AI大模型学习
1、环境搭建
2、Embedding与向量数据库
3、RAG技术与应用
4、RAG高级技术与实践
5、LlamaIndex知识管理与信息检索
6、基于LlamaIndex开发的中医临床诊疗助手
7、LangChain多任务应用开发
8、Function Calling与Agent 智能体
9、Agent应用与图状态编排框架LangGraph
10、基于LangGraph实现智能分诊系统
11、MCP应用技术开发
12、AI 应用开发新范式 MCP 技术详解
13、基于LangGraph的多智能体交互系统
14、企业级智能分诊系统RAG项目
15、LangGraph与Agno-AGI深度对比分析
本文档使用 MrDoc 发布
-
+
首页
10、基于LangGraph实现智能分诊系统
# 基于LangGraph实现智能分诊系统 ## 一、项目概述 ### 1.1 项目流程 流程如下图所示: 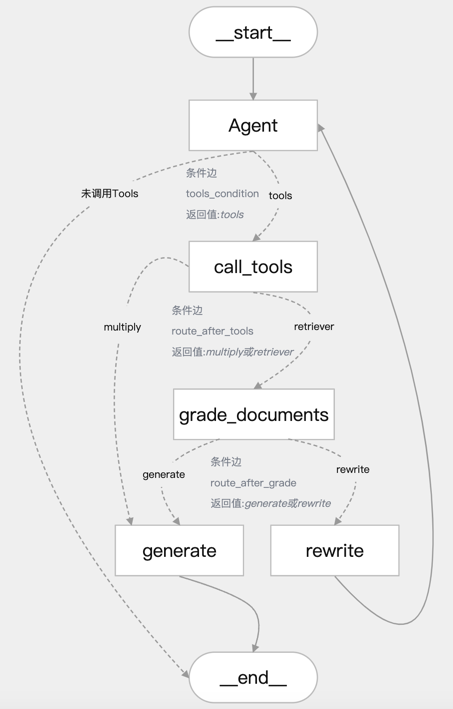 1. 用户输入问题,进入 agent 分诊节点进行用户意图分析 2. 若需调用工具,则调用 call_tools 节点进行工具并行执行;否则直接回复用户问题结束 3. 工具调用后,根据工具类型进行路由: - 检索类工具:进入 grade_documents 进行相关性评分,若相关则路由到 generate 节点,否则rewrite(最多3次) - 非检索类工具:直接路由到 generate 节点 4. 生成最终回复并输出 ### 1.2 核心功能 **(1)核心功能:基于状态图的对话流程** 定义了一个包含多个节点(Node)和边(Edge)的对话工作流,节点包括: - agent:分析用户问题并决定是否调用工具 - call_tools:并行执行工具调用 - grade_documents:评估检索到的文档与问题的相关性 - rewrite:重写用户查询以改进问题(查询意图识别查询改写) - generate:生成最终回复 - 动态路由: - tools_condition:根据用户查询意图识别是否需要调用工具 - route_after_tools:根据工具调用结果决定下一步是生成回复还是评分文档 - route_after_grade:根据文档相关性评分决定生成回复还是重写查询 **(2)工具调用与并行处理** - 工具配置:通过 ToolConfig 类管理工具列表和路由配置,支持动态路由(检索类工具路由到grade_documents,其他路由到generate) - 并行工具节点:ParallelToolNode 使用线程池(ThreadPoolExecutor)并行执行多个工具调用,提高效率,支持最大工作线程数配置(默认5) **(3)数据库与持久化存储** - 连接池管理:使用 ConnectionPool 管理 PostgreSQL 数据库连接,支持自动提交、超时设置和连接池状态监控(monitor_connection_pool) - 线程内持久化:通过PostgresSaver保存对话状态检查点 - 跨线程持久化:通过PostgresStore存储用户记忆(store_memory),支持记忆搜索和存储(如用户输入包含“记住”时保存) - 重试机制:数据库操作使用tenacity库实现重试(最多3次,指数退避等待),提高健壮性 **(4)自然语言处理与提示模板** - 语言模型:通过get_llm获取聊天模型(llm_chat)和嵌入模型(llm_embedding),用于处理用户输入和生成回复 - 提示模板:使用create_chain函数加载并缓存提示模板文件(如代理、重写、评分、生成模板),支持结构化输出(如DocumentRelevanceScore) - 消息过滤:filter_messages过滤消息,仅保留AIMessage和HumanMessage,限制最多保留5条历史消息 **(5)日志与错误处理** - 日志记录:使用 logging 模块和 ConcurrentRotatingFileHandler 记录详细日志(DEBUG级别),支持文件轮转(5MB,3个备份),后续可以自己实现日志归档 - 错误处理:多层次异常捕获(如数据库连接、工具调用、状态访问等),记录错误并提供默认路由或提示用户 **(6)用户交互与响应输出** - 主循环:main 函数实现交互式对话,用户输入后通过graph_response处理并输出响应,支持退出命令(quit、exit、q) - 响应区分:区分工具输出(显示工具名称)和大模型输出(普通回复),提升用户体验 **(7)辅助功能** 可视化:通过save_graph_visualization将状态图保存为PNG文件,便于调试 配置管理:通过Config类统一管理日志文件路径、数据库URI、提示模板路径等配置 ## 二、项目环境准备 ### 2.1 创建Conda环境 ```bash conda create -n L1-project-2 python=3.11 ``` ### 2.2 安装项目依赖库 ```bash pip install langgraph==0.2.74 pip install langchain-openai==0.3.6 pip install langchain-community==0.3.19 pip install langchain-chroma==0.2.2 pip install pdfminer pip install pdfminer.six pip install nltk==3.9.1 pip install psycopg2==2.9.10 pip install concurrent-log-handler==0.9.25 pip install langgraph-checkpoint-postgres pip install psycopg psycopg-pool ``` ### 2.3 使用Docker运行PostgreSQL数据库 1)进入官网 https://www.docker.com/ 下载安装Docker Desktop软件并安装,安装完成后打开软件 Docker Desktop 安装参考:https://www.cnblogs.com/yinzhengjie/p/17889373.html 2)打开命令行终端,找到 PostgreSQL 的 docker 配置文件 `docker-compose.yml` 3)运行 `docker-compose up -d` 命令后台启动 PostgreSQL 数据库服务。运行成功后可在Docker Desktop软件中进行管理操作或使用命令行操作或使用指令 *若要删除容器在命令行终端中运行 `docker-compose down --volumes`* 4)因为 LangGraph 中 PostgresStore 需要使用到 pgvector,因此需要在docker容器中按照如下步骤进行操作,直接使用Docker Desktop软件中进行操作 1. 安装依赖 ```shell apt update apt install -y git build-essential postgresql-server-dev-15 ``` 2. 编译并安装 pgvector ```shell git clone --branch v0.7.0 https://github.com/pgvector/pgvector.git cd pgvector make make install ``` 3. 验证安装,检查扩展文件是否安装成功 ```shell ls -l /usr/share/postgresql/15/extension/vector* ``` 最后一行显示:**`/usr/share/postgresql/15/extension/vector.control`** 表示安装成功! 4. 系统环境中需要安装PostgreSQL 的开发库 **`libpq`** ,因为 psycopg 需要它来编译或运行,根据自己的操作系统选择进行安装。 1)在 Windows 上安装 PostgreSQL 的开发库 **`libpq`**(即客户端库和头文件),可以通过以下两种方法实现: --- ### 方法 1:安装完整的 PostgreSQL 服务器 这是最简单的方法,安装 PostgreSQL 时会自动包含 `libpq` 库和开发文件。 #### 步骤: 1. **下载 PostgreSQL 安装包** 访问 PostgreSQL 官方下载页面: [https://www.postgresql.org/download/windows/](https://www.postgresql.org/download/windows/) 选择适合你系统的版本(如 **PostgreSQL 15.x**)。 2. **运行安装程序** - 双击下载的 `.exe` 文件(如 `postgresql-15.x-x-windows-x64.exe`)。 - 在安装向导中,**勾选以下组件**: - ✅ **PostgreSQL Server**(可选,如果不需要数据库服务可跳过) - ✅ **Command Line Tools**(包含 `psql` 等客户端工具) - ✅ **pgAdmin**(可选,图形化管理工具) - ✅ **Stack Builder**(可选,用于安装额外插件) 3. **选择安装位置** 默认路径为 `C:\Program Files\PostgreSQL\15`,保持默认或自定义路径。 4. **设置密码** 为默认的 `postgres` 用户设置密码。 5. **完成安装** 安装完成后,`libpq` 库会自动包含在以下目录中: ```plaintext # libpq 动态链接库(DLL) C:\Program Files\PostgreSQL\15\bin\libpq.dll # 头文件(C 头文件) C:\Program Files\PostgreSQL\15\include ``` --- ### 方法 2:仅安装 PostgreSQL 客户端库(无需安装服务器) 如果不需要完整的 PostgreSQL 服务,可以直接下载独立的客户端库。 #### 步骤: 1. **下载 PostgreSQL 客户端库** 访问 EDB(EnterpriseDB)的独立客户端工具下载页面: [https://www.enterprisedb.com/download-postgresql-binaries](https://www.enterprisedb.com/download-postgresql-binaries) 下载名为 **`postgresql-15.x-x-windows-x64-binaries.zip`** 的压缩包。 2. **解压文件** 将压缩包解压到目标目录(如 `C:\pgsql`)。 3. **配置环境变量** 将 `libpq.dll` 所在的路径添加到系统环境变量 `PATH`: ```plaintext # 假设解压到 D:\pgsql D:\pgsql\bin ``` --- ### 验证安装 1. **检查 `libpq.dll`** 打开命令提示符,运行以下命令确认 `libpq.dll` 是否存在: ```bash where libpq.dll ``` 输出应类似: ```plaintext C:\Program Files\PostgreSQL\15\bin\libpq.dll ``` 2. **检查头文件** 确认头文件目录(如 `C:\Program Files\PostgreSQL\15\include`)包含以下文件: ```plaintext libpq-fe.h ``` --- ### 在 Python 中使用 `psycopg` 的注意事项 如果使用 Python 库 `psycopg`(如 `psycopg2` 或 `psycopg3`),确保: 1. 系统能找到 `libpq.dll`。如果遇到 `ImportError`,将 PostgreSQL 的 `bin` 目录(如 `C:\Program Files\PostgreSQL\15\bin`)添加到 `PATH` 环境变量。 2. 使用 `psycopg[binary]` 包(推荐): ```bash pip install psycopg[binary] ``` --- ### 总结 - **推荐方法**:直接安装完整的 PostgreSQL 服务器(方法 1),省去手动配置的麻烦。 - **轻量级方法**:如果只需客户端库,使用独立的二进制包(方法 2)。 --- 2)MacOS(使用 Homebrew):`brew install postgresql` 5. 使用Navicat数据库客户端软件远程登陆进行可视化操作 下载 Navicat Premium: https://www.navicat.com.cn/download/navicat-premium ## 三、项目配置管理 ### 3.1 全局配置管理类:`Config` ```python import os class Config: """统一的配置类,集中管理所有常量""" # prompt文件路径 PROMPT_TEMPLATE_TXT_AGENT = "prompts/prompt_template_agent.txt" PROMPT_TEMPLATE_TXT_GRADE = "prompts/prompt_template_grade.txt" PROMPT_TEMPLATE_TXT_REWRITE = "prompts/prompt_template_rewrite.txt" PROMPT_TEMPLATE_TXT_GENERATE = "prompts/prompt_template_generate.txt" # Chroma 数据库配置 CHROMADB_DIRECTORY = "chromaDB" CHROMADB_COLLECTION_NAME = "demo001" # 日志持久化存储 LOG_FILE = "output/app.log" MAX_BYTES=5*1024*1024, BACKUP_COUNT=3 # 数据库 URI,默认值 DB_URI = os.getenv("DB_URI", "postgresql://kevin:123456@localhost:5432/postgres?sslmode=disable") # openai:调用gpt模型, qwen:调用阿里通义千问大模型, oneapi:调用oneapi方案支持的模型, ollama:调用本地开源大模型 LLM_TYPE = "qwen" # API服务地址和端口 HOST = "0.0.0.0" PORT = 8012 ``` ### 3.2 大模型配置管理类:`llms` 用于配置管理大模型服务商提供的LLM和Embedding Model ```python import os import logging from langchain_openai import ChatOpenAI,OpenAIEmbeddings # 设置日志模版 logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s') logger = logging.getLogger(__name__) # 模型配置字典 MODEL_CONFIGS = { "openai": { "base_url": os.getenv("OPENAI_BASE_URL"), "api_key": os.getenv("OPENAI_API_KEY"), "chat_model": "gpt-4o", "embedding_model": "text-embedding-3-small" }, "oneapi": { "base_url": "http://139.224.72.218:3000/v1", "api_key": os.getenv("DASHSCOPE_API_KEY"), "chat_model": "qwen-max", "embedding_model": "text-embedding-v1" }, "qwen": { "base_url": "https://dashscope.aliyuncs.com/compatible-mode/v1", "api_key": os.getenv("DASHSCOPE_API_KEY"), "chat_model": "qwen-max", "embedding_model": "text-embedding-v1" }, "ollama": { "base_url": "http://localhost:11434/v1", "api_key": "ollama", "chat_model": "qwen3:latest", "embedding_model": "bge-m3:latest" } } # 默认配置 DEFAULT_LLM_TYPE = "qwen" DEFAULT_TEMPERATURE = 0.1 class LLMInitializationError(Exception): """自定义异常类用于LLM初始化错误""" pass def initialize_llm(llm_type: str = DEFAULT_LLM_TYPE) -> tuple[ChatOpenAI, OpenAIEmbeddings]: """ 初始化LLM实例 Args: llm_type (str): LLM类型,可选值为 'openai', 'oneapi', 'qwen', 'ollama' Returns: ChatOpenAI: 初始化后的LLM实例 Raises: LLMInitializationError: 当LLM初始化失败时抛出 """ try: # 检查llm_type是否有效 if llm_type not in MODEL_CONFIGS: raise ValueError(f"不支持的LLM类型: {llm_type}. 可用的类型: {list(MODEL_CONFIGS.keys())}") config = MODEL_CONFIGS[llm_type] # 特殊处理 ollama 类型 if llm_type == "ollama": os.environ["OPENAI_API_KEY"] = "NA" # 创建LLM实例 llm_chat = ChatOpenAI( base_url=config["base_url"], api_key=config["api_key"], model=config["chat_model"], temperature=DEFAULT_TEMPERATURE, timeout=30, # 添加超时配置(秒) max_retries=2 # 添加重试次数 ) llm_embedding = OpenAIEmbeddings( base_url=config["base_url"], api_key=config["api_key"], model=config["embedding_model"], deployment=config["embedding_model"] ) logger.info(f"成功初始化 {llm_type} LLM") return llm_chat, llm_embedding except ValueError as ve: logger.error(f"LLM配置错误: {str(ve)}") raise LLMInitializationError(f"LLM配置错误: {str(ve)}") except Exception as e: logger.error(f"初始化LLM失败: {str(e)}") raise LLMInitializationError(f"初始化LLM失败: {str(e)}") def get_llm(llm_type: str = DEFAULT_LLM_TYPE) -> ChatOpenAI: """ 获取LLM实例的封装函数,提供默认值和错误处理 Args: llm_type (str): LLM类型 Returns: ChatOpenAI: LLM实例 """ try: return initialize_llm(llm_type) except LLMInitializationError as e: logger.warning(f"使用默认配置重试: {str(e)}") if llm_type != DEFAULT_LLM_TYPE: return initialize_llm(DEFAULT_LLM_TYPE) raise # 如果默认配置也失败,则抛出异常 ``` ## 4、项目演示 ### 4.1 RAG功能演示 ```bashe python vectorSave.py ``` ### 4.2 WorkFlow+Agent功能演示 ```bash python ragAgent.py ``` **Question Test:** 1. 你好,我是聚客AI学院Kevin 2. 我是谁? 3. 3*4 4. 张三九的健康档案信息 5. Kevin的健康档案信息 **注意事项:** 调用Qwen模型接口时,会报错如下所示: > openai.BadRequestError: Error code: 400 - {'error': {'message': 'input should not be none.: payload.input.contents (request id: 2024082015351785023974771558878)', 'type': 'upstream_error', 'param': '400', 'code': 'bad_response_status_code'}} 经过分析后,langchain_openai/embeddings包中的base.py源码中默认如下代码的true改为false即可 ```python check_embedding_ctx_length: bool = False ``` 源码完整路径如下所示: > C:\ProgramData\miniconda3\envs\L1-Project-2\Lib\site-packages\langchain_openai\embeddings\base.py 优雅修改方式: ```python llm_embedding = OpenAIEmbeddings( base_url=config["base_url"], api_key=config["api_key"], model=config["embedding_model"], deployment=config["embedding_model"], check_embedding_ctx_length=False ) ``` ## 五、工具(Tools)开发 ### 5.1 检索工具和自定义工具 ```python from langchain_chroma import Chroma from langchain.tools.retriever import create_retriever_tool from langchain_core.tools import tool from config import Config def get_tools(llm_embedding): """ 创建并返回工具列表。 Args: llm_embedding: 嵌入模型实例,用于初始化向量存储。 Returns: list: 工具列表。 """ # 创建Chroma向量存储实例 vectorstore = Chroma( persist_directory=Config.CHROMADB_DIRECTORY, collection_name=Config.CHROMADB_COLLECTION_NAME, embedding_function=llm_embedding, ) # 将向量存储转换为检索器 retriever = vectorstore.as_retriever() # 创建检索工具 retriever_tool = create_retriever_tool( retriever, name="retrieve", description="这是健康档案查询工具。搜索并返回有关用户的健康档案信息。" ) # 自定义 multiply 工具 @tool def multiply(a: float, b: float) -> float: """这是计算两个数的乘积的工具。返回最终的计算结果""" return a * b # 返回工具列表 return [retriever_tool, multiply] ``` ### 5.2 工具配置管理类 ```python # 定义工具配置管理类,用于管理工具及其路由配置 class ToolConfig: # 初始化方法,接收工具列表并设置相关属性 def __init__(self, tools): # 将传入的工具列表存储到实例变量 self.tools 中 self.tools = tools # 创建一个集合,包含所有工具的名称,使用集合推导式从 tools 中提取 name 属性 self.tool_names = {tool.name for tool in tools} # 调用内部方法 _build_routing_config,动态生成工具路由配置并存储到 self.tool_routing_config self.tool_routing_config = self._build_routing_config(tools) # 记录日志,输出初始化完成的工具名称集合和路由配置,便于调试和验证 logger.info(f"Initialized ToolConfig with tools: {self.tool_names}, routing: {self.tool_routing_config}") # 内部方法,用于根据工具定义动态构建路由配置 def _build_routing_config(self, tools): # 创建一个空字典,用于存储工具名称到目标节点的映射 routing_config = {} # 遍历传入的工具列表,逐个处理每个工具 for tool in tools: # 将工具名称转换为小写,确保匹配时忽略大小写 tool_name = tool.name.lower() # 检查工具名称中是否包含 "retrieve",用于判断是否为检索类工具 if "retrieve" in tool_name: # 如果是检索类工具,将其路由目标设置为 "grade_documents"(需要评分) routing_config[tool_name] = "grade_documents" # 记录调试日志,说明该工具被路由到 "grade_documents",并标注为检索工具 logger.debug(f"Tool '{tool_name}' routed to 'grade_documents' (retrieval tool)") # 如果工具名称不包含 "retrieve" else: # 将其路由目标设置为 "generate"(直接生成结果) routing_config[tool_name] = "generate" # 记录调试日志,说明该工具被路由到 "generate",并标注为非检索工具 logger.debug(f"Tool '{tool_name}' routed to 'generate' (non-retrieval tool)") # 检查路由配置字典是否为空(即没有工具被处理) if not routing_config: # 如果为空,记录警告日志,提示工具列表可能为空或未正确处理 logger.warning("No tools provided or routing config is empty") # 返回生成的路由配置字典 return routing_config # 获取工具列表的方法,返回存储在实例中的 tools def get_tools(self): # 直接返回 self.tools,提供外部访问工具列表的接口 return self.tools # 获取工具名称集合的方法,返回存储在实例中的 tool_names def get_tool_names(self): # 直接返回 self.tool_names,提供外部访问工具名称集合的接口 return self.tool_names # 获取工具路由配置的方法,返回动态生成的路由配置 def get_tool_routing_config(self): # 直接返回 self.tool_routing_config,提供外部访问路由配置的接口 return self.tool_routing_config ``` ## 六、核心功能开发 ### 6.1 创建并配置状态图 ```python def create_graph(db_connection_pool: ConnectionPool, llm_chat, llm_embedding, tool_config: ToolConfig) -> StateGraph: """创建并配置状态图。 Args: db_connection_pool: 数据库连接池。 llm_chat: Chat模型。 llm_embedding: Embedding模型。 tool_config: 工具配置参数。 Returns: StateGraph: 编译后的状态图。 Raises: ConnectionPoolError: 如果连接池未正确初始化或状态异常。 """ # 检查连接池是否为None或未打开 if db_connection_pool is None or db_connection_pool.closed: logger.error("Connection db_connection_pool is None or closed") raise ConnectionPoolError("数据库连接池未初始化或已关闭") try: # 获取当前活动连接数和最大连接数 active_connections = db_connection_pool.get_stats().get("connections_in_use", 0) max_connections = db_connection_pool.max_size if active_connections >= max_connections: logger.error(f"Connection db_connection_pool exhausted: {active_connections}/{max_connections} connections in use") raise ConnectionPoolError("连接池已耗尽,无可用连接") if not test_connection(db_connection_pool): raise ConnectionPoolError("连接池测试失败") logger.info("Connection db_connection_pool status: OK, test connection successful") except OperationalError as e: logger.error(f"Database operational error during connection test: {e}") raise ConnectionPoolError(f"连接池测试失败,可能已关闭或超时: {str(e)}") except Exception as e: logger.error(f"Failed to verify connection db_connection_pool status: {e}") raise ConnectionPoolError(f"无法验证连接池状态: {str(e)}") # 线程内持久化存储 try: # 创建Postgres检查点保存实例 checkpointer = PostgresSaver(db_connection_pool) # 初始化检查点 checkpointer.setup() except Exception as e: logger.error(f"Failed to setup PostgresSaver: {e}") raise ConnectionPoolError(f"检查点初始化失败: {str(e)}") # 跨线程持久化存储 try: # 创建Postgres存储实例,指定嵌入维度和函数 store = PostgresStore(db_connection_pool, index={"dims": 1536, "embed": llm_embedding}) store.setup() except Exception as e: logger.error(f"Failed to setup PostgresStore: {e}") raise ConnectionPoolError(f"存储初始化失败: {str(e)}") # 创建状态图实例,使用MessagesState作为状态类型 workflow = StateGraph(MessagesState) # 添加代理节点 workflow.add_node("agent", lambda state, config: agent(state, config, store=store, llm_chat=llm_chat, tool_config=tool_config)) # 添加工具节点,使用并行工具节点 workflow.add_node("call_tools", ParallelToolNode(tool_config.get_tools(), max_workers=5)) # 添加重写节点 workflow.add_node("rewrite", lambda state: rewrite(state,llm_chat=llm_chat)) # 添加生成节点 workflow.add_node("generate", lambda state: generate(state, llm_chat=llm_chat)) # 添加文档相关性评分节点 workflow.add_node("grade_documents", lambda state: grade_documents(state, llm_chat=llm_chat)) # 添加从起始到代理的边 workflow.add_edge(START, end_key="agent") # 添加代理的条件边,根据工具调用的工具名称决定下一步路由 workflow.add_conditional_edges(source="agent", path=tools_condition, path_map={"tools": "call_tools", END: END}) # 添加检索的条件边,根据工具调用的结果动态决定下一步路由 workflow.add_conditional_edges(source="call_tools", path=lambda state: route_after_tools(state, tool_config),path_map={"generate": "generate", "grade_documents": "grade_documents"}) # 添加检索的条件边,根据状态中的评分结果决定下一步路由 workflow.add_conditional_edges(source="grade_documents", path=route_after_grade, path_map={"generate": "generate", "rewrite": "rewrite"}) # 添加从生成到结束的边 workflow.add_edge(start_key="generate", end_key=END) # 添加从重写到代理的边 workflow.add_edge(start_key="rewrite", end_key="agent") # 编译状态图,绑定检查点和存储 return workflow.compile(checkpointer=checkpointer, store=store) ``` ### 6.2 保存状态图 ```python def save_graph_visualization(graph: StateGraph, filename: str = "graph.png") -> None: """保存状态图的可视化表示。 Args: graph: 状态图实例。 filename: 保存文件路径。 """ # 尝试执行以下代码块 try: # 以二进制写模式打开文件 with open(filename, "wb") as f: # 将状态图转换为Mermaid格式的PNG并写入文件 f.write(graph.get_graph().draw_mermaid_png()) # 记录保存成功的日志 logger.info(f"Graph visualization saved as {filename}") # 捕获IO错误 except IOError as e: # 记录警告日志 logger.warning(f"Failed to save graph visualization: {e}") ``` 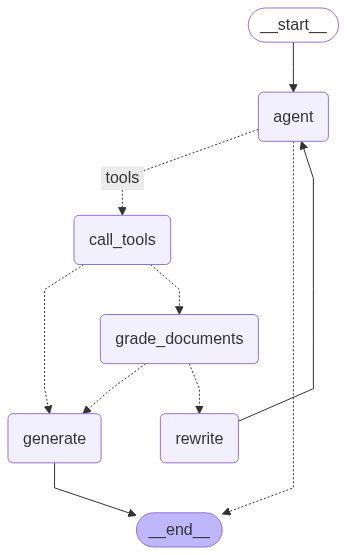 ### 6.3 Agent处理用户意图识别 ```python # 定义 Node agent分诊函数 def agent(state: MessagesState, config: RunnableConfig, *, store: BaseStore, llm_chat, tool_config: ToolConfig) -> dict: """代理函数,根据用户问题决定是否调用工具或结束。 Args: state: 当前对话状态。 config: 运行时配置。 store: 数据存储实例。 llm_chat: Chat模型。 tool_config: 工具配置参数。 Returns: dict: 更新后的对话状态。 """ # 记录代理开始处理查询 logger.info("Agent processing user query") # 定义存储命名空间,使用用户ID namespace = ("memories", config["configurable"]["user_id"]) # 尝试执行以下代码块 try: # 获取最后一条消息即用户问题 question = state["messages"][-1] logger.info(f"agent question:{question}") # 自定义跨线程持久化存储记忆并获取相关信息 user_info = store_memory(question, config, store) # 自定义线程内存储逻辑,过滤消息 messages = filter_messages(state["messages"]) # 将工具绑定到 LLM llm_chat_with_tool = llm_chat.bind_tools(tool_config.get_tools()) # 创建代理处理链 agent_chain = create_chain(llm_chat_with_tool, Config.PROMPT_TEMPLATE_TXT_AGENT) # 调用代理链处理消息 response = agent_chain.invoke({"question": question,"messages": messages, "userInfo": user_info}) # logger.info(f"Agent response: {response}") # 返回更新后的对话状态 return {"messages": [response]} # 捕获异常 except Exception as e: # 记录错误日志 logger.error(f"Error in agent processing: {e}") # 返回错误消息 return {"messages": [{"role": "system", "content": "处理请求时出错"}]} ``` ## 七、FastAPI 开发API接口 基于 FastAPI 进行API接口开发 1. 启动 main.py 程序 2. 启动 apiTest.py 程序进行测试 ## 八、WebUI开发 ### 8.1 Gradio 构建Web界面 ```bash pip install gradio ``` ### 8.2 项目启动测试 1. 启动 `main.py` 程序 2. 启动 `webUI.py` 程序 3. 浏览器访问 http://127.0.0.1:7860 4. 用户注册,再登录访问 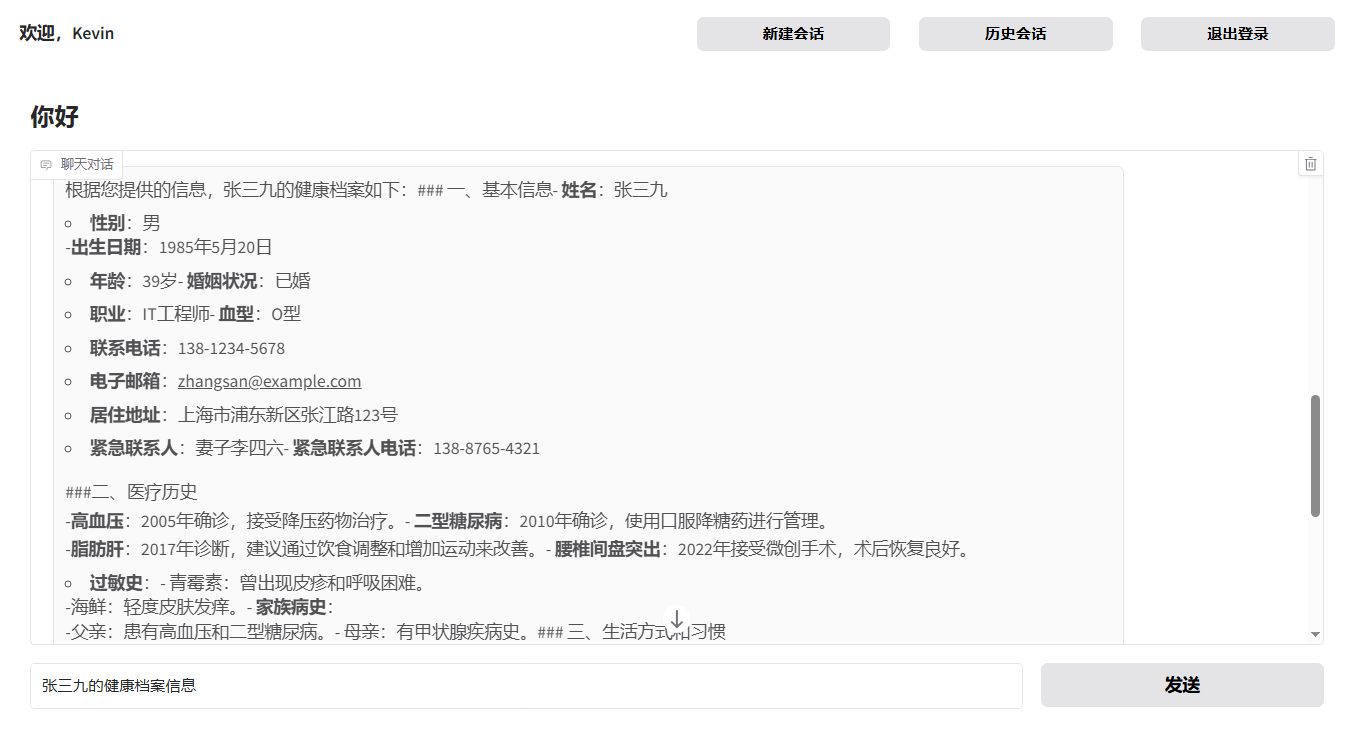 5. 点击 `新建会话` 开启新会话 ### 8.3 历史会话加载 点击 `历史会话` ,从会话历史中选择加载历史对话消息 附环境 requirements.txt ```python aiofiles==24.1.0 aiohappyeyeballs==2.6.1 aiohttp==3.12.7 aiosignal==1.3.2 annotated-types==0.7.0 anyio==4.9.0 asgiref==3.8.1 attrs==25.3.0 backoff==2.2.1 bcrypt==4.3.0 build==1.2.2.post1 cachetools==5.5.2 certifi==2025.4.26 cffi==1.17.1 charset-normalizer==3.4.2 chroma-hnswlib==0.7.6 chromadb==0.6.3 click==8.2.1 colorama==0.4.6 coloredlogs==15.0.1 concurrent-log-handler==0.9.25 cryptography==45.0.3 dashscope==1.23.4 dataclasses-json==0.6.7 Deprecated==1.2.18 distro==1.9.0 durationpy==0.10 fastapi==0.115.12 ffmpy==0.6.0 filelock==3.18.0 flatbuffers==25.2.10 frozenlist==1.6.0 fsspec==2025.5.1 google-auth==2.40.2 googleapis-common-protos==1.70.0 gradio==5.32.1 gradio_client==1.10.2 greenlet==3.2.2 groovy==0.1.2 grpcio==1.72.1 h11==0.16.0 httpcore==1.0.9 httptools==0.6.4 httpx==0.28.1 httpx-sse==0.4.0 huggingface-hub==0.32.3 humanfriendly==10.0 idna==3.10 importlib_metadata==8.6.1 importlib_resources==6.5.2 Jinja2==3.1.6 jiter==0.10.0 joblib==1.5.1 jsonpatch==1.33 jsonpointer==3.0.0 kubernetes==32.0.1 langchain==0.3.25 langchain-chroma==0.2.2 langchain-community==0.3.19 langchain-core==0.3.63 langchain-openai==0.3.6 langchain-text-splitters==0.3.8 langgraph==0.2.74 langgraph-checkpoint==2.0.26 langgraph-checkpoint-postgres==2.0.21 langgraph-sdk==0.1.70 langsmith==0.3.44 markdown-it-py==3.0.0 MarkupSafe==3.0.2 marshmallow==3.26.1 mdurl==0.1.2 mmh3==5.1.0 mpmath==1.3.0 multidict==6.4.4 mypy_extensions==1.1.0 nltk==3.9.1 numpy==1.26.4 oauthlib==3.2.2 onnxruntime==1.22.0 openai==1.83.0 opentelemetry-api==1.33.1 opentelemetry-exporter-otlp-proto-common==1.33.1 opentelemetry-exporter-otlp-proto-grpc==1.33.1 opentelemetry-instrumentation==0.54b1 opentelemetry-instrumentation-asgi==0.54b1 opentelemetry-instrumentation-fastapi==0.54b1 opentelemetry-proto==1.33.1 opentelemetry-sdk==1.33.1 opentelemetry-semantic-conventions==0.54b1 opentelemetry-util-http==0.54b1 orjson==3.10.18 ormsgpack==1.10.0 overrides==7.7.0 packaging==24.2 pandas==2.2.3 pdfminer==20191125 pdfminer.six==20250506 pillow==11.2.1 portalocker==3.1.1 posthog==4.2.0 propcache==0.3.1 protobuf==5.29.5 psycopg==3.2.9 psycopg-pool==3.2.6 psycopg2==2.9.10 pyasn1==0.6.1 pyasn1_modules==0.4.2 pycparser==2.22 pycryptodome==3.23.0 pydantic==2.11.5 pydantic-settings==2.9.1 pydantic_core==2.33.2 pydub==0.25.1 Pygments==2.19.1 PyPika==0.48.9 pyproject_hooks==1.2.0 pyreadline3==3.5.4 python-dateutil==2.9.0.post0 python-dotenv==1.1.0 python-multipart==0.0.20 pytz==2025.2 pywin32==310 PyYAML==6.0.2 regex==2024.11.6 requests==2.32.3 requests-oauthlib==2.0.0 requests-toolbelt==1.0.0 rich==14.0.0 rsa==4.9.1 ruff==0.11.12 safehttpx==0.1.6 semantic-version==2.10.0 shellingham==1.5.4 six==1.17.0 sniffio==1.3.1 SQLAlchemy==2.0.41 starlette==0.46.2 sympy==1.14.0 tenacity==9.1.2 tiktoken==0.9.0 tokenizers==0.21.1 tomlkit==0.13.2 tqdm==4.67.1 typer==0.16.0 typing-inspect==0.9.0 typing-inspection==0.4.1 typing_extensions==4.14.0 tzdata==2025.2 urllib3==2.4.0 uvicorn==0.34.3 watchfiles==1.0.5 websocket-client==1.8.0 websockets==15.0.1 wrapt==1.17.2 yarl==1.20.0 zipp==3.22.0 zstandard==0.23.0 ``` **附件 代码文件** [【附件】L1-Project-2.zip](/media/attachment/2025/10/L1-Project-2.zip)
李智
2025年10月2日 15:33
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
分享
链接
类型
密码
更新密码