MySQL进阶
01、MySQL进阶:剖析MySQL索引底层数据结构
02、MySQL进阶:MySQL不同存储引擎下索引的实现
03、MySQL进阶:Explain深度剖析
04、MySQL进阶:践行索引优化
05、MySQL进阶:锁等待及死锁初探
06、MySQL进阶:无索引行锁升级为表锁
07、MySQL进阶:共享锁和排它锁初探
08、MySQL进阶:索引优化案例实操
09、MySQL进阶:索引下推IndexConditionPushdown初探
10、MySQL进阶:使用trace工具来窥探MySQL是如何选择执行计划的
11、MySQL进阶:orderby和groupby优化初探
12、MySQL进阶:分页查询优化的两个案例解析
13、MySQL进阶:Join关联查询优化
14、MySQL进阶:In和Exists的优化案例讲解
15、MySQL进阶:存储引擎初探
16、MySQL进阶:体系结构初探
17、MySQL进阶:解读MySQL事务与锁机制
18、MySQL进阶:多版本控制MVCC机制初探
19、MySQL进阶:并发事务问题及解决方案
20、MySQL进阶:锁机制初探
21、MySQL进阶:高效的设计MySQL库表
22、MySQL进阶:库表设计之IP和TIMESTAMP的处理
23、MySQL进阶:orderby出现usingfilesort根因分析及优化
24、MySQL进阶:canal实现mysql数据同步到redis|实现自定义canal客户端
本文档使用 MrDoc 发布
-
+
首页
02、MySQL进阶:MySQL不同存储引擎下索引的实现
**Pre** ------------ MySQL中,索引属于存储引擎级别的概念,不同存储引擎对索引的实现方式是不同的,我们这里主要讨论MyISAM和InnoDB两个存储引擎的索引实现方式。 ### **MyISAM索引实现** ------------ **非聚簇(非聚集)索引** 我们建立一个myIsam存储引擎的表,看磁盘上的文件存储如下  我这个是8.0的MYSQL, 5.7版本 不是sdi结尾的文件,而是frm (framework) 可以看到MyISAM存储引擎的索引文件 MYI 和数据文件 MYD 是分离的(非聚集) 这就是非聚簇索引的含义, MYI 和 MYD 分开存储 ,同样的 InnoDB都存在.idb文件中,所以InnoDB存储引擎的索引就是聚簇索引。 **索引原理图** ------------ **MyISAM引擎使用B+Tree作为索引结构,叶节点的data域存放的是数据记录的地址。** 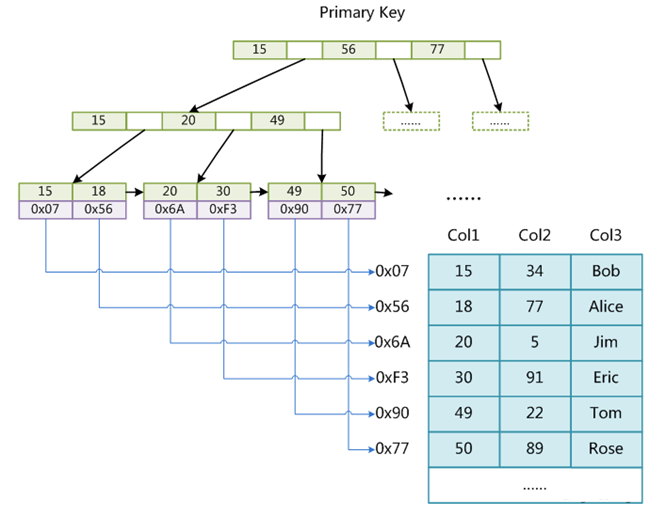 上图就是 MyISAM索引的原理图。 上图一共有三列,假设我们以Col1为主键,则上图是一个MyISAM表的主索引(Primary key)示意。可以看出**MyISAM的索引文件仅仅保存数据记录的地址** 在MyISAM中,主索引和辅助索引(Secondary key)在结构上没有任何区别,只是主索引要求key是唯一的,而辅助索引的key可以重复。 如果我们在Col2上建立一个辅助索引,则此索引的结构如下图所示: 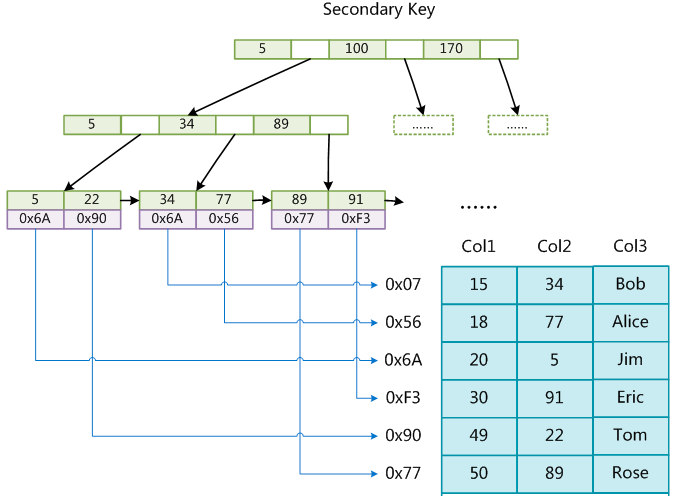 **同样也是一颗B+Tree,data域保存数据记录的地址。** 因此,MyISAM中索引检索的算法为首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其data域的值,然后以data域的值为地址,去另外一个文件中MYD读取相应数据记录。 MyISAM的索引方式也叫做“非聚集”的,之所以这么称呼是为了与InnoDB的聚集索引区分。 ------------ ### **InnoDB索引实现** ------------ **聚簇(聚集)索引** 建立一个innodb存储引擎的表,看磁盘上的数据文件如下  这个ibd就是 数据和索引,这两个存储在一个文件中 第一个重大区别是**InnoDB的数据文件本身就是索引文件** ,因为就只有一个ibd文件啊。 - MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。 - InnoDB中,表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。 InnoDB也使用B+Tree作为索引结构,但具体实现方式却与MyISAM 不同。 ### **索引原理图** 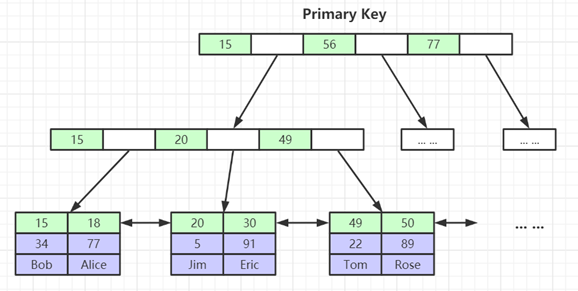 上图就是InnoDB主索引(同时也是数据文件)的示意图,可以看到**叶节点包含了完整的数据记录**。这种索引叫做聚集索引。 ------------ 第二个与MyISAM索引的不同是InnoDB的辅助索引data域存储相应记录主键的值而不是地址。换句话说,**InnoDB的所有辅助索引都引用主键作为data域** 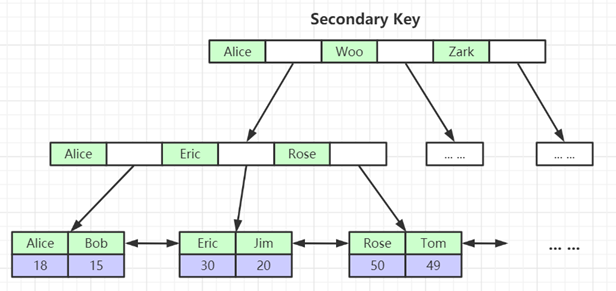 上图为定义在Col3上的一个辅助索引 观察叶子节点 : data域存储相应记录主键的值而不是地址 Col3字段上的索引,以英文字符的ASCII码作为比较准则。 聚集索引这种实现方式使得按主键的搜索十分高效,但是辅助索引搜索需要检索两遍索引:首先检索辅助索引获得主键,然后用主键到主索引中检索获得记录。 ### **常见面试题** ------------ **为什么建议InnoDB表必须建主键,并且推荐使用整型的自增主键?** 因为InnoDB的数据文件本身要按主键聚集,所以InnoDB要求表必须有主键(MyISAM可以没有),如果没有显式指定,则MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则MySQL自动为InnoDB表生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整形。 至于是整型,主要是构建B+Tree的时候,从左到右递增的属性,你如果用过UUID,不仅占用空间,还要转换成assic码进行比较,效率自然不行。 **为什么非主键索引结构叶子节点存储的是主键值?(一致性和节省存储空间)** 知道了InnoDB的索引实现后,就很容易明白为什么不建议使用过长的字段作为主键,因为所有辅助索引都引用主索引,过长的主索引会令辅助索引变得过大,占用空间。 再比如用非单调(可重复)的字段作为主键在InnoDB中是不推荐的,因为InnoDB数据文件本身是一颗B+Tree,可重复的主键会造成在插入新记录时数据文件为了维持B+Tree的特性而频繁的分裂调整,十分低效,所以推荐使用自增主键。 参考: [http://blog.codinglabs.org/articles/theory-of-mysql-index.html](http://blog.codinglabs.org/articles/theory-of-mysql-index.html "http://blog.codinglabs.org/articles/theory-of-mysql-index.html")
李智
2025年3月17日 13:31
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
分享
链接
类型
密码
更新密码