AI大模型学习
1、环境搭建
2、Embedding与向量数据库
3、RAG技术与应用
4、RAG高级技术与实践
5、LlamaIndex知识管理与信息检索
6、基于LlamaIndex开发的中医临床诊疗助手
7、LangChain多任务应用开发
8、Function Calling与Agent 智能体
9、Agent应用与图状态编排框架LangGraph
10、基于LangGraph实现智能分诊系统
11、MCP应用技术开发
12、AI 应用开发新范式 MCP 技术详解
13、基于LangGraph的多智能体交互系统
14、企业级智能分诊系统RAG项目
15、LangGraph与Agno-AGI深度对比分析
本文档使用 MrDoc 发布
-
+
首页
2、Embedding与向量数据库
# 嵌入模型与向量数据库 ## 💡 学习目标 1. 理解向量表征 2. 向量与文本向量 3. 向量间的相似度计算 4. Embedding Models嵌入模型原理及选择 5. 向量数据库概述及核心原理 6. Chroma向量数据库核心操作 7. Milvus向量数据库扩展学习 ### 1. 向量表征(Vector Representation) 在人工智能领域,向量表征(Vector Representation)是核心概念之一。通过将文本、图像、声音、行为甚至复杂关系转化为高维向量(Embedding),AI系统能够以数学方式理解和处理现实世界中的复杂信息。这种表征方式为机器学习模型提供了统一的“语言”。 #### 1.1. 向量表征的本质 向量表征的本质:万物皆可数学化 (1)核心思想 降维抽象:将复杂对象(如一段文字、一张图片)映射到低维稠密向量空间,保留关键语义或特征。 相似性度量:向量空间中的距离(如余弦相似度)反映对象之间的语义关联(如“猫”和“狗”的向量距离小于“猫”和“汽车”)。 (2)数学意义 特征工程自动化:传统机器学习依赖人工设计特征(如文本的TF-IDF),而向量表征通过深度学习自动提取高阶抽象特征。 跨模态统一:文本、图像、视频等不同模态数据可映射到同一向量空间,实现跨模态检索(如“用文字搜图片”)。 #### 1.2. 向量表征的典型应用场景 (1)自然语言处理(NLP) 词向量(Word2Vec、GloVe):单词映射为向量,解决“一词多义”问题(如“苹果”在“水果”和“公司”上下文中的不同向量)。 句向量(BERT、Sentence-BERT):整句语义编码,用于文本相似度计算、聚类(如客服问答匹配)。 知识图谱嵌入(TransE、RotatE):将实体和关系表示为向量,支持推理(如预测“巴黎-首都-法国”的三元组可信度)。 (2)计算机视觉(CV) 图像特征向量(CNN特征):ResNet、ViT等模型提取图像语义,用于以图搜图、图像分类。 跨模态对齐(CLIP):将图像和文本映射到同一空间,实现“描述文字生成图片”或反向搜索。 (3)推荐系统 用户/物品向量:用户行为序列(点击、购买)编码为用户向量,商品属性编码为物品向量,通过向量内积预测兴趣匹配度(如YouTube推荐算法)。 (4)复杂系统建模 图神经网络(GNN):社交网络中的用户、商品、交互事件均表示为向量,捕捉网络结构信息(如社区发现、欺诈检测)。 时间序列向量化:将股票价格、传感器数据编码为向量,预测未来趋势(如LSTM、Transformer编码)。 #### 1.3. 向量表征的技术实现 (1)经典方法 无监督学习:Word2Vec通过上下文预测(Skip-Gram)或矩阵分解(GloVe)生成词向量。 有监督学习:微调预训练模型(如BERT)适应具体任务,提取任务相关向量。 (2)前沿方向 对比学习(Contrastive Learning):通过构造正负样本对(如“同一图片的不同裁剪”为正样本),拉近正样本向量距离,推开负样本(SimCLR、MoCo)。 多模态融合:将文本、图像、语音等多模态信息融合为统一向量(如Google的MUM模型)。 动态向量:根据上下文动态调整向量(如Transformer的注意力机制),解决静态词向量无法适应多义性的问题。 ### 2. 什么是向量 向量是一种有大小和方向的数学对象。它可以表示为从一个点到另一个点的有向线段。例如,二维空间中的向量可以表示为 (x,y),表示从原点 (0,0) 到点 (x,y)的有向线段。  以此类推,我可以用一组坐标 (X1,X2, X3...)表示一个 N 维空间中的向量, N 叫向量的维度。 #### 2.1 文本向量(Text Embeddings) 1. 将文本转成一组 N 维浮点数,即文本向量又叫 Embeddings 2. 向量之间可以计算距离,距离远近对应语义相似度大小 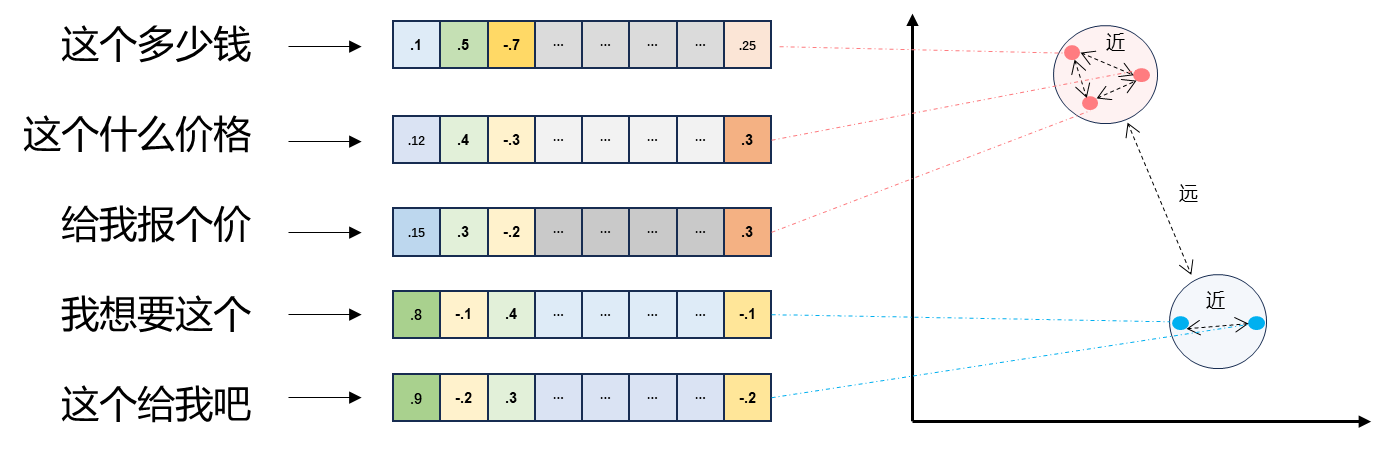 #### 2.2 文本向量是怎么得到的(选) 1. 构建相关(正例)与不相关(负例)的句子对样本 2. 训练双塔式模型,让正例间的距离小,负例间的距离大 例如: 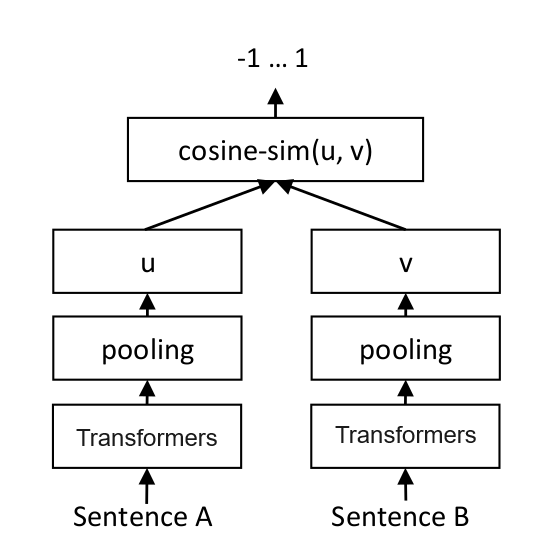 扩展阅读:[https://www.sbert.net](https://www.sbert.net "https://www.sbert.net") #### 2.3 向量间的相似度计算 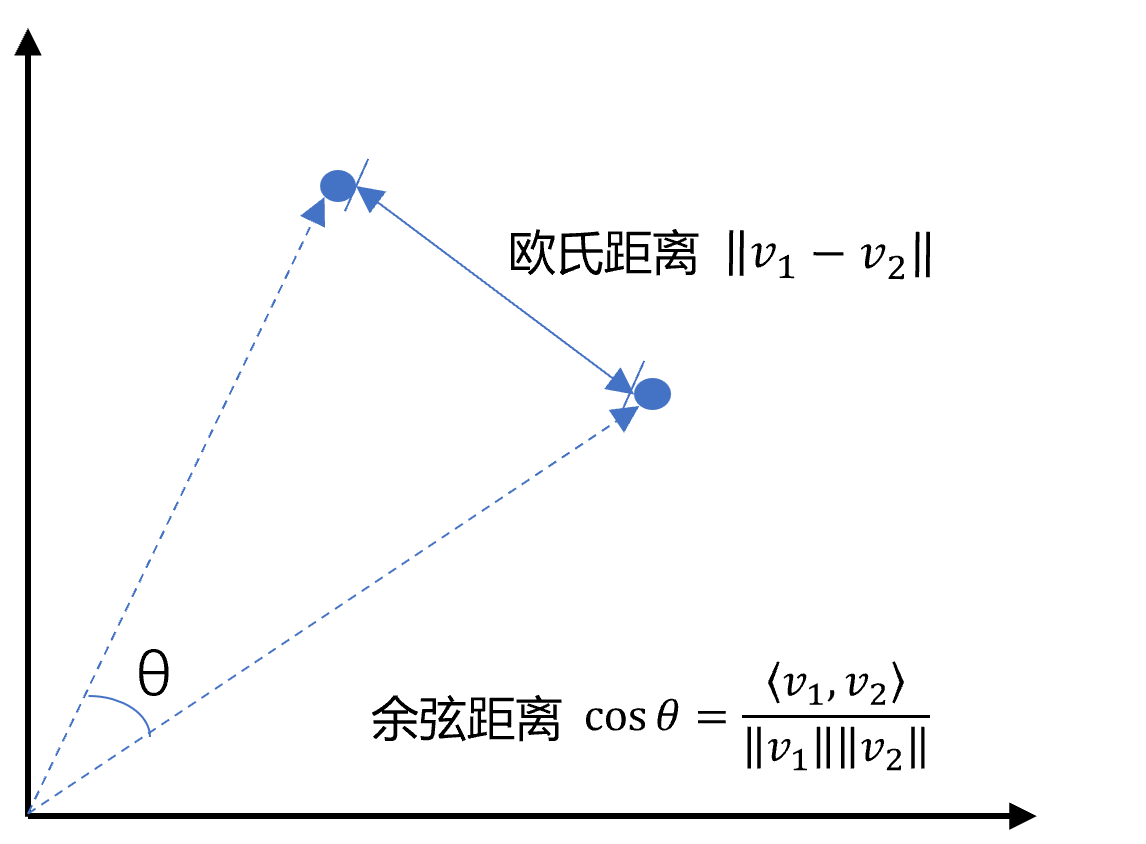 余弦相似度是通过计算两个向量夹角的余弦值来衡量相似性,等于两个向量的点积除以两个向量长度的乘积。 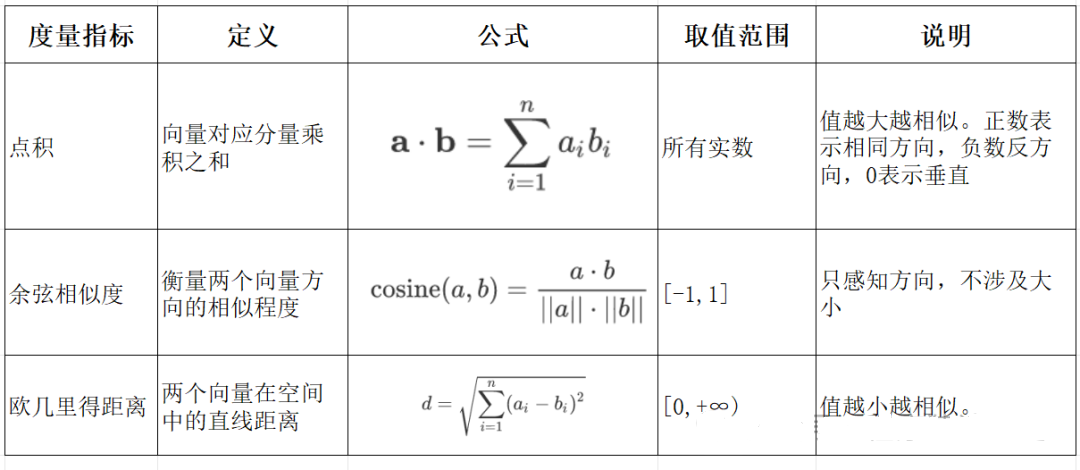 ```python pip install --upgrade numpy pip install --upgrade openai ``` ```python import os from openai import OpenAI # 需要在系统环境变量中配置好相应的key # OpenAI key(1 代理方式 2 官网注册购买) # OPENAI_API_KEY # 阿里百炼配置 # DASHSCOPE_API_KEY sk-xxx # DASHSCOPE_BASE_URL https://dashscope.aliyuncs.com/compatible-mode/v1 client = OpenAI( api_key=os.getenv("DASHSCOPE_API_KEY"), # 如果您没有配置环境变量,请在此处用您的API Key进行替换 base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" # 百炼服务的base_url ) ``` ```python import numpy as np from numpy import dot from numpy.linalg import norm ``` ```python def cos_sim(a, b): '''余弦距离 -- 越大越相似''' return dot(a, b)/(norm(a)*norm(b)) def l2(a, b): '''欧氏距离 -- 越小越相似''' x = np.asarray(a)-np.asarray(b) return norm(x) ``` ```python def get_embeddings(texts, model="text-embedding-v1", dimensions=None): '''封装 OpenAI 的 Embedding 模型接口''' if model == "text-embedding-v1": dimensions = None if dimensions: data = client.embeddings.create( input=texts, model=model, dimensions=dimensions).data else: data = client.embeddings.create(input=texts, model=model).data return [x.embedding for x in data] ``` ```python test_query = ["AI - 用科技力量,构建智能未来!"] vec = get_embeddings(test_query)[0] print(f"Total dimension: {len(vec)}") print(f"First 10 elements: {vec[:10]}") ``` 上面运行结果如下: ```python Total dimension: 1536 First 10 elements: [1.8666456937789917, -3.2402632236480713, 1.2597650289535522, -2.3682942390441895, 2.38277530670166, -3.507119655609131, 1.461685299873352, -4.431000709533691, -2.722412586212158, 1.1500697135925293] ``` ```python query = "国际争端" # 且能支持跨语言 # query = "global conflicts" documents = [ "联合国就苏丹达尔富尔地区大规模暴力事件发出警告", "土耳其、芬兰、瑞场典与北约代表将继续就瑞典“入约”问题进行谈判", "日本岐阜市陆上自卫队射击内发生枪击事件 3人受伤", "国家游泳中心(水立方):恢复游泳、嬉水乐园等水上项目运营", "我国首次在空间站开展舱外辐射生物学暴露实验", ] query_vec = get_embeddings([query])[0] doc_vecs = get_embeddings(documents) print("Query与自己的余弦距离: {:.2f}".format(cos_sim(query_vec, query_vec))) print("Query与Documents的余弦距离:") for vec in doc_vecs: print(cos_sim(query_vec, vec)) print() print("Query与自己的欧氏距离: {:.2f}".format(l2(query_vec, query_vec))) print("Query与Documents的欧氏距离:") for vec in doc_vecs: print(l2(query_vec, vec)) ``` 上面运行结果如下: ```python Query与自己的余弦距离: 1.00 Query与Documents的余弦距离: 0.3391104764873069 0.2688252041673728 0.07006357800727327 0.10452984187535314 0.12916023809848173 Query与自己的欧氏距离: 0.00 Query与Documents的欧氏距离: 109.51274483356156 109.95511077641505 128.00071081019382 123.82186767906518 134.32520931177118 ``` ### 3. Embedding Models 嵌入模型 #### 3.1. 什么是嵌入(Embedding)? 嵌入(Embedding)是指非结构化数据转换为向量的过程,通过神经网络模型或相关大模型,将真实世界的离散数据投影到高维数据空间上,根据数据在空间中的不同距离,反映数据在物理世界的相似度。 #### 3.2. 嵌入模型概念及原理 1. 嵌入模型的本质 嵌入模型(Embedding Model)是一种将离散数据(如文本、图像)映射到连续向量空间的技术。通过高维向量表示(如 768 维或 3072 维),模型可捕捉数据的语义信息,使得语义相似的文本在向量空间 中距离更近。例如,“忘记密码”和“账号锁定”会被编码为相近的向量,从而支持语义检索而非仅关键词匹配。 2. 核心作用 - 语义编码:将文本、图像等转换为向量,保留上下文信息(如 BERT 的 CLS Token 或均值池化。相似度计算:通过余弦相似度、欧氏距离等度量向量关联性,支撑检索增强生成(RAG)、推荐系统等应用。 - 信息降维:压缩复杂数据为低维稠密向量,提升存储与计算效率。 3. 关键技术原理 - 上下文依赖:现代模型(如 BGE-M3)动态调整向量,捕捉多义词在不同语境中的含义。 - 训练方法:对比学习(如 Word2Vec 的 Skip-gram/CBOW)、预训练+微调(如 BERT)。 #### 3.3. 主流嵌入模型分类与选型指南 Embedding 模型将文本转换为数值向量,捕捉语义信息,使计算机能够理解和比较内容的"意义"。选择 Embedding 模型的考虑因素: | 因素 | 说明 | | --- | --- | | 任务性质 |匹配任务需求(问答、搜索、聚类等) | | 领域特性 | 通用vs专业领域(医学、法律等) | | 多语言支持 | 需处理多语言内容时考虑 | | 维度 | 权衡信息丰富度与计算成本 | | 许可条款 | 开源vs专有服务 | | 最大Tokens | 适合的上下文窗口大小 | 最佳实践:为特定应用测试多个 Embedding 模型,评估在实际数据上的性能而非仅依赖通用基准。 #### 1. 通用全能型 - **BGE-M3**:北京智源研究院开发,支持多语言、混合检索(稠密+稀疏向量),处理 8K 上下文,适合企业级知识库。 - **NV-Embed-v2**:基于 Mistral-7B,检索精度高(MTEB 得分 62.65),但需较高计算资源。 #### 2. 垂直领域特化型 - **中文场景**: BGE-large-zh-v1.5 (合同/政策文件)、 M3E-base (社交媒体分析)。 - **多模态场景**: BGE-VL (图文跨模态检索),联合编码 OCR 文本与图像特征。 #### 3. 轻量化部署型 - **nomic-embed-text**:768 维向量,推理速度比 OpenAI 快 3 倍,适合边缘设备。 - **gte-qwen2-1.5b-instruct**:1.5B 参数,16GB 显存即可运行,适合初创团队原型验。 **选型决策树:** **中文为主 → BGE 系列 > M3E;** **多语言需求 → BGE-M3 > multilingual-e5;** **预算有限 → 开源模型(如 Nomic Embed)** **Embddding Leaderboard** 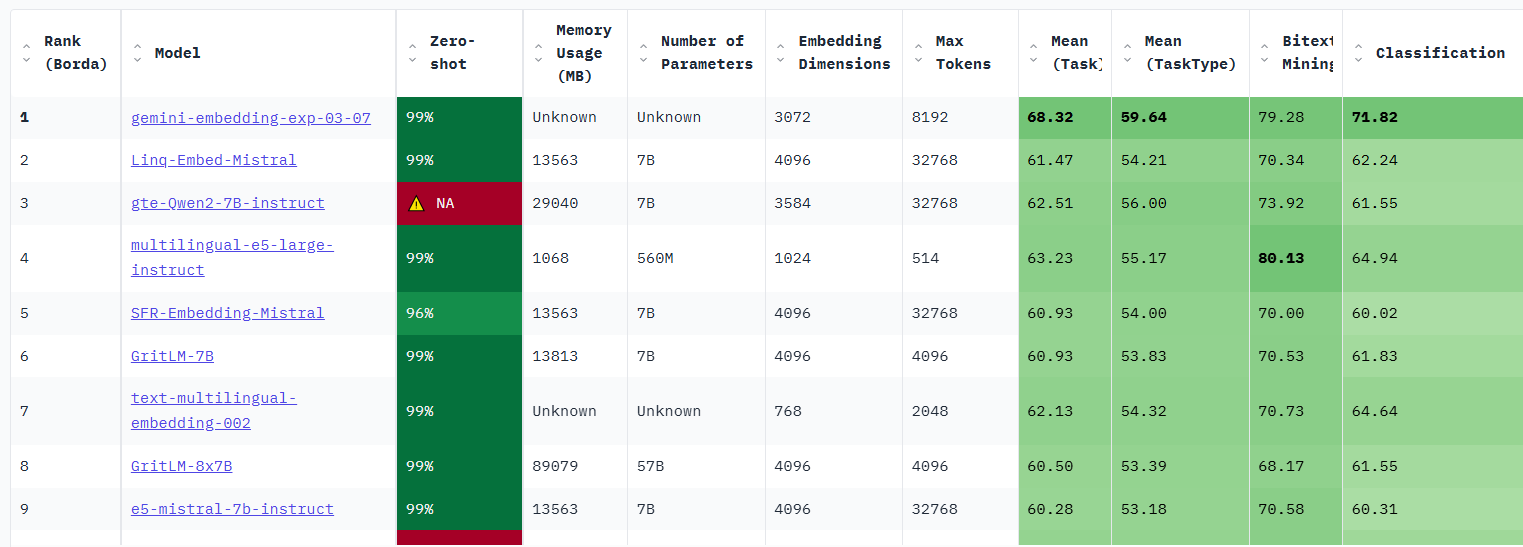 [https://huggingface.co/spaces/mteb/leaderboard](https://huggingface.co/spaces/mteb/leaderboard "https://huggingface.co/spaces/mteb/leaderboard") #### 3.4. OpenAI 新发布的两个 Embedding 模型 2024 年 1 月 25 日,OpenAI 新发布了两个 Embedding 模型 - **text-embedding-3-large** - **text-embedding-3-small** 其最大特点是,支持自定义的缩短向量维度,从而在几乎不影响最终效果的情况下降低向量检索与相似度计算的复杂度。 通俗的说:**越大越准、越小越快**。 官方公布的评测结果:  注:**MTEB** 是一个大规模多任务的 Embedding 模型公开评测集 #### 3.5. 嵌入模型使用 1. 使用 API 调用方式 ```python import os from openai import OpenAI client = OpenAI( api_key=os.getenv("DASHSCOPE_API_KEY"), # 如果您没有配置环境变量,请在此处用您的API Key进行替换 base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" # 百炼服务的base_url ) completion = client.embeddings.create( model="text-embedding-v4", input='我在学习AI大模型', dimensions=1024, encoding_format="float" ) print(completion.model_dump_json()) ``` ### 4. 向量数据库 #### 4.1. 什么是向量数据库? 向量数据库,是专门为向量检索设计的中间件! 高效存储、快速检索和管理高纬度向量数据的系统称为向量数据库 一种专门用于存储和检索高维向量数据的数据库。它将数据(如文本、图像、音频等)通过嵌入模型转换为向量形式,并通过高效的索引和搜索算法实现快速检索。 向量数据库的核心作用是实现相似性搜索,即通过计算向量之间的距离(如欧几里得距离、余弦相似度等)来找到与目标向量最相似的其他向量。它特别适合处理非结构化数据,支持语义搜索、内容推荐等场景。 **核心功能:** - 向量存储 - 相似性度量 - 相似性搜索 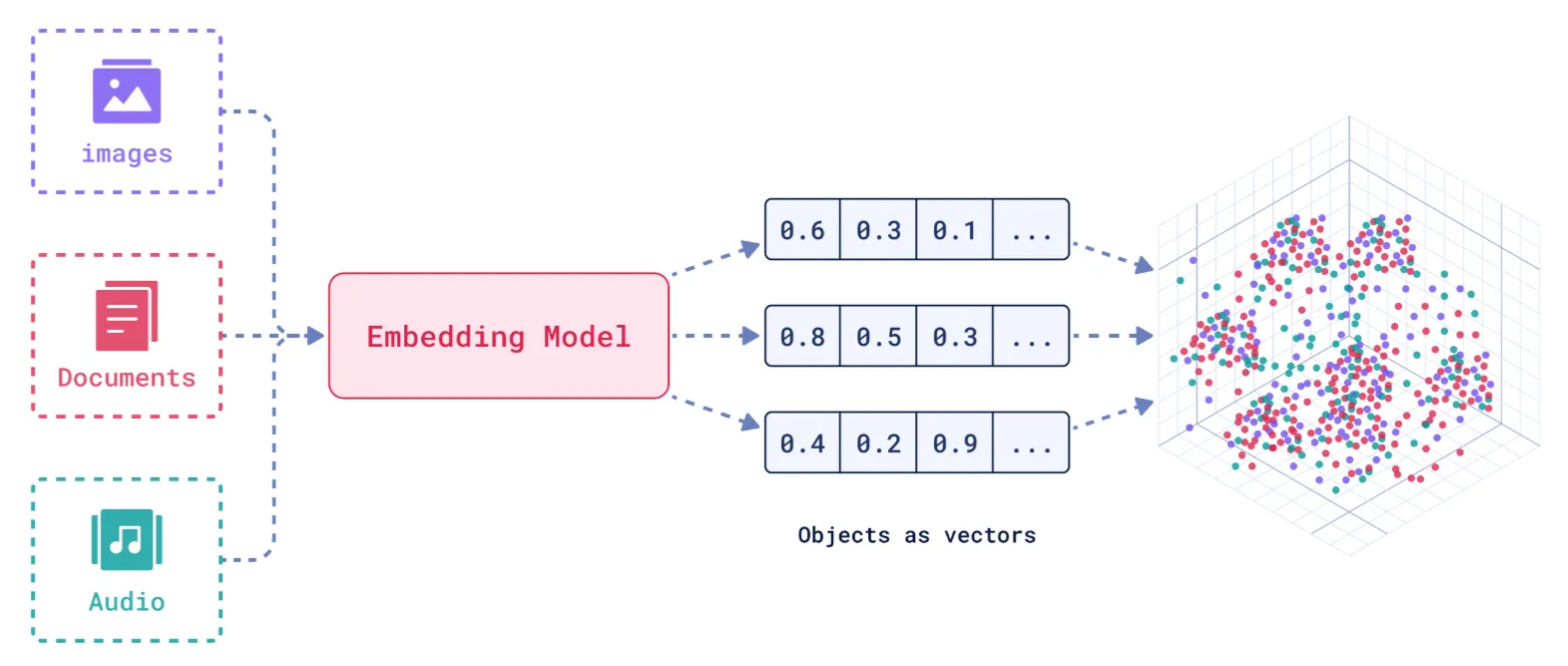 ### 4.2. 如何存储和检索嵌入向量? - 存储:向量数据库将嵌入向量存储为高维空间中的点,并为每个向量分配唯一标识符(ID),同时支持存储元数据。 - 检索:通过近似最近邻(ANN)算法(如PQ等)对向量进行索引和快速搜索。比如,FAISS和Milvus等数据库通过高效的索引结构加速检索。 ### 4.3 向量数据库与传统数据库对比 1. 数据类型 - 传统数据库:存储结构化数据(如表格、行、列)。 - 向量数据库:存储高维向量数据,适合非结构化数据。 2. 查询方式 - 传统数据库:依赖精确匹配(如=、<、>)。 - 向量数据库:基于相似度或距离度量(如欧几里得距离、余弦相似度)。 3. 应用场景 - 传统数据库:适合事务记录和结构化信息管理。 - 向量数据库:适合语义搜索、内容推荐等需要相似性计算的场景。 <div class="alert alert-success"> <b>澄清几个关键概念:</b><ul> <li>向量数据库的意义是快速的检索;</li> <li>向量数据库本身不生成向量,向量是由 Embedding 模型产生的;</li> <li>向量数据库与传统的关系型数据库是互补的,不是替代关系,在实际应用中根据实际需求经常同时使用。</li> </ul> </div> ### 4.4. 主流向量数据库功能对比 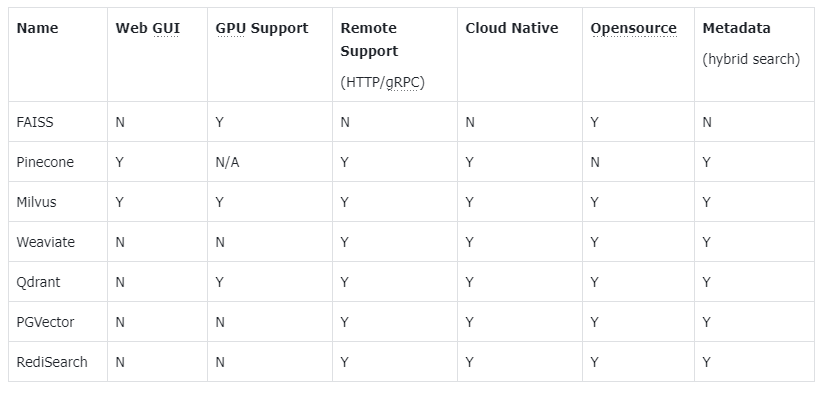 - **FAISS**: Meta 开源的向量检索引擎 https://github.com/facebookresearch/faiss - Pinecone: 商用向量数据库,只有云服务 https://www.pinecone.io/ - **Milvus**: 开源向量数据库,同时有云服务 https://milvus.io/ - Weaviate: 开源向量数据库,同时有云服务 https://weaviate.io/ - **Qdrant**: 开源向量数据库,同时有云服务 https://qdrant.tech/ - PGVector: Postgres 的开源向量检索引擎 https://github.com/pgvector/pgvector - RediSearch: Redis 的开源向量检索引擎 https://github.com/RediSearch/RediSearch - ElasticSearch 也支持向量检索 https://www.elastic.co/enterprise-search/vector-search 扩展阅读:[https://guangzhengli.com/blog/zh/vector-database](https://guangzhengli.com/blog/zh/vector-database "https://guangzhengli.com/blog/zh/vector-database") ### 4.5. Chroma 向量数据库 官方文档:https://docs.trychroma.com/docs/overview/introduction **1. 什么是 Chroma?** Chroma 是一款开源的向量数据库,专为高效存储和检索高维向量数据设计。其核心能力在于语义相似性搜索,支持文本、图像等嵌入向量的快速匹配,广泛应用于大模型上下文增强(RAG)、推荐系统、多模态检索等场景。与传统数据库不同,Chroma 基于向量距离(如余弦相似度、欧氏距离)衡量数据关联性,而非关键词匹配。 **2. 核心优势** - 轻量易用:以 Python/JS 包形式嵌入代码,无需独立部署,适合快速原型开发。 - 灵活集成:支持自定义嵌入模型(如 OpenAI、HuggingFace),兼容 LangChain 等框架。 - 高性能检索:采用 HNSW 算法优化索引,支持百万级向量毫秒级响应。 - 多模式存储:内存模式用于开发调试,持久化模式支持生产环境数据落地。 ### 4.6. Chroma 安装与基础配置 **1. 安装** 通过 Python 包管理器安装 ChromaDB: ```python # 安装 Chroma 向量数据库完成功能 pip install chromadb ``` **2. 初始化客户端** - 内存模式(一般不建议使用): ```python import chromadb client = chromadb.Client() ``` - 持久化模式: ```python # 数据保存至本地目录 client = chromadb.PersistentClient(path="./chroma") ``` ### 4.7. Chroma 核心操作流程 **1. 集合(Collection)** 集合是 Chroma 中管理数据的基本单元,类似关系数据库的表: (1)创建集合 ```python from chromadb.utils import embedding_functions # 默认情况下,Chroma 使用 DefaultEmbeddingFunction,它是基于 Sentence Transformers 的 MiniLM-L6-v2 模型 default_ef = embedding_functions.DefaultEmbeddingFunction() # 使用 OpenAI 的嵌入模型,默认使用 text-embedding-ada-002 模型 # openai_ef = embedding_functions.OpenAIEmbeddingFunction( # api_key="YOUR_API_KEY", # model_name="text-embedding-3-small" # ) ``` ```python # 自定义 Embedding Functions from chromadb import Documents, EmbeddingFunction, Embeddings class MyEmbeddingFunction(EmbeddingFunction): def __call__(self, texts: Documents) -> Embeddings: # embed the documents somehow return embeddings ``` ```python collection = client.create_collection( name = "my_collection", configuration = { # HNSW 索引算法,基于图的近似最近邻搜索算法(Approximate Nearest Neighbor,ANN) "hnsw": { "space": "cosine", # 指定余弦相似度计算 "ef_search": 100, "ef_construction": 100, "max_neighbors": 16, "num_threads": 4 }, # 指定向量模型 "embedding_function": default_ef } ) ``` (2)查询集合 ```python collection = client.get_collection(name="my_collection") ``` - peek() - returns a list of the first 10 items in the collection. - count() - returns the number of items in the collection. - modify() - rename the collection ```python print(collection.peek()) print(collection.count()) # print(collection.modify(name="new_name")) ``` (3)删除集合 ```python client.delete_collection(name="my_collection") ``` **2. 添加数据** 支持自动生成或手动指定嵌入向量: ```python # 方式1:自动生成向量(使用集合指定的嵌入模型) collection.add( # 文档的集合 documents = ["RAG是一种检索增强生成技术", "向量数据库存储文档的嵌入表示", "在机器学习领域,智能体(Agent)通常指能够感知环境、做出决策并采取行动以实现特定目标的实体"], # 文档元数据信息 metadatas = [{"source": "RAG"}, {"source": "向量数据库"}, {"source": "Agent"}], # id ids = ["id1", "id2", "id3"] ) # 方式2:手动传入预计算向量(实际开发中推荐使用) # collection.add( # embeddings = get_embeddings("RAG是什么?") # documents = ["文本1", "文本2"], # ids = ["id3", "id4"] # ) ``` ```python C:\Users\Administrator\.cache\chroma\onnx_models\all-MiniLM-L6-v2\onnx.tar.gz: 100%|█| 79.3M/79.3M [00:06<00:00, 13.8Mi ``` **3. 查询数据** - 文本查询(自动向量化): ```python results = collection.query( query_texts = ["RAG是什么?"], n_results = 3, where = {"source": "RAG"}, # 按元数据过滤 # where_document = {"$contains": "检索增强生成"} # 按文档内容过滤 ) print(results) ``` ```python {'ids': [['id1']], 'embeddings': None, 'documents': [['RAG是一种检索增强生成技术,在智能客服系统中大量使用']], 'uris': None, 'included': ['metadatas', 'documents', 'distances'], 'data': None, 'metadatas': [[{'source': 'RAG'}]], 'distances': [[0.3491383194923401]]} ``` - 向量查询(自定义输入): ```python # results = collection.query( # query_embeddings = [[0.5, 0.6, ...]], # n_results = 3 # ) ``` **4. 数据管理** 更新集合中的数据: ```python collection.update(ids=["id1"], documents=["RAG是一种检索增强生成技术,在智能客服系统中大量使用"]) ``` 删除集合中的数据: ```python collection.delete(ids=["id3"]) ``` ### 4.8. Chroma Client-Server Mode - Server 端 默认端口 8000 ```sh chroma run --path /db_path ``` 修改端口:--port 端口号 ```sh chroma run --port 8001 --path /db_path ``` - Client 端 ```python import chromadb # 远程连接 Chroma Server chroma_client = chromadb.HttpClient(host='localhost', port=8000) ``` ```python # 测试 collection = chroma_client.create_collection(name = "my_collection") collection = chroma_client.get_collection(name="my_collection") print(collection.count()) ``` ### 5. Milvus 扩展学习 中文官网:https://milvus.io/zh <p style="text-align:center">Milvus 架构图<p> 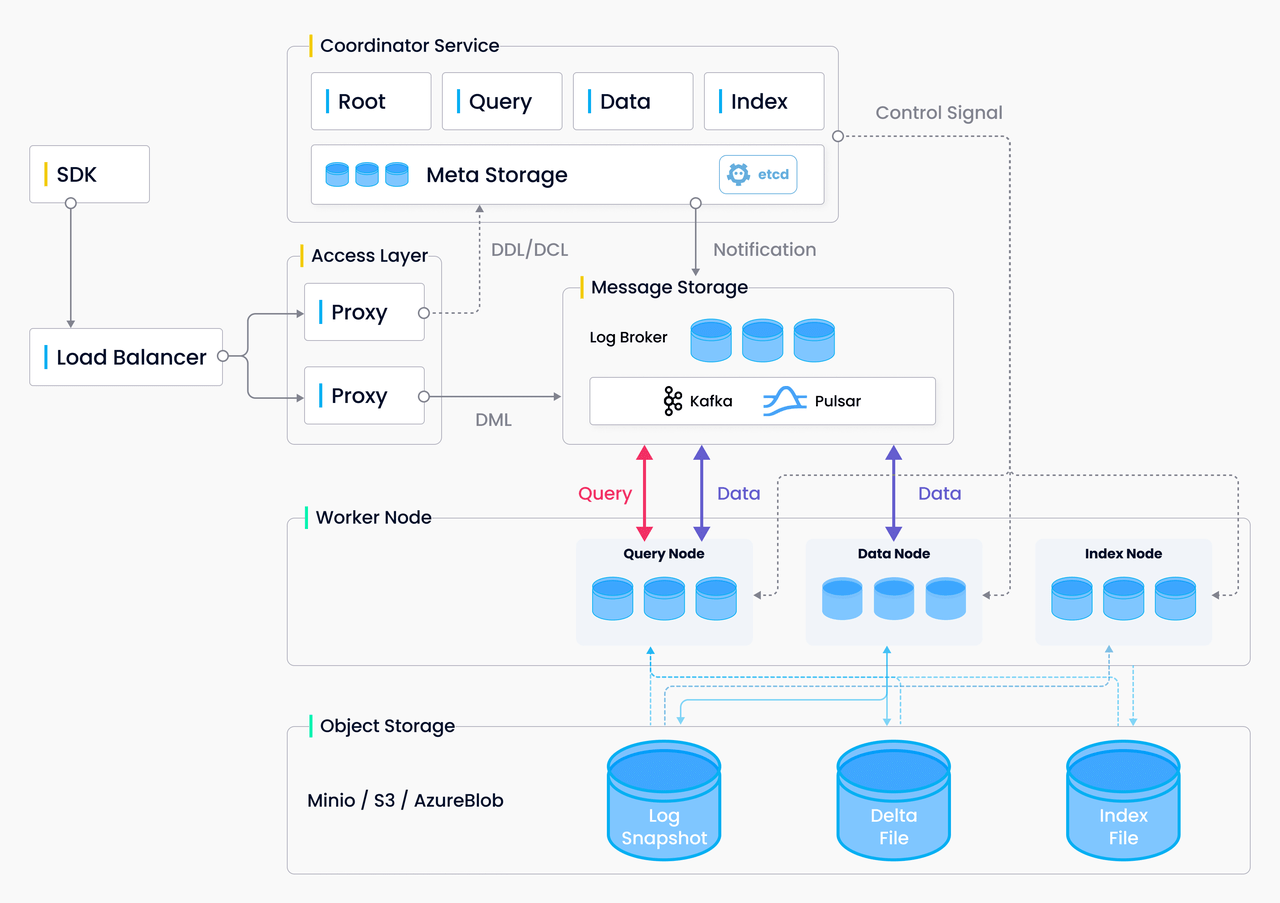
李智
2025年10月8日 18:00
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
分享
链接
类型
密码
更新密码