MySQL进阶
01、MySQL进阶:剖析MySQL索引底层数据结构
02、MySQL进阶:MySQL不同存储引擎下索引的实现
03、MySQL进阶:Explain深度剖析
04、MySQL进阶:践行索引优化
05、MySQL进阶:锁等待及死锁初探
06、MySQL进阶:无索引行锁升级为表锁
07、MySQL进阶:共享锁和排它锁初探
08、MySQL进阶:索引优化案例实操
09、MySQL进阶:索引下推IndexConditionPushdown初探
10、MySQL进阶:使用trace工具来窥探MySQL是如何选择执行计划的
11、MySQL进阶:orderby和groupby优化初探
12、MySQL进阶:分页查询优化的两个案例解析
13、MySQL进阶:Join关联查询优化
14、MySQL进阶:In和Exists的优化案例讲解
15、MySQL进阶:存储引擎初探
16、MySQL进阶:体系结构初探
17、MySQL进阶:解读MySQL事务与锁机制
18、MySQL进阶:多版本控制MVCC机制初探
19、MySQL进阶:并发事务问题及解决方案
20、MySQL进阶:锁机制初探
21、MySQL进阶:高效的设计MySQL库表
22、MySQL进阶:库表设计之IP和TIMESTAMP的处理
23、MySQL进阶:orderby出现usingfilesort根因分析及优化
24、MySQL进阶:canal实现mysql数据同步到redis|实现自定义canal客户端
本文档使用 MrDoc 发布
-
+
首页
01、MySQL进阶:剖析MySQL索引底层数据结构
什么是索引? 通俗的说就是为了提高效率专门设计的一种 排好序的数据结构。 怎么理解呢? 举个例子哈 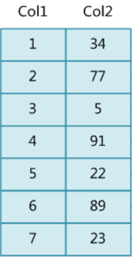 如上数据 ,假设有个SQL ```python select * from t where col2 = 22 ; ``` 如果没有索引的话,是不是得逐行进行全表扫描,走磁盘IO… 如果加上一个合适的索引呢? 比如用一个二叉树 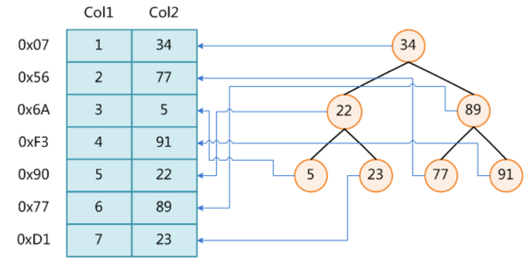 二叉树我们知道,右边的比左边大 那执行刚才的SQL的话,第一条记录是34 ,那我们查找的是22, 是不是就只要到它的左边查找即可,因为右边的数据都比34大,肯定没有22 ,找到22 以后, 搞定 ,I/O次数是不是比刚才的全表扫描的次数少很多,那效率自然就高了。 ### **索引的数据结构选型** ------------ **二叉树 ?** 可以用二叉树吗? 我们知道MySQL一般都有自增主键 ,id之类的字段 我们来演示下使用二叉树来存储这种自增的数据的话,会怎样? 演示地址:[https://www.cs.usfca.edu/~galles/visualization/BST.html](https://www.cs.usfca.edu/~galles/visualization/BST.html "https://www.cs.usfca.edu/~galles/visualization/BST.html") 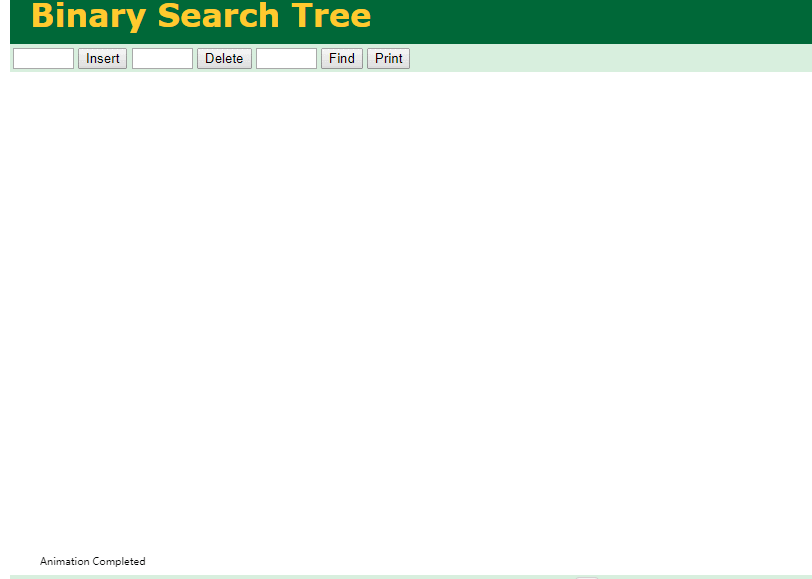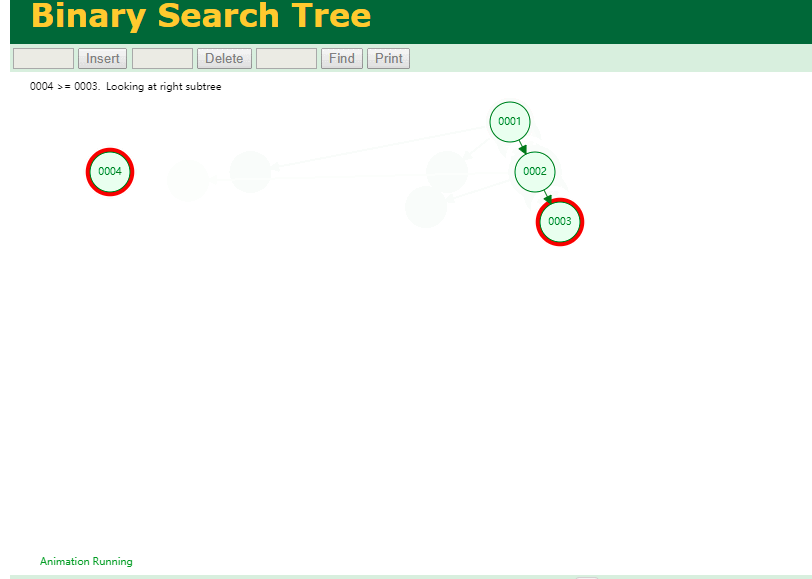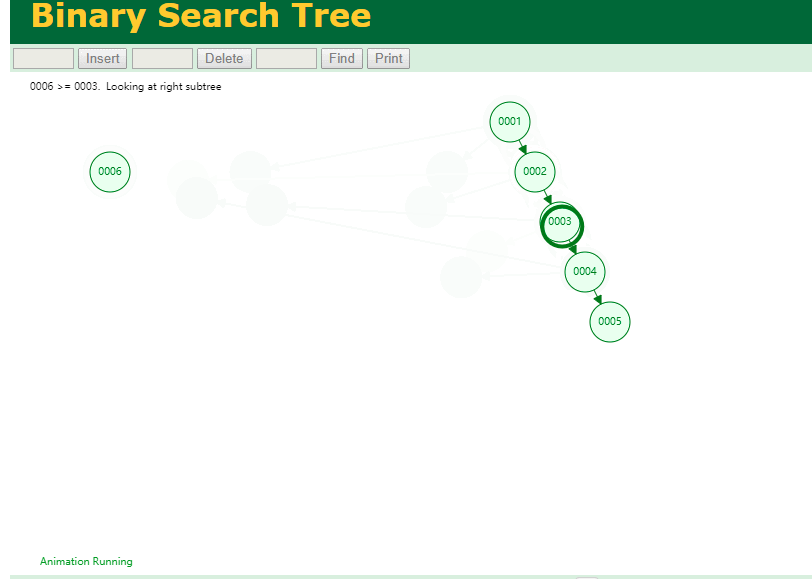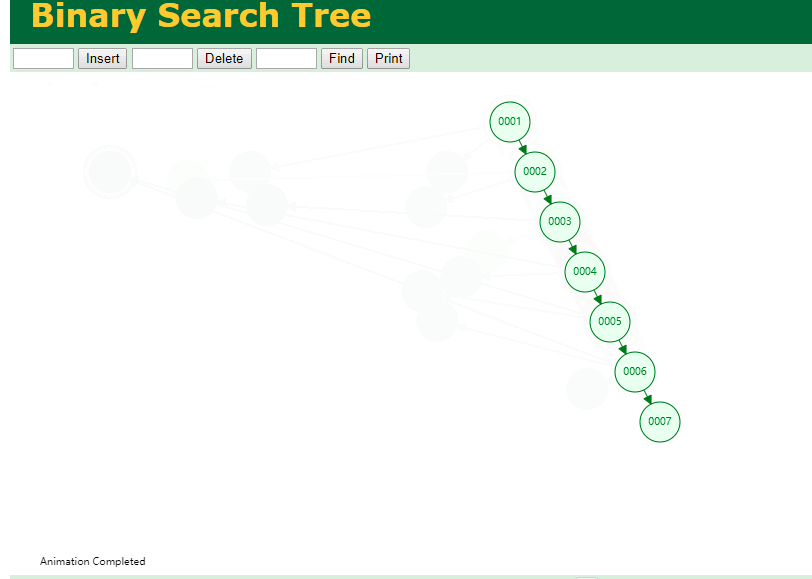 那查询 ```python select * from t where id = 7 ``` 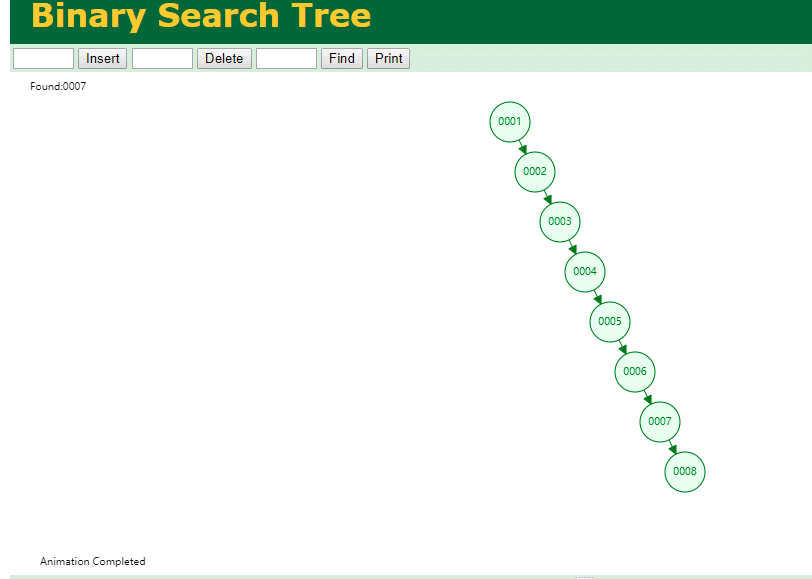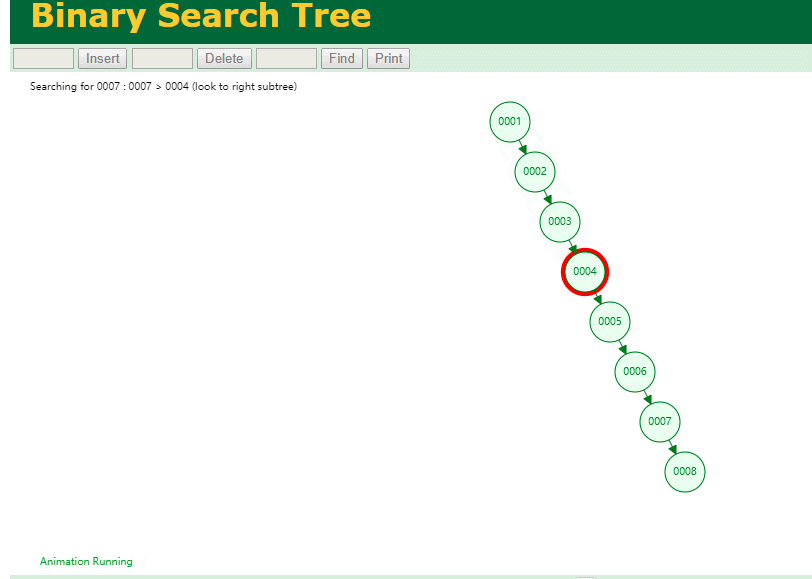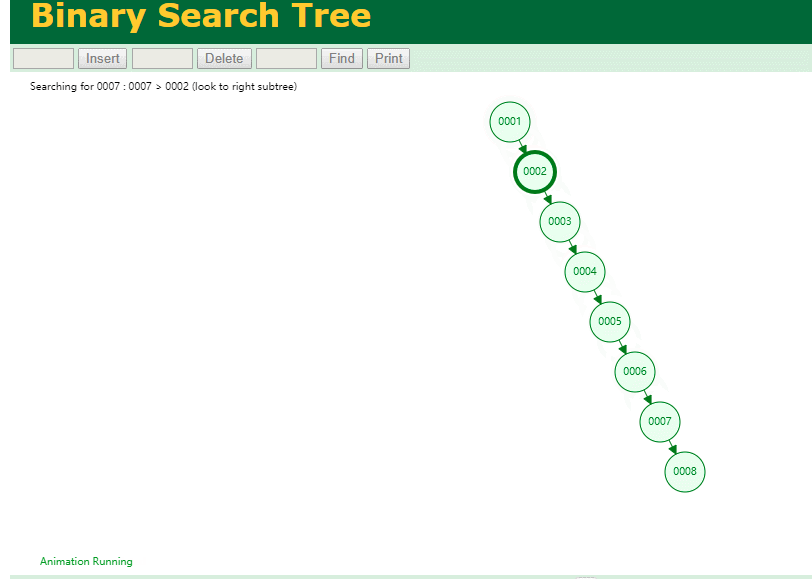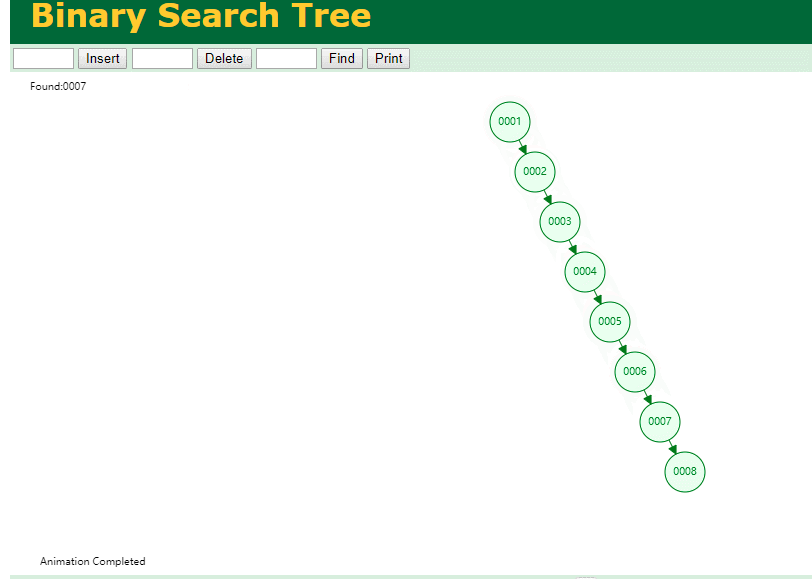 **自增主键**的时候 这个二叉树已经**退化成链表了**。。。。。 想想,一个几百万数据量的表 ,查找某个大一点的id , 逐个查找比对 (这些数据也是存储在磁盘上的,还得从磁盘上捞啊) 这I/O 这效率可想而知吧… 二叉树pass ,不考虑了 既然退化成链表了,那试试带有平衡功能的树 二叉平衡树 (红黑树)? 自增主键, 退化为为链表 ------------ **红黑树 ?** 二叉树既然在某些情况下会退化成链表, 那如果这棵树能自动平衡呢? 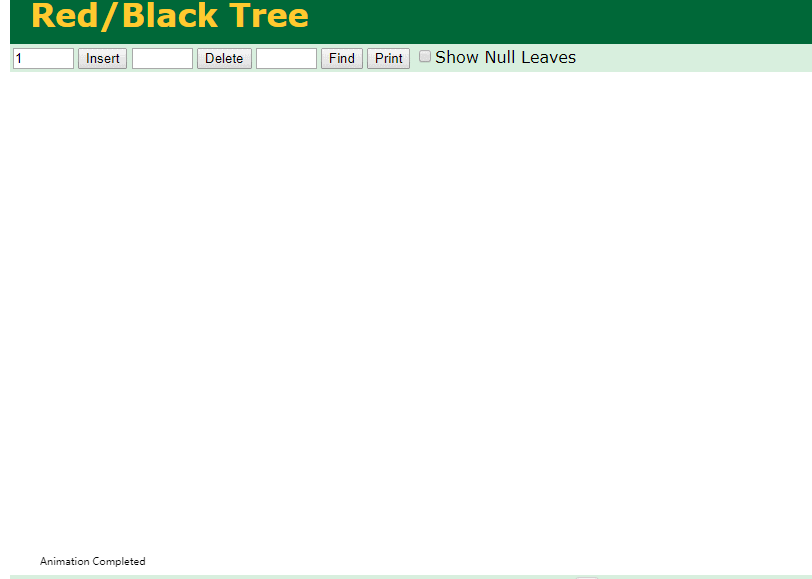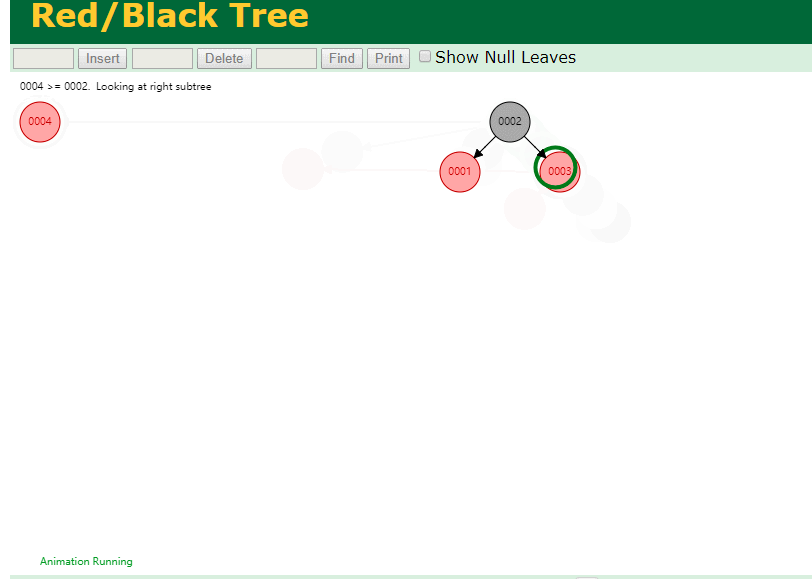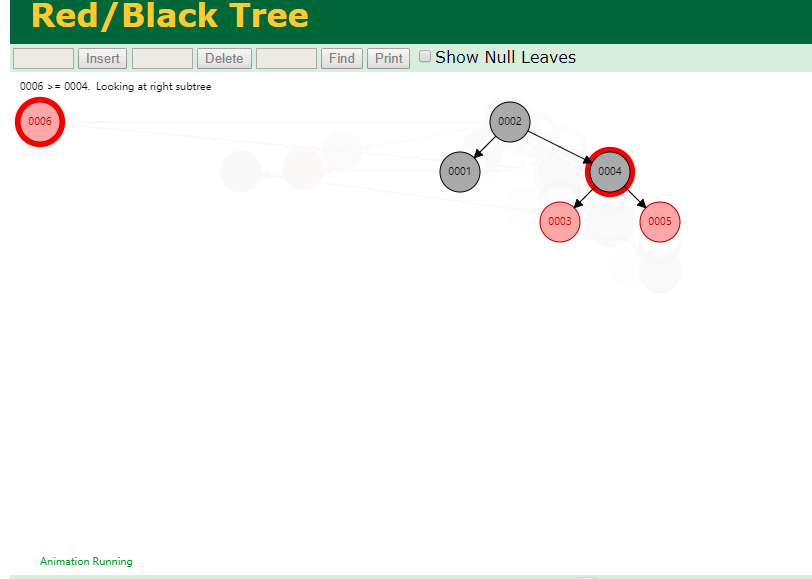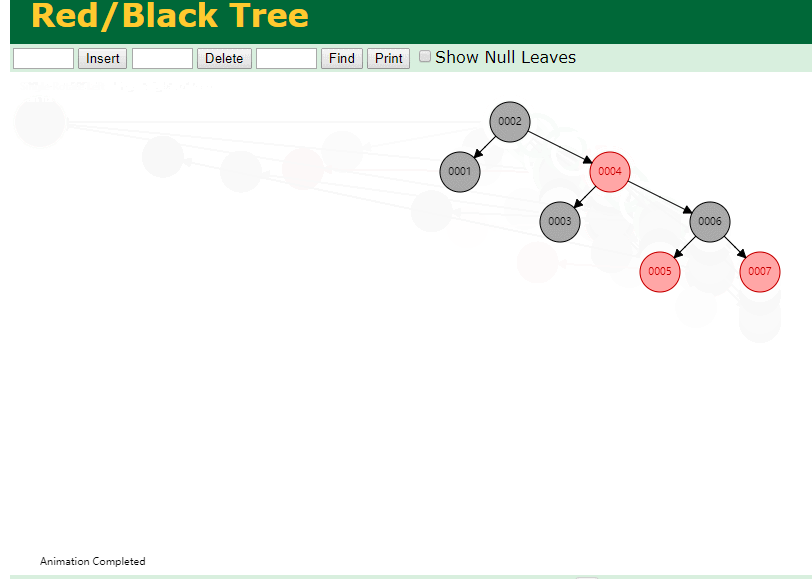 这样子是不可能变成链表了, 同样查询 ```python select * from t where id = 7 ``` 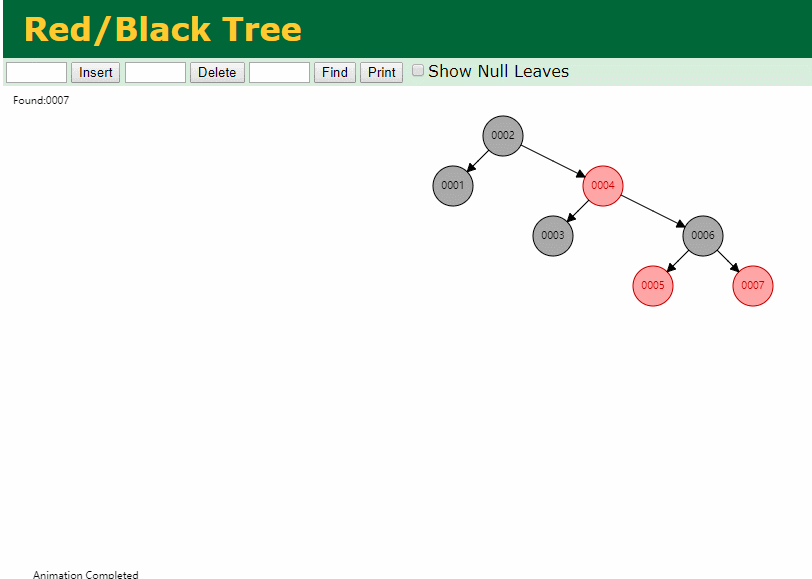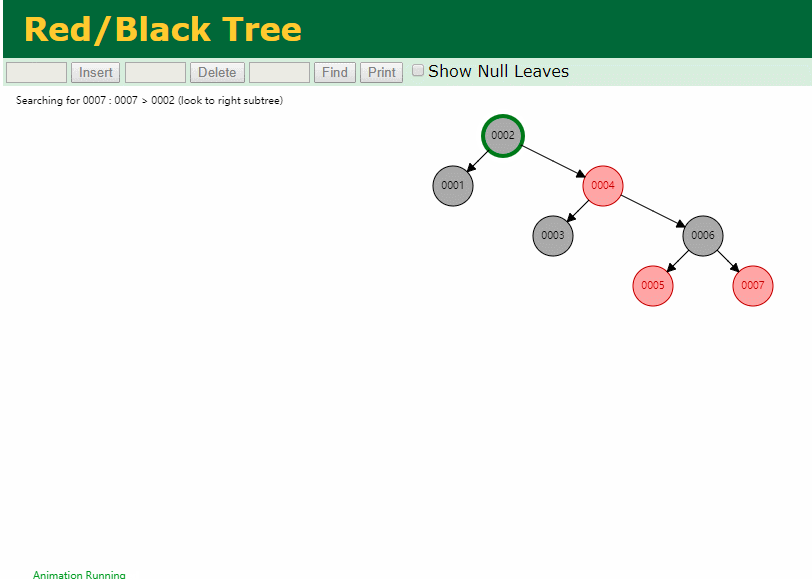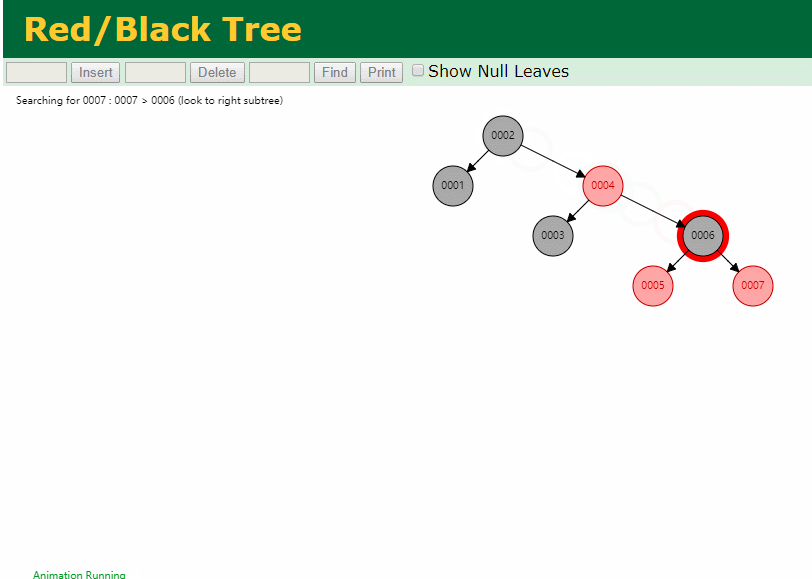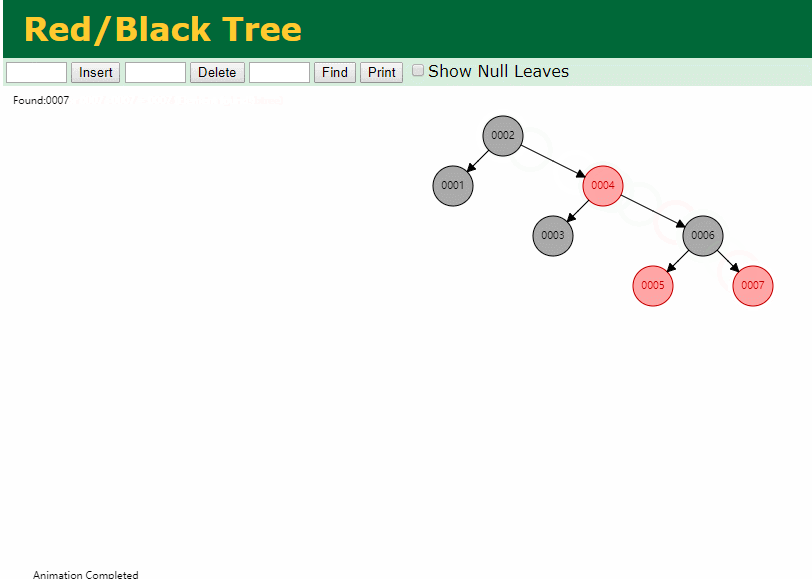 三次磁盘I/O即可找到, 比刚才二叉树的七次是少了些哈 ,自然查找效率也比二叉树高了 可如果数据量几百万 上千万呢? 这棵树 得多高哇。。。 数据量大, 树高问题 那既然树高不好, 是不是如果可以控制树的高度(比如 3 到4层的高度,这样查询起来还能接受),让每一层能存储更多的数据,然后再分裂,这样的话数据量相乘起来,也是不少了对吧,这样就能存储更多的数据,这样会不会好一点? ----> B-Tree ------------ **B-Tree ?** - 叶节点具有相同的深度, 叶节点之间指针为空 - 所有索引元素不重复 - 节点中的数据索引从左到右递增排列 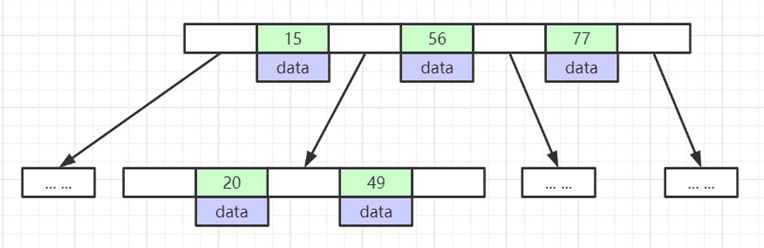 叶子节点之间的没有指针,区别于B+树。 data存储的是数据对应的磁盘地址, k-v结构。 我们来看下B-Tree的插入 (Max.Degree 设置为3 即 元素到了3个就分裂 ) 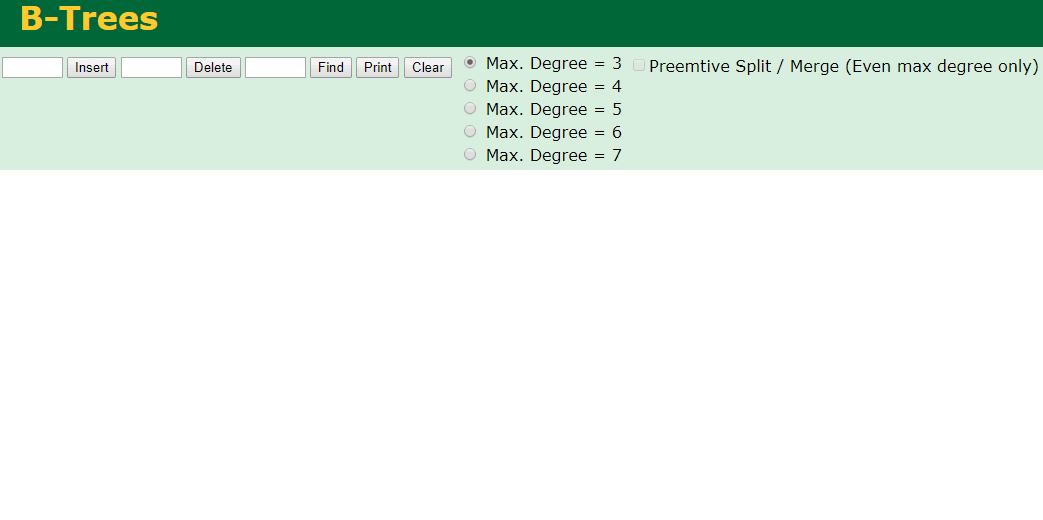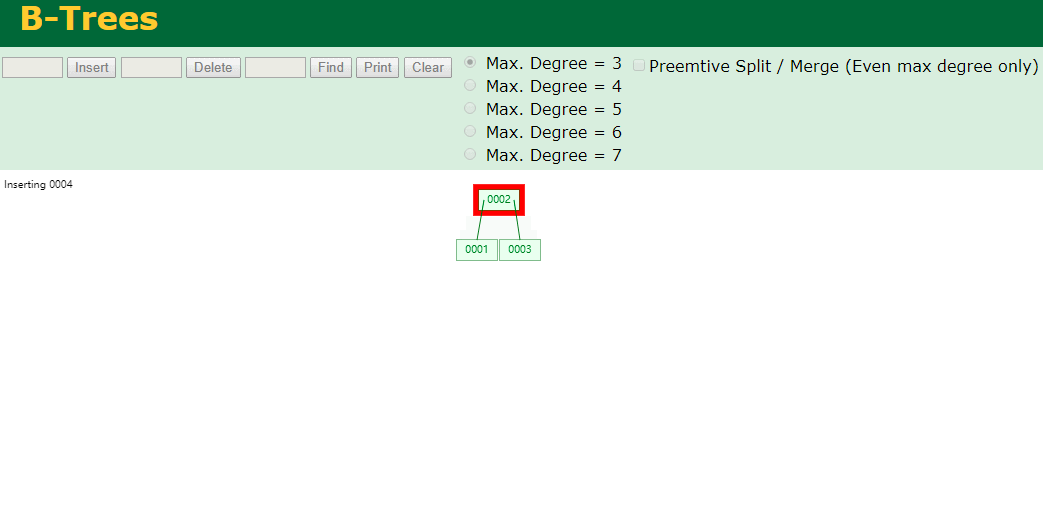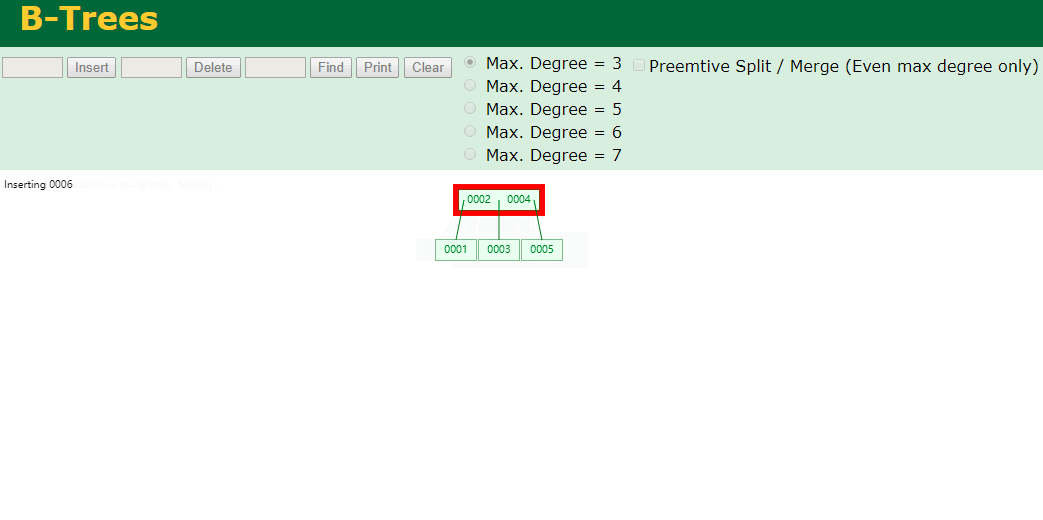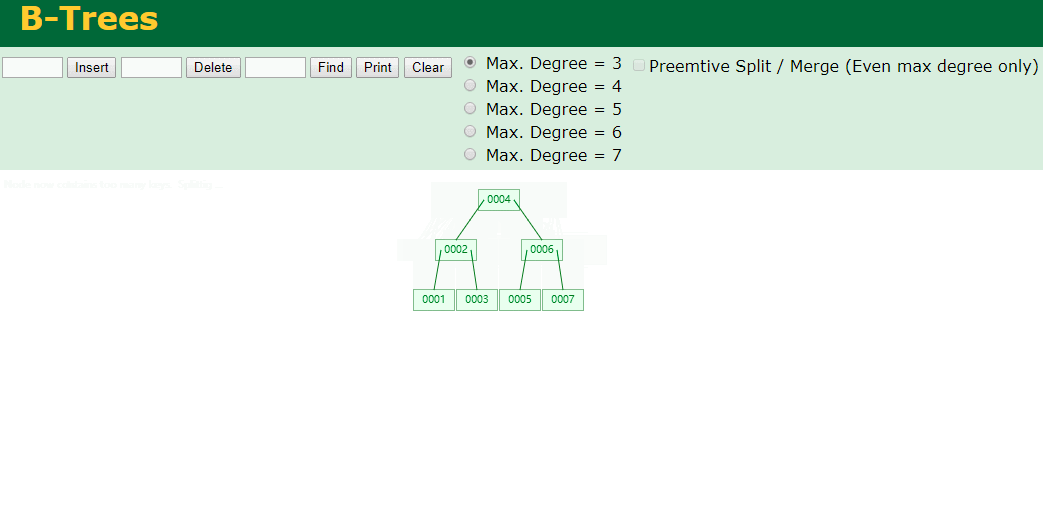 查找一下 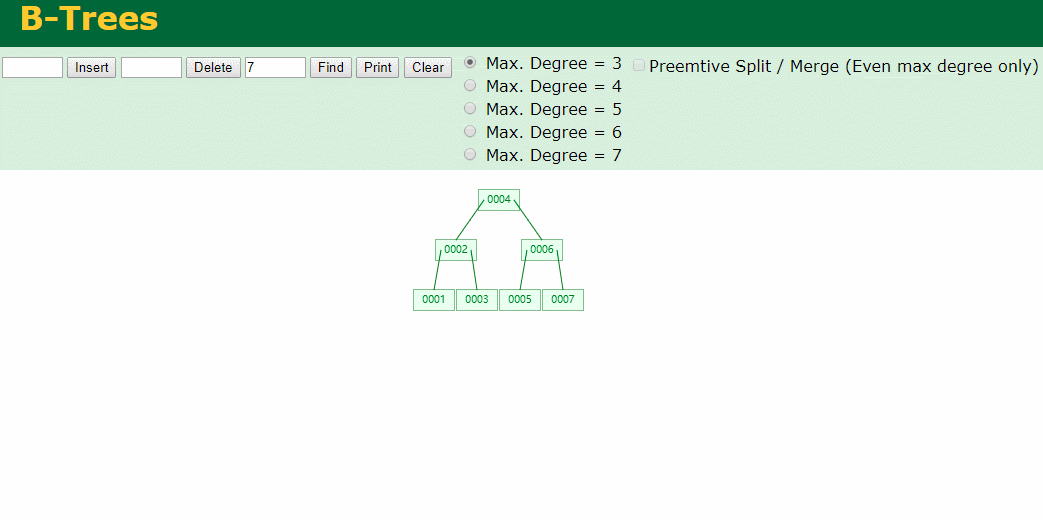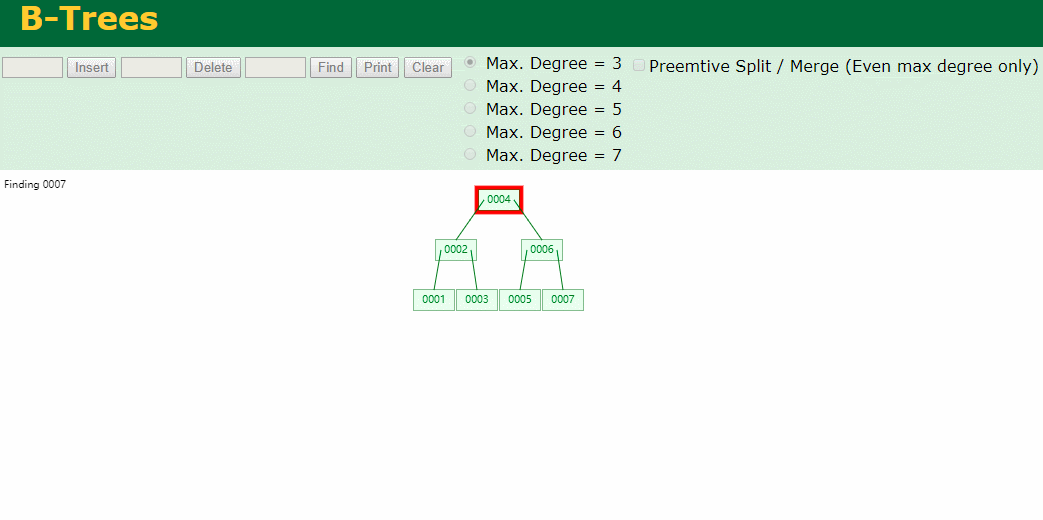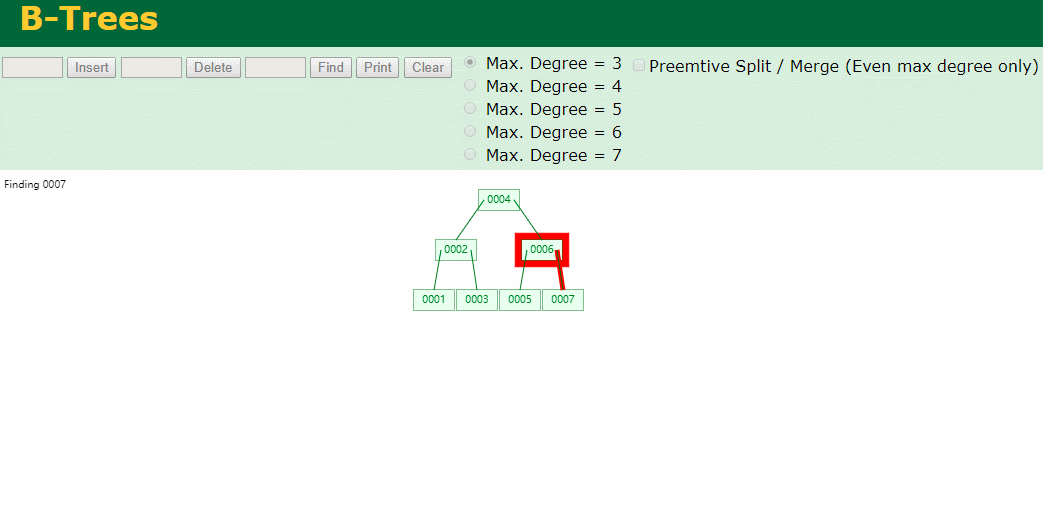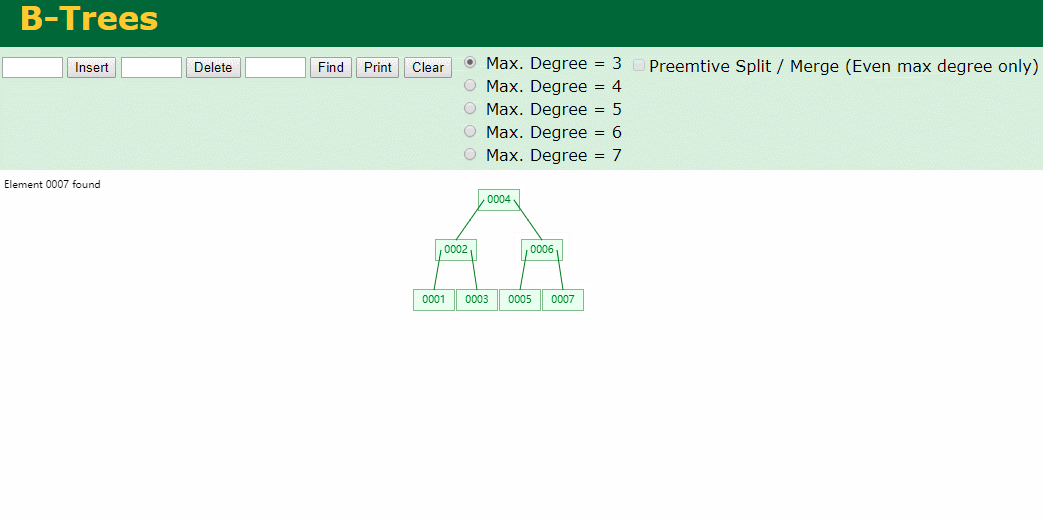 3次 MySQL也没有使用B-Tree , 因为 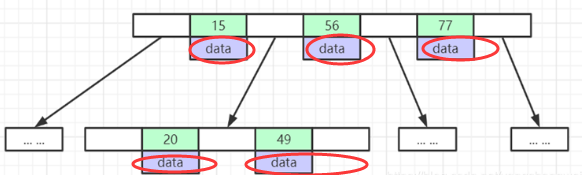 除了存储索引以外,还存储了data(数据对应的磁盘地址) , 为了更多的存储数据,MySQL对B-Tree进行了很多改造 由此演进出了 B+Tree ,**将data部分仅保留在叶子节点上,这样的话同等的页可以存储更多而索引数据。** ------------ **B+Tree** - 非叶子节点不存储data,只存储索引(冗余),可以放更多的索引 - 叶子节点包含所有索引字段 - 叶子节点用指针连接,提高区间访问的性能 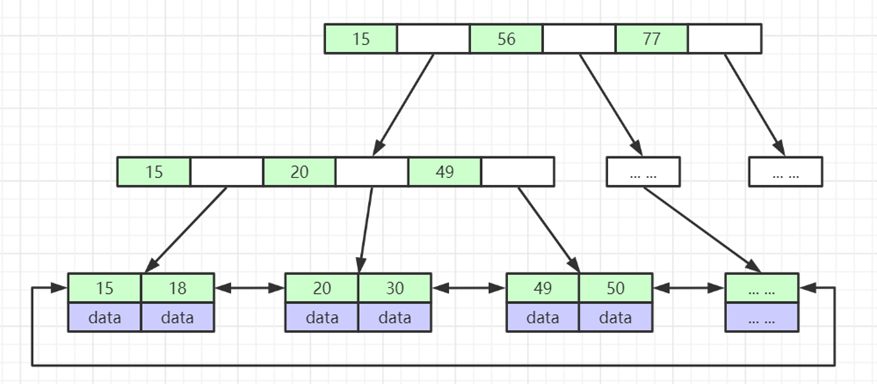 数据仅存储在叶子节点, data可能是磁盘地址也可能是其他的列数据,这个和存储引擎有关系。 叶子节点之间有指针相连。 我们来算下 3层高的B+Tree能存储多少数据结构 假设是BigInt类型的数据 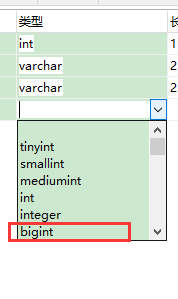 BigInt 占 8个字节 ,同时还是用6个字节存储了它指向的数据的物理地址 MySQL在使用innodb引擎的时候页大小默认是16K ,查询如下 ```python mysql> SHOW GLOBAL STATUS like 'Innodb_page_size'; +------------------+-------+ | Variable_name | Value | +------------------+-------+ | Innodb_page_size | 16384 | +------------------+-------+ 1 row in set (0.00 sec) mysql> ``` 假设树高为3 , 这样的话,第一层即可以存储 16KB * 1024 / (8B + 6B) = 1170 同样的第二层也是1170 (第二层不是叶子结点,不存储数据) 第三层,存储数据,一般情况下一行数据的大小肯定不会超过1KB,那我们就按照1KB算吧 3层高的B+Tree , 存储BitInt可以存储 1170 * 1170 * 16 = 2千1 百万。。。。这效率还是可以的哈 想一想如果是4层高的数 1170 * 1170 * 1170 * 16 = 250多亿数据。.。。。 当然了都是估算, 如果换成其他类型的数据,每个表的行数据的大小都是相关的,这也就是我们通常说的 MySQL的表到千万级别就要分库分表的理论依据了。 我们看下B+Tree的插入和查找 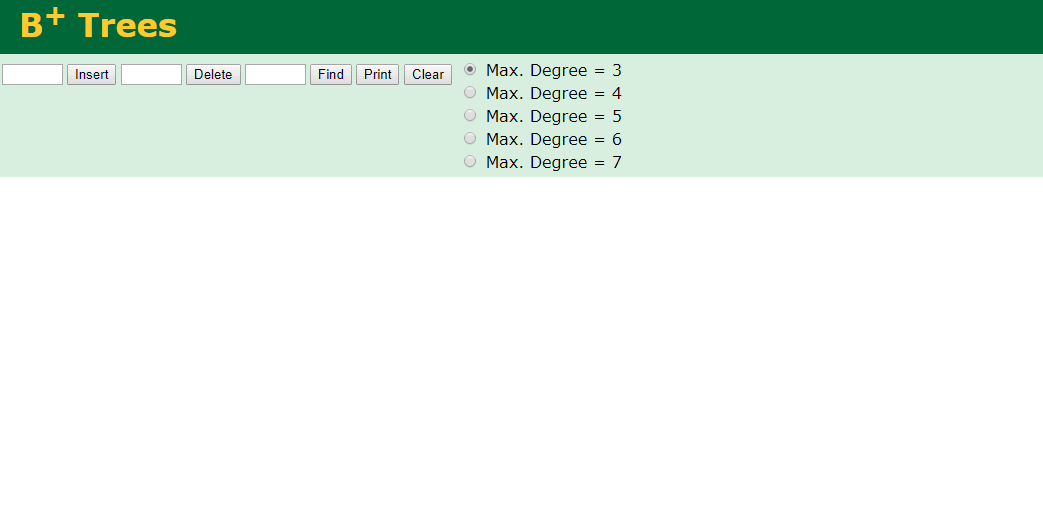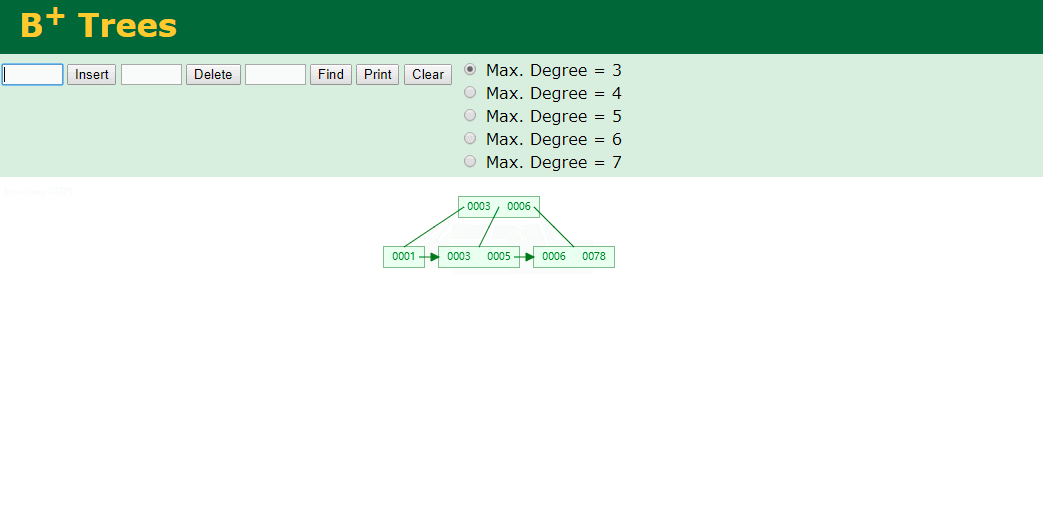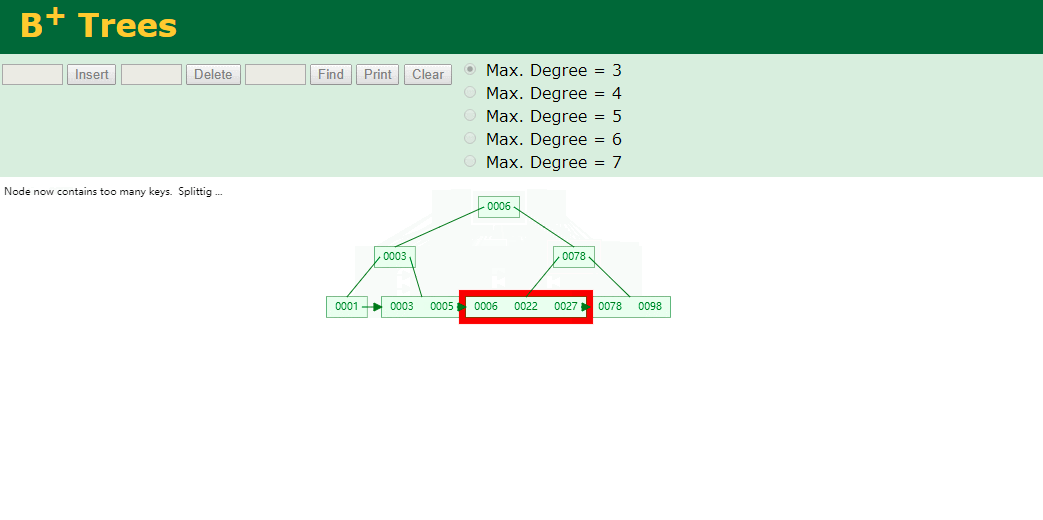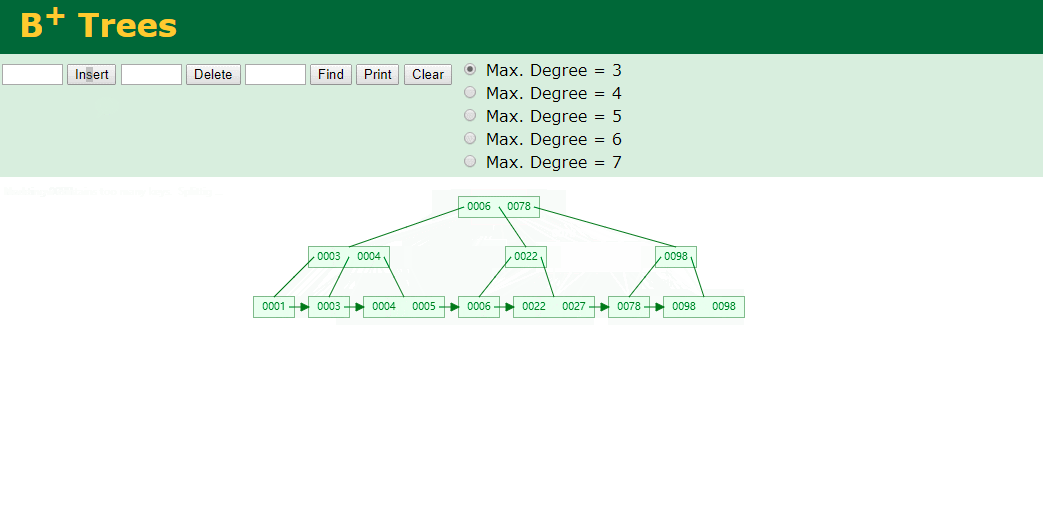 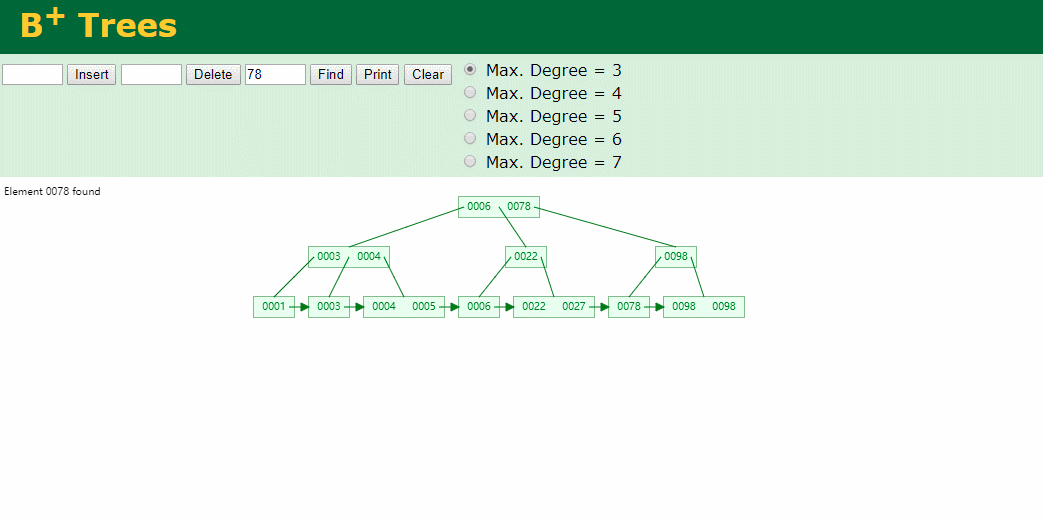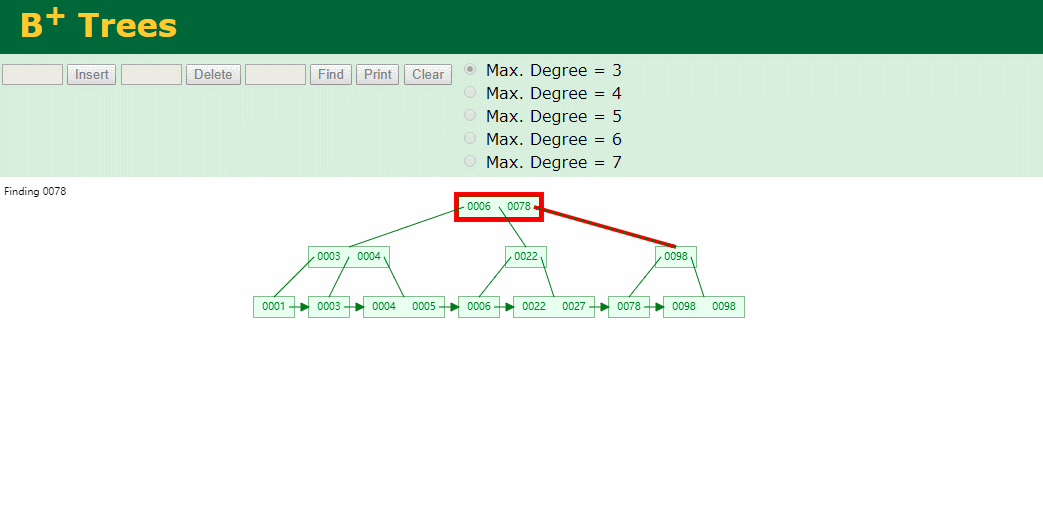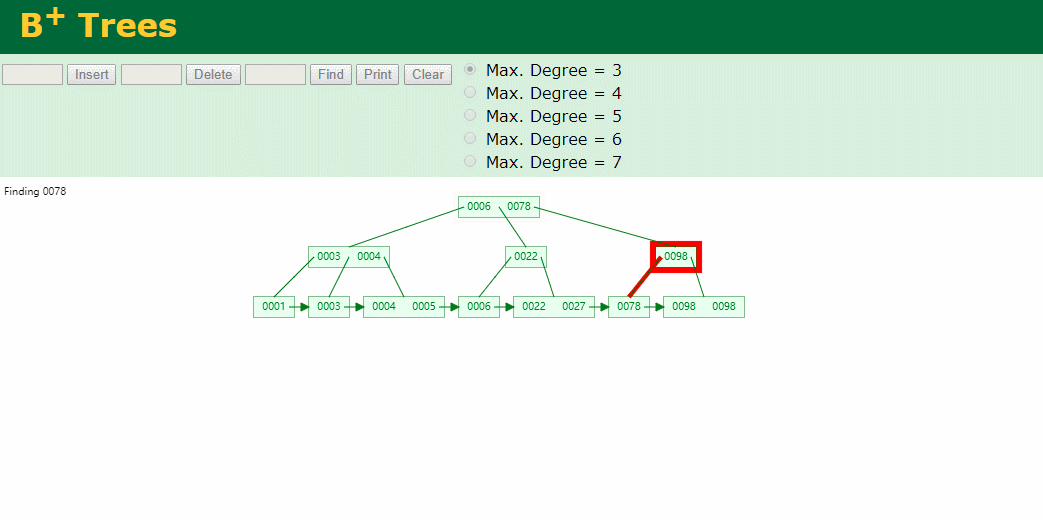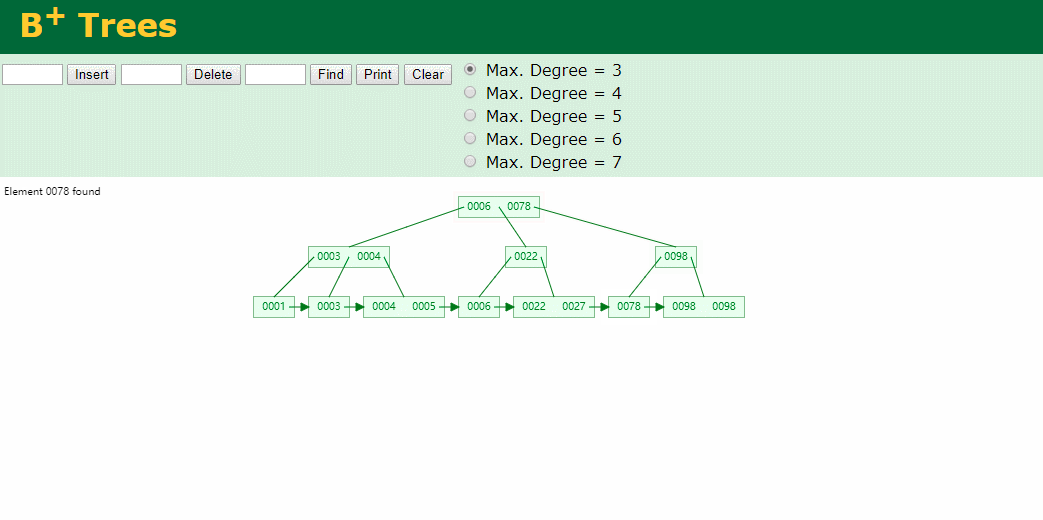 ------------ **Hash表** - 对索引的key进行一次hash计算就可以定位出数据存储的位置 - 很多时候Hash索引要比B+ 树索引更高效 - 仅能满足 “=”,“IN”,不支持范围查询 - hash冲突问题 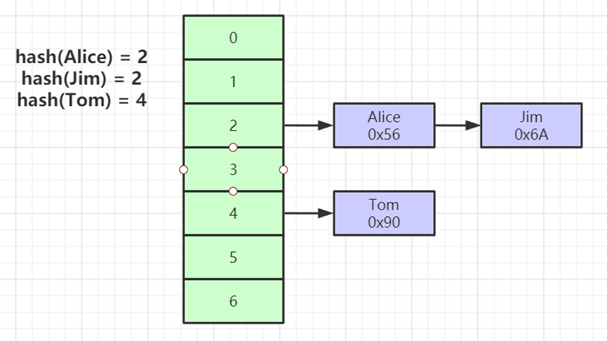 对索引字段进行hash以后, 还存储了数据对引得磁盘地址。 一般情况下,hash 比 b+tree的效率要高 ,但工作中绝大部分还是使用的B+Tree , 因为**hash对范围查找不是很友好,还要全表扫描。** 为啥B+Tree 支持范围查找? 我们知道B+Tree的叶子节点 有指针相连,从根节点找到对应的叶子节点后, 加上节点本身就是排好序的,所以范围查找就很轻松了。 B-Tree 没有指针相连,所以要想范围查找,还得从根节点重新找,效率肯定比B+树低 。
李智
2025年3月17日 13:31
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
分享
链接
类型
密码
更新密码