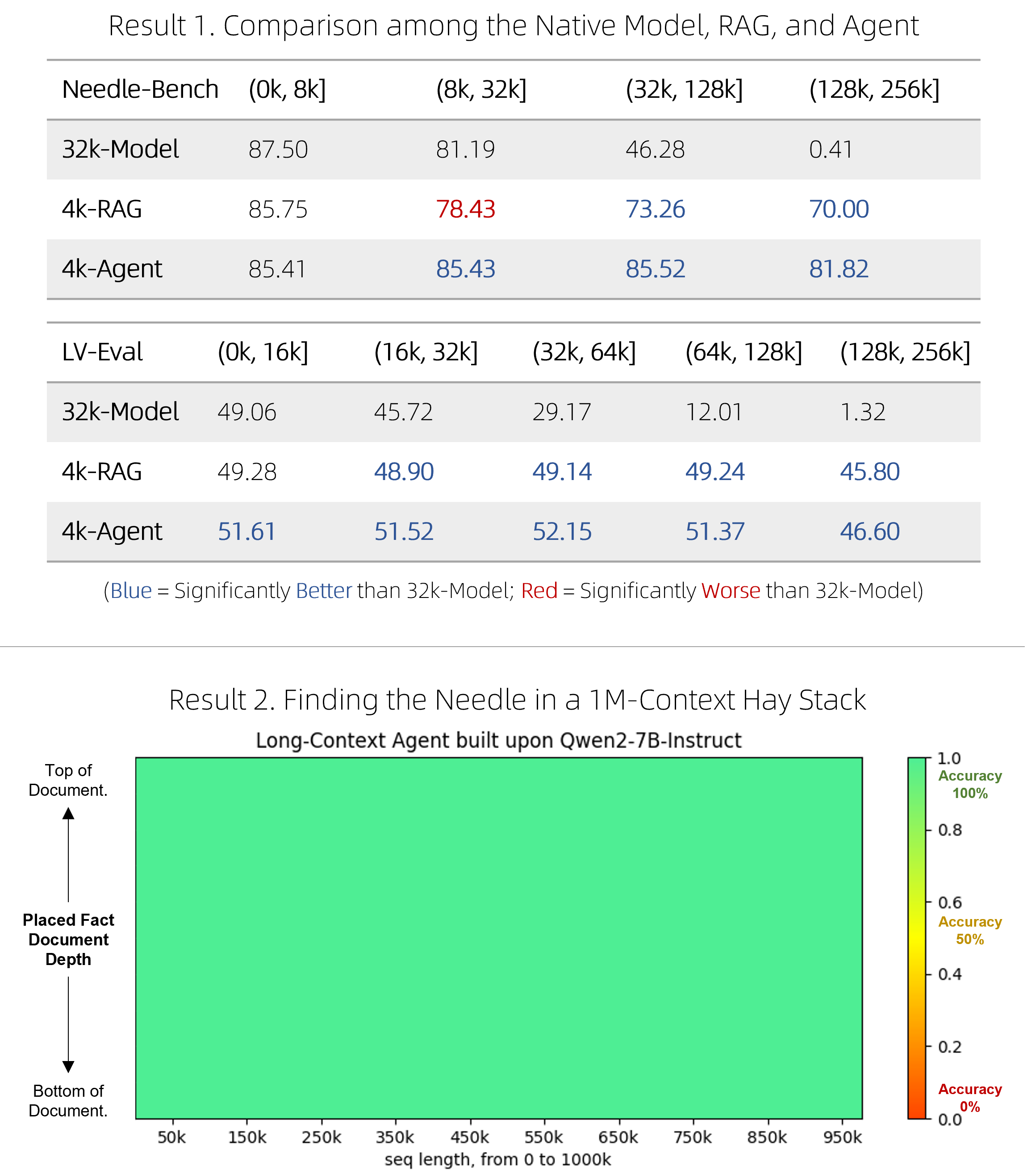 实验结果说明了以下几点: - 在短上下文场景中,4k-RAG的表现可能不如32k-模型。这可能是由于RAG方案难以检索到正确的信息或理解多个片段造成的。 - 相反,随着文档长度的增加,4k-RAG越发表现出超越32k-模型的趋势。这一趋势表明32k-模型在处理长上下文方面并没有训练到最优的状态。 - 值得注意的是,4k-智能体始终表现优于32k-模型和4k-RAG。它分块阅读所有上下文的方式使它能够避免原生模型在长上下文上训练不足而带来的限制。 总的来说,如果得到恰当的训练,32k-模型理应优于所有其他方案。然而,实际上由于训练不足,32k-模型的表现不及4k-智能体。 最后,我们还对该智能体进行了100万个字词的压力测试(在100万个字词的大海中寻找一根针),并发现它能够正常运行。 ### 4.4. Qwen-Agent 使用 ```python conda create -n qwen-agent python=3.11 ``` #### 4.4.1. 安装 ```python # 从 PyPI 安装稳定版本: # !pip install -U "qwen-agent[rag,code_interpreter,gui,mcp]" # 或者,使用 `pip install -U qwen-agent` 来安装最小依赖。 # 可使用双括号指定如下的可选依赖: # [gui] 用于提供基于 Gradio 的 GUI 支持; # [rag] 用于支持 RAG; # [code_interpreter] 用于提供代码解释器相关支持; # [mcp] 用于支持 MCP。 ``` #### 4.4.2. 快速开发 ```python import logging import io import os from qwen_agent.agents import Assistant # 创建一个自定义的日志处理器来捕获日志输出 class LogCapture: def __init__(self): self.log_capture_string = io.StringIO() self.log_handler = logging.StreamHandler(self.log_capture_string) self.log_handler.setLevel(logging.INFO) self.log_formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') self.log_handler.setFormatter(self.log_formatter) # 获取 qwen_agent 的日志记录器 self.logger = logging.getLogger('qwen_agent_logger') self.logger.setLevel(logging.INFO) self.logger.addHandler(self.log_handler) # 也可以捕获根日志记录器的输出 self.root_logger = logging.getLogger() self.root_logger.setLevel(logging.INFO) self.root_logger.addHandler(self.log_handler) def get_log(self): return self.log_capture_string.getvalue() def clear_log(self): self.log_capture_string.truncate(0) self.log_capture_string.seek(0) # 初始化日志捕获器 log_capture = LogCapture() # 步骤 1:配置您所使用的 LLM。 llm_cfg = { # 使用 DashScope 提供的模型服务: 'model': 'qwen-max', 'model_server': 'dashscope', 'api_key': os.getenv("DASHSCOPE_API_KEY"), 'generate_cfg': { 'top_p': 0.8 } } # 步骤 2:创建一个智能体。这里我们以 `Assistant` 智能体为例,它能够使用工具并读取文件。 system_instruction = '' tools = [] files = ['./浦发上海浦东发展银行西安分行个金客户经理考核办法.pdf'] # 给智能体一个 PDF 文件阅读。 # 清除之前的日志 log_capture.clear_log() # 创建智能体 bot = Assistant(llm=llm_cfg, system_message=system_instruction, function_list=tools, files=files) # 步骤 3:作为聊天机器人运行智能体。 messages = [] # 这里储存聊天历史。 query = "客户经理被客户投诉一次,扣多少分?" # 将用户请求添加到聊天历史。 messages.append({'role': 'user', 'content': query}) response = [] current_index = 0 # 运行智能体 for response in bot.run(messages=messages): # 在第一次响应时,分析日志以查找召回的文档内容 if current_index == 0: # 获取日志内容 log_content = log_capture.get_log() print("\n===== 从日志中提取的检索信息 =====") # 查找与检索相关的日志行 retrieval_logs = [line for line in log_content.split('\n') if any(keyword in line.lower() for keyword in ['retriev', 'search', 'chunk', 'document', 'ref', 'token'])] # 打印检索相关的日志 for log_line in retrieval_logs: print(log_line) # 尝试从日志中提取文档内容 # 通常在日志中会有类似 "retrieved document: ..." 或 "content: ..." 的行 content_logs = [line for line in log_content.split('\n') if any(keyword in line.lower() for keyword in ['content', 'text', 'document', 'chunk'])] print("\n===== 可能包含文档内容的日志 =====") for log_line in content_logs: print(log_line) print("===========================\n") current_response = response[0]['content'][current_index:] current_index = len(response[0]['content']) print(current_response, end='') # 将机器人的回应添加到聊天历史。 messages.extend(response) # 运行结束后,分析完整的日志 print("\n\n===== 运行结束后的完整日志分析 =====") log_content = log_capture.get_log() # 尝试从日志中提取更多信息 print("\n1. 关键词提取:") keyword_logs = [line for line in log_content.split('\n') if 'keywords' in line.lower()] for log_line in keyword_logs: print(log_line) print("\n2. 文档处理:") doc_logs = [line for line in log_content.split('\n') if 'doc' in line.lower() or 'chunk' in line.lower()] for log_line in doc_logs: print(log_line) print("\n3. 检索相关:") retrieval_logs = [line for line in log_content.split('\n') if 'retriev' in line.lower() or 'search' in line.lower() or 'ref' in line.lower()] for log_line in retrieval_logs: print(log_line) print("\n4. 可能包含文档内容的日志:") content_logs = [line for line in log_content.split('\n') if 'content:' in line.lower() or 'text:' in line.lower()] for log_line in content_logs: print(log_line) print("===========================\n") ``` ```python 2025-05-16 21:02:09,654 - memory.py - 116 - INFO - {"keywords_zh": ["客户经理", "投诉", "扣分"], "keywords_en": ["account manager", "complaint", "deduct points", "penalty"], "text": "客户经理被客户投诉一次,扣多少分?"} 2025-05-16 21:02:10,410 - simple_doc_parser.py - 411 - INFO - Read parsed ./浦发上海浦东发展银行西安分行个金客户经理考核办法.pdf from cache. 2025-05-16 21:02:10,411 - doc_parser.py - 108 - INFO - Start chunking ./浦发上海浦东发展银行西安分行个金客户经理考核办法.pdf (浦发上海浦东发展银行西安分行个金客户经理考核办法.pdf)... 2025-05-16 21:02:10,412 - doc_parser.py - 126 - INFO - Finished chunking ./浦发上海浦东发展银行西安分行个金客户经理考核办法.pdf (浦发上海浦东发展银行西安分行个金客户经理考核办法.pdf). Time spent: 0.0 seconds. 2025-05-16 21:02:10,413 - base_search.py - 56 - INFO - all tokens: 2933 2025-05-16 21:02:10,414 - base_search.py - 59 - INFO - use full ref ===== 从日志中提取的检索信息 ===== 2025-05-16 21:02:10,411 - qwen_agent_logger - INFO - Start chunking ./浦发上海浦东发展银行西安分行个金客户经理考核办法.pdf (浦发上海浦东发展银行西安分行个金客户经理考核办法.pdf)... 2025-05-16 21:02:10,411 - qwen_agent_logger - INFO - Start chunking ./浦发上海浦东发展银行西安分行个金客户经理考核办法.pdf (浦发上海浦东发展银行西安分行个金客户经理考核办法.pdf)... 2025-05-16 21:02:10,412 - qwen_agent_logger - INFO - Finished chunking ./浦发上海浦东发展银行西安分行个金客户经理考核办法.pdf (浦发上海浦东发展银行西安分行个金客户经理考核办法.pdf). Time spent: 0.0 seconds. 2025-05-16 21:02:10,412 - qwen_agent_logger - INFO - Finished chunking ./浦发上海浦东发展银行西安分行个金客户经理考核办法.pdf (浦发上海浦东发展银行西安分行个金客户经理考核办法.pdf). Time spent: 0.0 seconds. 2025-05-16 21:02:10,413 - qwen_agent_logger - INFO - all tokens: 2933 2025-05-16 21:02:10,413 - qwen_agent_logger - INFO - all tokens: 2933 2025-05-16 21:02:10,414 - qwen_agent_logger - INFO - use full ref 2025-05-16 21:02:10,414 - qwen_agent_logger - INFO - use full ref ===== 可能包含文档内容的日志 ===== 2025-05-16 21:02:09,654 - qwen_agent_logger - INFO - {"keywords_zh": ["客户经理", "投诉", "扣分"], "keywords_en": ["account manager", "complaint", "deduct points", "penalty"], "text": "客户经理被客户投诉一次,扣多少分?"} 2025-05-16 21:02:09,654 - qwen_agent_logger - INFO - {"keywords_zh": ["客户经理", "投诉", "扣分"], "keywords_en": ["account manager", "complaint", "deduct points", "penalty"], "text": "客户经理被客户投诉一次,扣多少分?"} 2025-05-16 21:02:10,411 - qwen_agent_logger - INFO - Start chunking ./浦发上海浦东发展银行西安分行个金客户经理考核办法.pdf (浦发上海浦东发展银行西安分行个金客户经理考核办法.pdf)... 2025-05-16 21:02:10,411 - qwen_agent_logger - INFO - Start chunking ./浦发上海浦东发展银行西安分行个金客户经理考核办法.pdf (浦发上海浦东发展银行西安分行个金客户经理考核办法.pdf)... 2025-05-16 21:02:10,412 - qwen_agent_logger - INFO - Finished chunking ./浦发上海浦东发展银行西安分行个金客户经理考核办法.pdf (浦发上海浦东发展银行西安分行个金客户经理考核办法.pdf). Time spent: 0.0 seconds. 2025-05-16 21:02:10,412 - qwen_agent_logger - INFO - Finished chunking ./浦发上海浦东发展银行西安分行个金客户经理考核办法.pdf (浦发上海浦东发展银行西安分行个金客户经理考核办法.pdf). Time spent: 0.0 seconds. =========================== 客户经理被客户投诉一次,扣2分。 ===== 运行结束后的完整日志分析 ===== 1. 关键词提取: 2025-05-16 21:02:09,654 - qwen_agent_logger - INFO - {"keywords_zh": ["客户经理", "投诉", "扣分"], "keywords_en": ["account manager", "complaint", "deduct points", "penalty"], "text": "客户经理被客户投诉一次,扣多少分?"} 2025-05-16 21:02:09,654 - qwen_agent_logger - INFO - {"keywords_zh": ["客户经理", "投诉", "扣分"], "keywords_en": ["account manager", "complaint", "deduct points", "penalty"], "text": "客户经理被客户投诉一次,扣多少分?"} 2. 文档处理: 2025-05-16 21:02:10,411 - qwen_agent_logger - INFO - Start chunking ./浦发上海浦东发展银行西安分行个金客户经理考核办法.pdf (浦发上海浦东发展银行西安分行个金客户经理考核办法.pdf)... 2025-05-16 21:02:10,411 - qwen_agent_logger - INFO - Start chunking ./浦发上海浦东发展银行西安分行个金客户经理考核办法.pdf (浦发上海浦东发展银行西安分行个金客户经理考核办法.pdf)... 2025-05-16 21:02:10,412 - qwen_agent_logger - INFO - Finished chunking ./浦发上海浦东发展银行西安分行个金客户经理考核办法.pdf (浦发上海浦东发展银行西安分行个金客户经理考核办法.pdf). Time spent: 0.0 seconds. 2025-05-16 21:02:10,412 - qwen_agent_logger - INFO - Finished chunking ./浦发上海浦东发展银行西安分行个金客户经理考核办法.pdf (浦发上海浦东发展银行西安分行个金客户经理考核办法.pdf). Time spent: 0.0 seconds. 3. 检索相关: 2025-05-16 21:02:10,414 - qwen_agent_logger - INFO - use full ref 2025-05-16 21:02:10,414 - qwen_agent_logger - INFO - use full ref 4. 可能包含文档内容的日志: =========================== ``` ```python # RAG助手 import os def get_file_list(folder_path): # 初始化文件列表 file_list = [] # 遍历文件夹 for root, dirs, files in os.walk(folder_path): for file in files: # 获取文件的完整路径 file_path = os.path.join(root, file) # 将文件路径添加到列表中 file_list.append(file_path) return file_list # 获取指定知识库文件列表 file_list = get_file_list('./docs') file_list ``` ```python ['./docs\\1-平安商业综合责任保险(亚马逊).txt', './docs\\2-雇主责任险.txt', './docs\\3-平安企业团体综合意外险.txt', './docs\\4-雇主安心保.txt', './docs\\5-施工保.txt', './docs\\6-财产一切险.txt', './docs\\7-平安装修保.txt'] ``` ```python from qwen_agent.agents import Assistant # 步骤 1:配置您所使用的 LLM llm_cfg = { # 使用 DashScope 提供的模型服务: 'model': 'qwen-max', 'model_server': 'dashscope', 'api_key': os.getenv('DASHSCOPE_API_KEY'), # 如果这里没有设置 'api_key',它将读取 `DASHSCOPE_API_KEY` 环境变量。 # 使用与 OpenAI API 兼容的模型服务,例如 vLLM 或 Ollama: # 'model': 'Qwen2-7B-Chat', # 'model_server': 'http://localhost:8000/v1', # base_url,也称为 api_base # 'api_key': 'EMPTY', # (可选) LLM 的超参数: 'generate_cfg': { 'top_p': 0.8 } } # 步骤 2:创建一个智能体。这里我们以 `Assistant` 智能体为例,它能够使用工具并读取文件。 system_instruction = '你是一位保险专家,根据你的经验来精准的回答用户提出的问题' tools = [] bot = Assistant(llm=llm_cfg, system_message=system_instruction, function_list=tools, files=file_list) # 步骤 3:作为聊天机器人运行智能体。 messages = [] # 这里储存聊天历史。 while True: query = input('用户请求: ') if query == '-1': break # 将用户请求添加到聊天历史。 messages.append({'role': 'user', 'content': query}) response = [] current_index = 0 for response in bot.run(messages=messages): # 流式输出 current_response = response[0]['content'][current_index:] current_index = len(response[0]['content']) print(current_response, end='') # 将机器人的回应添加到聊天历史。 messages.extend(response) ``` ```python 2025-05-16 21:07:00,312 - memory.py - 116 - INFO - {"keywords_zh": ["雇主责任险", "解释", "定义"], "keywords_en": ["Employer's Liability Insurance", "explain", "definition"], "text": "请详细解释什么是雇主责任险"} 2025-05-16 21:07:00,322 - simple_doc_parser.py - 411 - INFO - Read parsed ./docs\1-平安商业综合责任保险(亚马逊).txt from cache. 2025-05-16 21:07:00,323 - doc_parser.py - 108 - INFO - Start chunking ./docs\1-平安商业综合责任保险(亚马逊).txt (1-平安商业综合责任保险(亚马逊).txt)... 2025-05-16 21:07:00,323 - doc_parser.py - 126 - INFO - Finished chunking ./docs\1-平安商业综合责任保险(亚马逊).txt (1-平安商业综合责任保险(亚马逊).txt). Time spent: 0.0 seconds. 2025-05-16 21:07:00,336 - simple_doc_parser.py - 411 - INFO - Read parsed ./docs\2-雇主责任险.txt from cache. 2025-05-16 21:07:00,337 - doc_parser.py - 108 - INFO - Start chunking ./docs\2-雇主责任险.txt (2-雇主责任险.txt)... 2025-05-16 21:07:00,338 - doc_parser.py - 126 - INFO - Finished chunking ./docs\2-雇主责任险.txt (2-雇主责任险.txt). Time spent: 0.0 seconds. 2025-05-16 21:07:00,351 - simple_doc_parser.py - 411 - INFO - Read parsed ./docs\3-平安企业团体综合意外险.txt from cache. 2025-05-16 21:07:00,352 - doc_parser.py - 108 - INFO - Start chunking ./docs\3-平安企业团体综合意外险.txt (3-平安企业团体综合意外险.txt)... 2025-05-16 21:07:00,353 - doc_parser.py - 126 - INFO - Finished chunking ./docs\3-平安企业团体综合意外险.txt (3-平安企业团体综合意外险.txt). Time spent: 0.001001119613647461 seconds. 2025-05-16 21:07:00,361 - simple_doc_parser.py - 411 - INFO - Read parsed ./docs\4-雇主安心保.txt from cache. 2025-05-16 21:07:00,362 - doc_parser.py - 108 - INFO - Start chunking ./docs\4-雇主安心保.txt (4-雇主安心保.txt)... 2025-05-16 21:07:00,363 - doc_parser.py - 126 - INFO - Finished chunking ./docs\4-雇主安心保.txt (4-雇主安心保.txt). Time spent: 0.0 seconds. 2025-05-16 21:07:00,375 - simple_doc_parser.py - 411 - INFO - Read parsed ./docs\5-施工保.txt from cache. 2025-05-16 21:07:00,376 - doc_parser.py - 108 - INFO - Start chunking ./docs\5-施工保.txt (5-施工保.txt)... 2025-05-16 21:07:00,376 - doc_parser.py - 126 - INFO - Finished chunking ./docs\5-施工保.txt (5-施工保.txt). Time spent: 0.0 seconds. 2025-05-16 21:07:00,387 - simple_doc_parser.py - 411 - INFO - Read parsed ./docs\6-财产一切险.txt from cache. 2025-05-16 21:07:00,388 - doc_parser.py - 108 - INFO - Start chunking ./docs\6-财产一切险.txt (6-财产一切险.txt)... 2025-05-16 21:07:00,389 - doc_parser.py - 126 - INFO - Finished chunking ./docs\6-财产一切险.txt (6-财产一切险.txt). Time spent: 0.0 seconds. 2025-05-16 21:07:00,399 - simple_doc_parser.py - 411 - INFO - Read parsed ./docs\7-平安装修保.txt from cache. 2025-05-16 21:07:00,400 - doc_parser.py - 108 - INFO - Start chunking ./docs\7-平安装修保.txt (7-平安装修保.txt)... 2025-05-16 21:07:00,400 - doc_parser.py - 126 - INFO - Finished chunking ./docs\7-平安装修保.txt (7-平安装修保.txt). Time spent: 0.0 seconds. 2025-05-16 21:07:00,402 - base_search.py - 56 - INFO - all tokens: 6063 2025-05-16 21:07:00,402 - base_search.py - 59 - INFO - use full ref 雇主责任险是一种保险产品,旨在为企业提供对员工在工作过程中因意外事故或职业病导致的伤亡、伤残或疾病所产生的赔偿责任保障。以下是关于雇主责任险的详细解释: 1. **保障范围**: - 死亡赔偿金:如果雇员因工死亡,保险公司将支付相应的死亡赔偿金。 - 伤残赔偿金:如果雇员因工受伤并导致伤残,保险公司将根据伤残程度支付赔偿金。 - 医疗费用:覆盖雇员因工受伤或患职业病所需的医疗费用。 - 误工费用(C款不赔):部分方案会涵盖因工受伤导致无法工作的误工费用。 - 法律诉讼费(C款不赔):某些方案还可能包括因工伤引起的法律诉讼费用。 2. **其他亮点**: - **风险转嫁**:企业通过购买雇主责任险可以将对员工的风险责任转嫁给保险公司,减轻企业在面对员工工伤时的经济负担。 - **降低用工风险**:帮助企业减少因员工工伤引发的财务和法律风险。 - **减少工伤纠纷**:有助于快速处理工伤事件,减少企业和员工之间的纠纷。 - **提高员工保障福利**:为员工提供更全面的保障,提升员工的安全感和满意度。 - **税前列支**:雇主责任险的保费可以在企业所得税前扣除,从而节省一部分税收支出。 3. **适用对象**: - 凡是有用工需求的单位都可以购买雇主责任险,不论其规模大小或行业类型。 4. **与团体意外伤害保险的区别**: - 雇主责任险符合国家法律法规要求,而团体意外伤害保险主要体现的是企业对雇员的福利,并没有相关法律依据支持。 - 如果雇主仅通过意外险给予赔偿,雇员仍可以通过法律手段要求雇主继续给予赔偿;但雇主责任险则可以避免这种情况。 - 雇主责任险可以承保职业性疾病以及误工费用,而团体意外伤害保险通常不包含这些内容。 5. **与工伤保险的区别**: - 工伤保险基金虽然可以承担大部分工伤保险待遇,但仍有部分需要用人单位自身承担,如停工留薪期间的工资福利待遇等。 - 而雇主责任险不受劳动安全记录的影响,理赔程序也相对简单快捷。 6. **决定保费的因素**: - 客户的行业类型 - 雇员工种 - 赔偿限额 - 投保人数 综上所述,雇主责任险是企业为保护自身利益和员工权益的重要工具,能够有效减轻企业在面对员工工伤时的经济压力和法律责任。 ``` ## 5. RAG质量评估 当我们完成了一个RAG系统的开发工作以后,我们还需要对RAG系统的性能进行评估,那如何来对RAG系统的性能进行评估呢?我们可以仔细分析一下RAG系统的产出成果,比如检索器组件它产出的是检索出来的相关文档即context, 而生成器组件它产出的是最终的答案即answer,除此之外还有我们最初的用户问题即question。因此RAG系统的评估应该是将question、context、answer结合在一起进行评估。 ### 5.1. RAG 三元组 标准的 RAG 流程就是用户提出 Query 问题,RAG 应用去召回 Context,然后 LLM 将 Context 组装,生成满足 Query 的 Response 回答。那么在这里出现的三元组:—— Query、Context 和 Response 就是 RAG 整个过程中最重要的三元组,它们之间两两相互牵制。我们可以通过检测三元组之间两两元素的相关度,来评估这个 RAG 应用的效果: - **Context Relevance:** 衡量召回的 Context 能够支持 Query 的程度。如果该得分低,反应出了召回了太多与Query 问题无关的内容,这些错误的召回知识会对 LLM 的最终回答造成一定影响。 - **Groundedness:** 衡量 LLM 的 Response 遵从召回的 Context 的程度。如果该得分低,反应出了 LLM 的回答不遵从召回的知识,那么回答出现幻觉的可能就越大。 - **Answer Relevance:** 衡量最终的 Response 回答对 Query 提问的相关度。如果该得分低,反应出了可能答不对题。 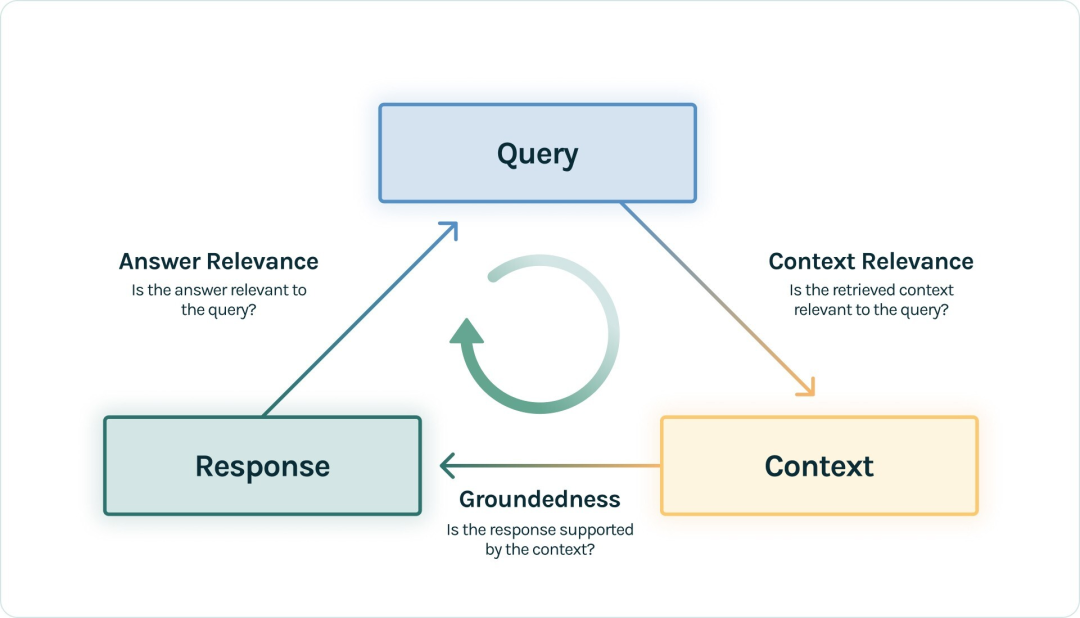 ### 5.2. Ragas评估 #### 5.2.1. 什么是RAGAs评估 官网地址:https://www.ragas.io/ Ragas (Retrieval-Augmented Generation Assessment) 它是一个框架,它可以帮助我们来快速评估RAG系统的性能,为了评估RAG系统,Ragas需要以下信息: - question:用户输入的问题。 - answer:从 RAG 系统生成的答案(由LLM给出)。 - contexts:根据用户的问题从外部知识源检索的上下文即与问题相关的文档。 - ground_truths: 人类提供的基于问题的真实(正确)答案。 这是唯一的需要人类提供的信息。 #### 5.2.2. 评估指标 Ragas提供了五种评估指标包括: - 忠实度(faithfulness) - 答案相关性(Answer relevancy) - 上下文精度(Context precision) - 上下文召回率(Context recall) - 上下文相关性(Context relevancy) **1. 忠实度(faithfulness)** 忠实度(faithfulness)衡量了生成的答案(answer)与给定上下文(context)的事实一致性。它是根据answer和检索到的context计算得出的。并将计算结果缩放到 (0,1) 范围且越高越好。 如果答案(answer)中提出的所有基本事实(claims)都可以从给定的上下文(context)中推断出来,则生成的答案被认为是忠实的。为了计算这一点,首先从生成的答案中识别一组claims。然后,将这些claims中的每一项与给定的context进行交叉检查,以确定是否可以从给定的context中推断出它。忠实度分数由以下公式得出: 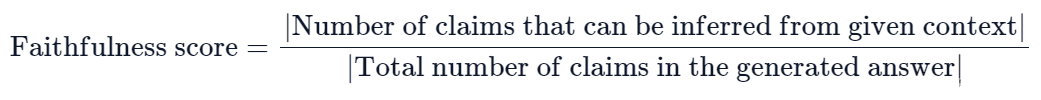 示例:  **2. 答案相关性(Answer relevancy)** 评估指标“答案相关性”重点评估生成的答案(answer)与用户问题(question)之间相关程度。不完整或包含冗余信息的答案将获得较低分数。该指标是通过计算question和answer获得的,它的取值范围在 0 到 1 之间,其中分数越高表示相关性越好。 当答案直接且适当地解决原始问题时,该答案被视为相关。重要的是,我们对答案相关性的评估不考虑真实情况,而是对答案缺乏完整性或包含冗余细节的情况进行惩罚。为了计算这个分数,LLM会被提示多次为生成的答案生成适当的问题,并测量这些生成的问题与原始问题之间的平均余弦相似度。基本思想是,如果生成的答案准确地解决了最初的问题,LLM应该能够从答案中生成与原始问题相符的问题。 示例:  **3. 上下文精度(Context precision)** 上下文精度是一种衡量标准,它评估所有在上下文(contexts)中呈现的与基本事实(ground-truth)相关的条目是否排名较高。理想情况下,所有相关文档块(chunks)必须出现在顶层。该指标使用question和计算contexts,值范围在 0 到 1 之间,其中分数越高表示精度越高。  **4. 上下文召回率(Context recall)** 上下文召回率(Context recall)衡量检索到的上下文(Context)与人类提供的真实答案(ground truth)的一致程度。它是根据ground truth和检索到的Context计算出来的,取值范围在 0 到 1 之间,值越高表示性能越好。 为了根据真实答案(ground truth)估算上下文召回率(Context recall),分析真实答案中的每个句子以确定它是否可以归因于检索到的Context。 在理想情况下,真实答案中的所有句子都应归因于检索到的Context。 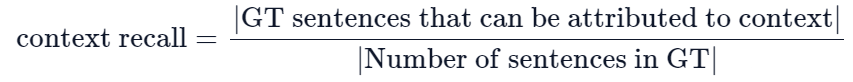 示例:  **5. 上下文相关性(Context relevancy)** 该指标衡量检索到的上下文(Context)的相关性,根据用户问题(question)和上下文(Context)计算得到,并且取值范围在 (0, 1)之间,值越高表示相关性越好。理想情况下,检索到的Context应只包含解答question的信息。 我们首先通过识别检索到的Context中与回答question相关的句子数量来估计 |S| 的值。 最终分数由以下公式确定: 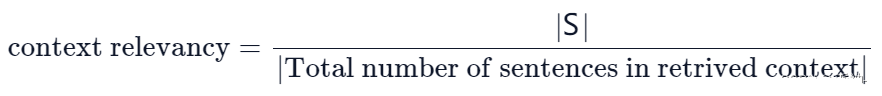 说明:这里的|S|是指Context中存在的与解答question相关的句子数量。 示例:  ### 5.3. Ragas评估实操 #### 5.3.1. 父文档检索器 文档切割时传统的做法是使用像CharacterTextSplitter, RecursiveCharacterTextSplitter这样的文档分割器将文档按指定的块大小(chunk_size)来均匀的切割文档,然后将每个文档块做向量化处理(Embedding)后将其保存到向量数据库中,而当我们在做文档检索时,会将用户的问题转换成的向量与向量数据库中的文档块的向量做相似度计算,并从中获取k个与用户问题向量相似度最高的文档块(也就是和用户问题相关的文档块),然后我们会把用户的问题以及相关的文档块一起发送给LLM, 最后LLM会给出一个对用户友好的回复。这就是一般的传统文档检索的方法。 传统检索方法其实存在一定的局限性,这是因为文档块的大小会影响和用户问题的匹配度,也就是说当我们切割的文档块越大时,它与用户问题的匹配度就会越低,当文档块越小时,它与用户问题的匹配度会越高,这是因为较大的文档块可能会包含较多的内容,当它被转换成一个固定维度的向量时,该向量可能不能够准确反应出该文档块中的所有内容,因而对用户问题的匹配度就会降低,而小的文档块包含的内容较少,当它被转换成一个固定维度的向量时,该向量基本能够准确反应出该文档块中的内容,因此它与用户问题的匹配度会教高,但是较小的文档块可能因为所包含的信息量较少,因而它可能不是一个全面且正确的答案。为了解决这些问题今天来介绍Langchain中的父文档检索器,它能够有效的解决文档块大小与用户问题匹配的问题。 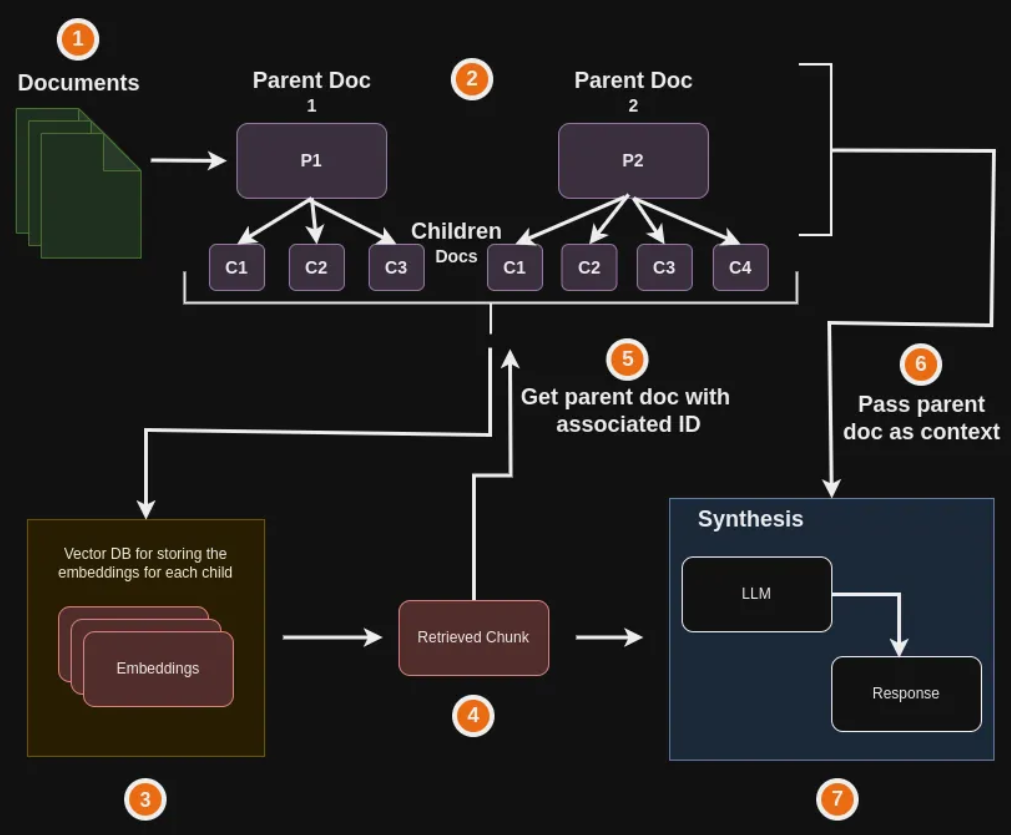 由于我们在利用大模型进行文档检索的时候,常常会有相互矛盾的需求,比如: - 希望得到较小的文档块,以便它们Embedding以后能够最准确地反映出文档的含义,如果文档块太大,Embedding就失去了意义。 - 希望得到较大的文档块以保留教多的内容,然后将它们发送给LLM以便得到全面且正确的答案。 面对这样矛盾的需求,Langchain的父文档检索器为我们提供了两种有效的解决方案: - 检索完整文档 - 检索较大的文档块 #### 5.3.2. 检索完整文档 所谓检索完整文档是指将原始文档均匀的切割成若干个较小的文档块,然后将它们与用户的问题进行匹配,最后将匹配到的文档块所在原始文档和用户问题一起发送给llm后由llm生成最终答案,如下图所示: 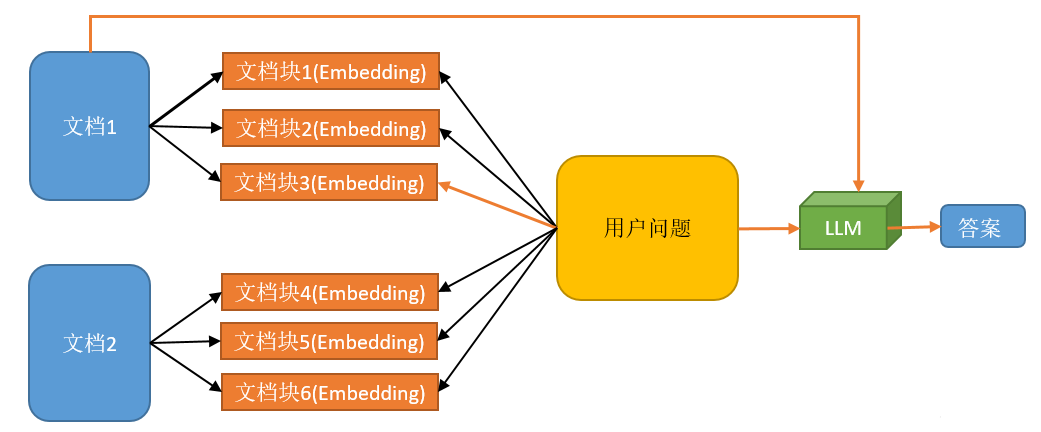 #### 5.3.3. 检索较大的文档块 当原始文档比较大时,我们需要将原始文档按照两个层级进行切割,即切割成主文档块和子文档块,而用户的问题会与所有的子文档块进行匹配(相似度比较) ,当匹配到特定的子文档块后,将该子文档块所属的主文档块的全部内容以及用户问题发送给llm,最后由llm来生成答案。 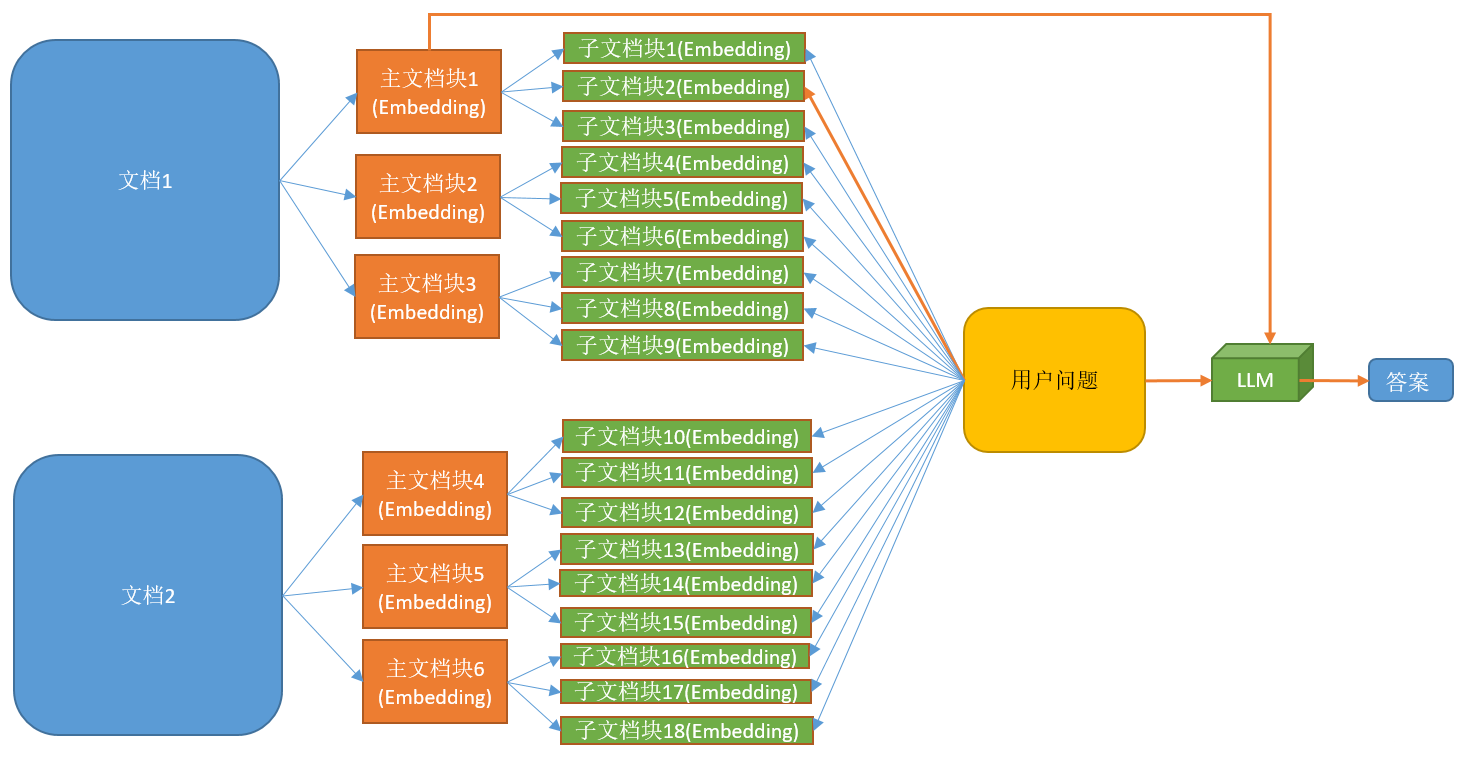 ```python # !pip install pypdf # !pip install ragas # !pip install Pillow # !pip install dashscope # !pip install chromadb # !pip install langchain # !pip install langchain-chroma ``` ```python from langchain_community.document_loaders import PyPDFLoader docs = PyPDFLoader("./浦发上海浦东发展银行西安分行个金客户经理考核办法.pdf").load() docs ``` ```python [Document(metadata={'producer': 'Microsoft® Word 2019', 'creator': 'Microsoft® Word 2019', 'creationdate': '2023-05-06T22:46:33+08:00', 'author': 'Chen Yang', 'moddate': '2023-05-06T22:46:33+08:00', 'source': './浦发上海浦东发展银行西安分行个金客户经理考核办法.pdf', 'total_pages': 9, 'page': 0, 'page_label': '1'}, page_content='百度文库 - 好好学习,天天向上 \n-1 \n上海浦东发展银行西安分行 \n个金客户经理管理考核暂行办法 \n \n \n第一章 总 则 \n第一条 为保证我分行个金客户经理制的顺利实施,有效调动个\n金客户经理的积极性, 促进个金业务快速、 稳定地发展, 根据总行 《上\n海浦东发展银行个人金融营销体系建设方案(试行)》要求,特制定\n《上海浦东发展银行西安分行个金客户经理管理考核暂行办法(试\n行)》(以下简称本办法)。 \n第二条 个金客户经理系指各支行(营业部)从事个人金融产品\n营销与市场开拓,为我行个人客户提供综合银行服务的我行市场人\n员。 \n第三条 考核内容分为二大类, 即个人业绩考核、 工作质量考核。\n个人业绩包括个人资产业务、负债业务、卡业务。工作质量指个人业\n务的资产质量。 \n第四条 为规范激励规则,客户经理的技术职务和薪资实行每年\n考核浮动。客户经理的奖金实行每季度考核浮动,即客户经理按其考\n核内容得分与行员等级结合,享受对应的行员等级待遇。'), Document(metadata={'producer': 'Microsoft® Word 2019', 'creator': 'Microsoft® Word 2019', 'creationdate': '2023-05-06T22:46:33+08:00', 'author': 'Chen Yang', 'moddate': '2023-05-06T22:46:33+08:00', 'source': './浦发上海浦东发展银行西安分行个金客户经理考核办法.pdf', 'total_pages': 9, 'page': 1, 'page_label': '2'}, page_content='百度文库 - 好好学习,天天向上 \n-2 \n第二章 职位设置与职责 \n第五条 个金客户经理职位设置为:客户经理助理、客户经理、\n高级客户经理、资深客户经理。 \n第六条 个金客户经理的基本职责: \n(一) 客户开发。研究客户信息、联系与选择客户、与客户建\n立相互依存、相互支持的业务往来关系,扩大业务资源,创造良好业\n绩; \n(二)业务创新与产品营销。把握市场竞争变化方向,开展市场\n与客户需求的调研,对业务产品及服务进行创新;设计客户需求的产\n品组合、制订和实施市场营销方案; \n(三)客户服务。负责我行各类表内外授信业务及中间业务的受\n理和运作,进行综合性、整体性的客户服务; \n(四)防范风险,提高收益。提升风险防范意识及能力,提高经\n营产品质量; \n(五)培养人材。在提高自身综合素质的同时,发扬团队精神,\n培养后备业务骨干。'), Document(metadata={'producer': 'Microsoft® Word 2019', 'creator': 'Microsoft® Word 2019', 'creationdate': '2023-05-06T22:46:33+08:00', 'author': 'Chen Yang', 'moddate': '2023-05-06T22:46:33+08:00', 'source': './浦发上海浦东发展银行西安分行个金客户经理考核办法.pdf', 'total_pages': 9, 'page': 2, 'page_label': '3'}, page_content='百度文库 - 好好学习,天天向上 \n-3 \n第三章 基础素质要求 \n第七条 个金客户经理准入条件: \n(一)工作经历:须具备大专以上学历,至少二年以上银行工作\n经验。 \n(二)工作能力:熟悉我行的各项业务,了解市场情况,熟悉各\n类客户的金融需求,熟悉个人理财工具,有一定的业务管理和客户管\n理能力。 \n(三)工作业绩:个金客户经理均应达到相应等级的准入标准。\n该标准可根据全行整体情况由考核部门进行调整。 \n(四)专业培训:个金客户经理应参加有关部门组织的专业培训\n并通过业务考试。 \n(五)符合分行人事管理和专业管理的要求。 \n第四章 个人业绩考核标准 \n第八条 个金客户经理个人业绩以储蓄季日均、季有效净增发卡\n量、季净增个贷余额三项业务为主要考核指标,实行季度考核。具体\n标准如下: \n \n \n类别 行员级别 考核分值 准入标准 \n储蓄业务 个贷业务 卡业务 \n客户经理助理 5 90 300 万 500 张 \n4 95'), Document(metadata={'producer': 'Microsoft® Word 2019', 'creator': 'Microsoft® Word 2019', 'creationdate': '2023-05-06T22:46:33+08:00', 'author': 'Chen Yang', 'moddate': '2023-05-06T22:46:33+08:00', 'source': './浦发上海浦东发展银行西安分行个金客户经理考核办法.pdf', 'total_pages': 9, 'page': 3, 'page_label': '4'}, page_content='百度文库 - 好好学习,天天向上 \n-4 \n3 100 \n2 105 \n1 110 \n客户经理 5 115 300 万 500 张 \n4 120 \n3 125 \n2 130 \n1 135 \n高级客户经理 5 140 500 万 800 万 \n4 145 \n3 150 \n2 155 \n1 160 \n资深客户经理 5 165 500 万 800 万 \n4 170 \n3 175 \n2 180 \n1 185 \n说明:1.储蓄业务(季日均余额)为各类个金客户经理考核进入的最低标准。 \n2.卡业务(季新增发有效卡量)为见习、D 类、初级客户经理进入的最低标准。 \n3.有效卡的概念:每张卡月均余额为 100 元以上。 \n4.个贷业务(季新增发放个贷)为中级以上客户经理考核进入的最低标准。 \n5.超出最低考核标准可相互折算,折算标准:50 万储蓄=50 万个贷=50 张有效卡=5 分(折算以 5 分为单位)'), Document(metadata={'producer': 'Microsoft® Word 2019', 'creator': 'Microsoft® Word 2019', 'creationdate': '2023-05-06T22:46:33+08:00', 'author': 'Chen Yang', 'moddate': '2023-05-06T22:46:33+08:00', 'source': './浦发上海浦东发展银行西安分行个金客户经理考核办法.pdf', 'total_pages': 9, 'page': 4, 'page_label': '5'}, page_content='百度文库 - 好好学习,天天向上 \n-5 \n第五章 工作质量考核标准 \n第九条 工作质量考核实行扣分制。工作质量指个金客户经理在\n从事所有个人业务时出现投诉、差错及风险。该项考核最多扣50 分,\n如发生重大差错事故,按分行有关制度处理。 \n(一)服务质量考核: \n1、工作责任心不强,缺乏配合协作精神;扣5 分 \n2、客户服务效率低,态度生硬或不及时为客户提供维护服务,\n有客户投诉的,每投诉一次扣2 分 \n3、不服从支行工作安排,不认真参加分(支)行宣传活动的,\n每次扣2 分; \n4、未能及时参加分行(支行)组织的各种业务培训、考试和专\n题活动的每次扣2 分; \n5、未按规定要求进行贷前调查、贷后检查工作的,每笔扣5 分; \n6、未建立信贷台帐资料及档案的每笔扣5 分; \n7、在工作中有不廉洁自律情况的每发现一次扣50 分。 \n(二)个人资产质量考核: \n当季考核收息率97%以上为合格,每降1 个百分点扣2 分;不\n良资产零为合格,每超一个个百分点扣1 分。 \nA.发生跨月逾期,单笔不超过10 万元,当季收回者,扣1 分。 \nB.发生跨月逾期,2 笔以上累计金额不超过20 万元,当季收回\n者,扣2 分;累计超过20 万元以上的,扣4 分。'), Document(metadata={'producer': 'Microsoft® Word 2019', 'creator': 'Microsoft® Word 2019', 'creationdate': '2023-05-06T22:46:33+08:00', 'author': 'Chen Yang', 'moddate': '2023-05-06T22:46:33+08:00', 'source': './浦发上海浦东发展银行西安分行个金客户经理考核办法.pdf', 'total_pages': 9, 'page': 5, 'page_label': '6'}, page_content='百度文库 - 好好学习,天天向上 \n-6 \nC.发生逾期超过3 个月,无论金额大小和笔数,扣10 分。 \n \n第六章 聘任考核程序 \n第十条 凡达到本办法第三章规定的该技术职务所要求的行内职\n工,都可向分行人力资源部申报个金客户经理评聘。 \n第十一条 每年一月份为客户经理评聘的申报时间,由分行人力\n资源部、个人业务部每年二月份组织统一的资格考试。考试合格者由\n分行颁发个金客户经理资格证书,其有效期为一年。 \n第十二条 客户经理聘任实行开放式、浮动制,即:本人申报 —\n— 所在部门推荐 —— 分行考核 —— 行长聘任 —— 每年考评\n调整浮动。 \n第十三条 特别聘任: \n(一)经分行同意录用从其他单位调入的个金客户经理,由用人\n单位按D 类人员进行考核, 薪资待遇按其业绩享受行内正式行员工同\n等待遇。待正式转正后按第十一条规定申报技术职务。 \n(二)对为我行业务创新、工作业绩等方面做出重大贡献的市场\n人员经支行推荐、分行行长批准可越级聘任。 \n第十四条 对于创利业绩较高,而暂未入围技术职务系列,或所\n评聘技术职务较低的市场人员,各级领导要加大培养力度,使其尽快'), Document(metadata={'producer': 'Microsoft® Word 2019', 'creator': 'Microsoft® Word 2019', 'creationdate': '2023-05-06T22:46:33+08:00', 'author': 'Chen Yang', 'moddate': '2023-05-06T22:46:33+08:00', 'source': './浦发上海浦东发展银行西安分行个金客户经理考核办法.pdf', 'total_pages': 9, 'page': 6, 'page_label': '7'}, page_content='百度文库 - 好好学习,天天向上 \n-7 \n入围,并由所在行制定临时奖励办法。 \n \n第七章 考核待遇 \n第十五条 个人金融业务客户经理的收入基本由三部分组成: 客\n户经理等级基本收入、业绩奖励收入和日常工作绩效收入。 \n客户经理等级基本收入是指客户经理的每月基本收入, 基本分为\n助理客户经理、客户经理、高级客户经理和资深客户经理四大层面,\n在每一层面分为若干等级。 \n客户经理的等级标准由客户经理在上年的业绩为核定标准, 如果\n客户经理在我行第一次进行客户经理评级, 以客户经理自我评价为主\n要依据,结合客户经理以往工作经验,由个人金融部、人事部门共同\n最终决定客户经理的等级。 \n助理客户经理待遇按照人事部门对主办科员以下人员的待遇标\n准;客户经理待遇按照人事部门对主办科员的待遇标准;高级客户经\n理待遇按照人事部门对付科级的待遇标准; 资深客户经理待遇按照人\n事部门对正科级的待遇标准。 \n业绩奖励收入是指客户经理每个业绩考核期间的实际业绩所给\n与兑现的奖金部分。 \n日常工作绩效收入是按照个金客户经理所从事的事务性工作进\n行定量化考核,经过工作的完成情况进行奖金分配。该项奖金主要由\n个人金融部总经理和各支行的行长其从事个人金融业务的人员进行\n分配,主要侧重分配于从事个金业务的基础工作和创新工作。'), Document(metadata={'producer': 'Microsoft® Word 2019', 'creator': 'Microsoft® Word 2019', 'creationdate': '2023-05-06T22:46:33+08:00', 'author': 'Chen Yang', 'moddate': '2023-05-06T22:46:33+08:00', 'source': './浦发上海浦东发展银行西安分行个金客户经理考核办法.pdf', 'total_pages': 9, 'page': 7, 'page_label': '8'}, page_content='百度文库 - 好好学习,天天向上 \n-8 \n第十五条 各项考核分值总计达到某一档行员级别考核分值标\n准,个金客户经理即可在下一季度享受该级行员的薪资标准。下一季\n度考核时,按照已享受行员级别考核折算比值进行考核,以次类推。 \n第十六条 对已聘为各级客户经理的人员,当工作业绩考核达不\n到相应技术职务要求下限时,下一年技术职务相应下调。 \n第十七条 为保护个人业务客户经理创业的积极性,暂定其收入\n构成中基础薪点不低于40%。 \n \n第八章 管理与奖惩 \n第十八条 个金客户经理管理机构为分行客户经理管理委员会。\n管理委员会组成人员:行长或主管业务副行长,个人业务部、人力资\n源部、风险管理部负责人。 \n第十九条 客户经理申报的各种信息必须真实。分行个人业务部\n需对其工作业绩数据进行核实,并对其真实性负责;分行人事部门需\n对其学历、工作阅历等基本信息进行核实,并对其真实性负责。 \n第二十条 对因工作不负责任使资产质量产生严重风险或造成损\n失的给予降级直至开除处分,构成渎职罪的提请司法部门追究刑事责\n任。'), Document(metadata={'producer': 'Microsoft® Word 2019', 'creator': 'Microsoft® Word 2019', 'creationdate': '2023-05-06T22:46:33+08:00', 'author': 'Chen Yang', 'moddate': '2023-05-06T22:46:33+08:00', 'source': './浦发上海浦东发展银行西安分行个金客户经理考核办法.pdf', 'total_pages': 9, 'page': 8, 'page_label': '9'}, page_content='百度文库 - 好好学习,天天向上 \n-9 \n第九章 附 则 \n第二十一条 本办法自发布之日起执行。 \n第二十二条 本办法由上海浦东发展银行西安分行行负责解释和\n修改。')] ``` ```python import os from langchain_community.document_loaders.pdf import PyPDFLoader from langchain_community.embeddings import DashScopeEmbeddings from langchain_community.llms import Tongyi from langchain_chroma import Chroma from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain.retrievers import ParentDocumentRetriever from langchain.storage import InMemoryStore # 初始化大语言模型 DASHSCOPE_API_KEY = os.getenv("DASHSCOPE_API_KEY") llm = Tongyi( model_name="qwen-max", dashscope_api_key=DASHSCOPE_API_KEY ) # 创建嵌入模型 embeddings = DashScopeEmbeddings( model="text-embedding-v1", dashscope_api_key=DASHSCOPE_API_KEY ) # 创建主文档分割器 parent_splitter = RecursiveCharacterTextSplitter(chunk_size=512) # 创建子文档分割器 child_splitter = RecursiveCharacterTextSplitter(chunk_size=256) # 创建向量数据库对象 vectorstore = Chroma( collection_name="split_parents", embedding_function = embeddings ) # 创建内存存储对象 store = InMemoryStore() # 创建父文档检索器 retriever = ParentDocumentRetriever( vectorstore=vectorstore, docstore=store, child_splitter=child_splitter, parent_splitter=parent_splitter, search_kwargs={"k": 2} ) # 添加文档集 retriever.add_documents(docs) ``` ```python # 切割出来主文档的数量 len(list(store.yield_keys())) # 11 ``` ```python from langchain.prompts import ChatPromptTemplate from langchain.schema.runnable import RunnableMap from langchain.schema.output_parser import StrOutputParser # 创建prompt模板(RAG Prompt) template = """You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use two sentences maximum and keep the answer concise. Question: {question} Context: {context} Answer: """ # 由模板生成prompt prompt = ChatPromptTemplate.from_template(template) # 创建 chain(LCEL langchain 表达式语言) chain = RunnableMap({ "context": lambda x: retriever.get_relevant_documents(x["question"]), "question": lambda x: x["question"] }) | prompt | llm | StrOutputParser() ``` ```python query = "客户经理被投诉了,投诉一次扣多少分?" response = chain.invoke({"question": query}) print(response) #C:\Users\Administrator\AppData\Local\Temp\ipykernel_52976\673103712.py:20: LangChainDeprecationWarning: The method `BaseRetriever.get_relevant_documents` was deprecated in langchain-core 0.1.46 and will be removed in 1.0. Use :meth:`~invoke` instead. "context": lambda x: retriever.get_relevant_documents(x["question"]), # 每投诉一次扣2分。如果发生重大差错事故,将按分行有关制度处理。 ``` #### 5.3.4. 准备评估的QA数据集 ```python from datasets import Dataset # 保证问题需要多样性,场景化覆盖 questions = [ "客户经理被投诉了,投诉一次扣多少分?", "客户经理每年评聘申报时间是怎样的?", "客户经理在工作中有不廉洁自律情况的,发现一次扣多少分?", "客户经理不服从支行工作安排,每次扣多少分?", "客户经理需要什么学历和工作经验才能入职?", "个金客户经理职位设置有哪些?" ] ground_truths = [ "每投诉一次扣2分", "每年一月份为客户经理评聘的申报时间", "在工作中有不廉洁自律情况的每发现一次扣50分", "不服从支行工作安排,每次扣2分", "须具备大专以上学历,至少二年以上银行工作经验", "个金客户经理职位设置为:客户经理助理、客户经理、高级客户经理、资深客户经理" ] answers = [] contexts = [] # Inference for query in questions: answers.append(chain.invoke({"question": query})) contexts.append([docs.page_content for docs in retriever.get_relevant_documents(query)]) # To dict data = { "user_input": questions, "response": answers, "retrieved_contexts": contexts, "reference": ground_truths } # Convert dict to dataset dataset = Dataset.from_dict(data) dataset ``` 结果如下: ```python d:\envs\chapter-3\lib\site-packages\tqdm\auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html from .autonotebook import tqdm as notebook_tqdm Dataset({ features: ['user_input', 'response', 'retrieved_contexts', 'reference'], num_rows: 6 }) ``` ```python # 评测结果 from ragas import evaluate from ragas.metrics import ( faithfulness, answer_relevancy, context_recall, context_precision, ) result = evaluate( dataset = dataset, metrics=[ context_precision, # 上下文精度 context_recall, # 上下文召回率 faithfulness, # 忠实度 answer_relevancy, # 答案相关性 ], embeddings=embeddings ) df = result.to_pandas() df ``` ```python 若出现如下异常,是由于pydantic版本问题造成: - `AttributeError: module 'pydantic._internal._typing_extra' has no attribute 'merge_cls_and_parent_ns'` 卸载: - `pip uninstall pydantic -y` 安装: - `pip install pydantic==2.7.4` ``` ```python ## 6. 商业落地实施RAG工程的核心步骤 1. 数据集的准备(语料) - 文档结构化处理:采用现代的智能文档技术 2. 测试集的准备(QA对) - 使用主流的 LLM 模型来根据文档来生成 QA 对 3. 技术选型 - 零代码搭建: DB-GPT / Dify / RAGFlow / Coze Studio... - 低代码搭建: Qwen-Agent / TrustRAG / GraphRAG / LightRAG - 高度定制开发:LlamaIndex / LangChain / LangGraph 4. 构建知识库 5. 测试和优化 - 根据不同的阶段来进行优化处理 - 数据预处理,结构化处理 - 切片策略 - 召回策略 - 重排序 - RAFT 6. 最终效果评估 - Ragas 来进行 RAG 性能的评估 7. 生产环境部署 - 本地模型部署 vLLM ``` ## 7. 学习打卡 - 理解并掌握RAG高效召回方法 - 掌握Qwen-Agent构建RAG,使用Qwen-Agent实现自定义需求 - 掌握RAG质量评估,熟练使用Ragas评估RAG质量 - 理解并掌握商业落地实施RAG工程的核心步骤
李智
2025年9月27日 18:16
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
分享
链接
类型
密码
更新密码