AI大模型学习
1、环境搭建
2、Embedding与向量数据库
3、RAG技术与应用
4、RAG高级技术与实践
5、LlamaIndex知识管理与信息检索
6、基于LlamaIndex开发的中医临床诊疗助手
7、LangChain多任务应用开发
8、Function Calling与Agent 智能体
9、Agent应用与图状态编排框架LangGraph
10、基于LangGraph实现智能分诊系统
11、MCP应用技术开发
12、AI 应用开发新范式 MCP 技术详解
13、基于LangGraph的多智能体交互系统
14、企业级智能分诊系统RAG项目
15、LangGraph与Agno-AGI深度对比分析
本文档使用 MrDoc 发布
-
+
首页
7、LangChain多任务应用开发
# LangChain多任务应用开发 ## 💡 学习目标 1. 如何使用 LangChain:一套在大模型能力上封装的工具框架 2. 如何用几行代码实现一个复杂的 AI 应用 3. 面向大模型的流程开发的过程抽象 ## 写在前面 - LangChain 也是一套面向大模型的开发框架(SDK) - LangChain 是 AGI 时代软件工程的一个探索和原型 - 学习 LangChain 要关注接口变更 ## LangChain 的核心组件 1. 模型 I/O 封装 - Chat Models:对语言模型接口的封装 - PromptTemple:提示词模板 - OutputParser:解析输出 2. 数据连接封装(弱于 LlamaIndex) - Document Loaders:各种格式文件的加载器 - Document Transformers:对文档的常用操作,如:split, filter, translate, extract metadata, etc - Text Embedding Models:文本向量化表示,用于检索等操作 - Verctorstores & Retrievers:向量数据库与向量检索 3. 架构封装 - Chain/LCEL:实现一个功能或者一系列顺序功能组合 - Agent:根据用户输入,自动规划执行步骤,自动选择每步需要的工具,最终完成用户指定的功能 - Tools:调用外部功能的函数,例如:调 google 搜索、文件 I/O、Linux Shell 等等 - LangGraph:工作流开发框架 5. LangSmith:过程监控与调试框架 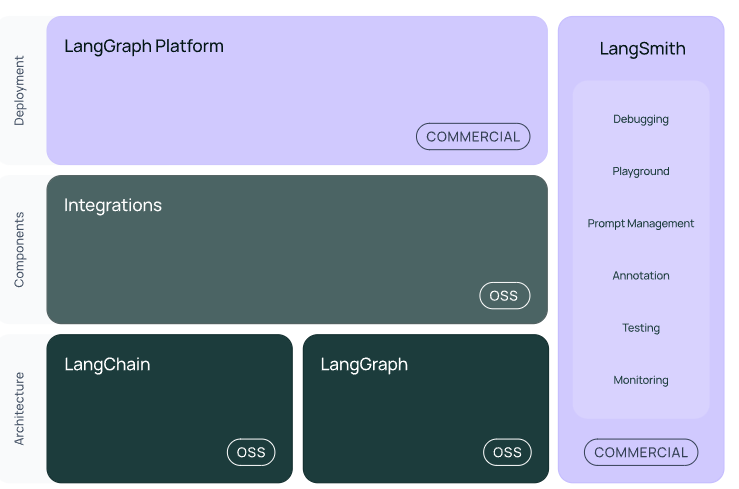 ### 文档(以 Python 版为例) - 功能模块:https://python.langchain.com/docs/tutorials - API 文档:https://python.langchain.com/api_reference/ - 三方组件集成:https://python.langchain.com/docs/integrations/providers/ - 更多 HowTo:https://python.langchain.com/docs/how_to/ ### LangChain 是开源项目 项目地址:https://github.com/langchain-ai ## 1. 模型 I/O 封装 把不同的模型,统一封装成一个接口,方便更换模型而不用重构代码。 ### 1.1 模型 API: ChatModel #### 1.1.1 OpenAI 模型封装 ```python # !pip install -U langchain # !pip install -U langchain-openai ``` ```python from langchain.chat_models import init_chat_model model = init_chat_model("gpt-4o-mini", model_provider="openai") response = model.invoke("你是谁") print(response.content) # 我是一个人工智能助手,旨在提供信息和回答问题。如果你有任何问题或需要帮助,随时可以问我! ``` #### 1.1.2 多轮对话 Session 封装 ```python from langchain.schema import ( AIMessage, # 等价于OpenAI接口中的assistant role HumanMessage, # 等价于OpenAI接口中的user role SystemMessage # 等价于OpenAI接口中的system role ) messages = [ SystemMessage(content="你是AI大模型课的课程助理。"), HumanMessage(content="我是AI学员,我叫小聚。"), AIMessage(content="欢迎!"), HumanMessage(content="我是谁?") ] ret = model.invoke(messages) print(ret.content) # 你是AI的学员,小聚。很高兴见到你!有什么我可以帮助你的吗? ``` <div class="alert alert-success"> <b>划重点:</b>通过模型封装,实现不同模型的统一接口调用 </div> #### 1.1.3 DeepSeek 模型封装 ```python # !pip install -U langchain-deepseek ``` ```python from langchain.chat_models import init_chat_model model = init_chat_model(model="deepseek-chat", model_provider="deepseek") response = model.invoke("你是谁") print(response.content) # 我是DeepSeek Chat,由深度求索公司开发的智能AI助手!✨ 我的使命是帮助你解答各种问题,无论是学习、工作,还是日常生活中的小疑惑,我都会尽力提供准确、有用的信息。 # 有什么我可以帮你的吗?😊 ``` #### 1.1.4 流式输出 ```python for token in model.stream("你是谁"): print(token.content, end="") # 我是DeepSeek Chat,由深度求索公司创造的智能AI助手!🤖✨ 我的使命是帮助你解答问题、提供信息、陪你聊天,还能处理各种文本和文件。无论是学习、工作,还是日常生活中的疑问,我都会尽力帮你解决!有什么想问的,尽管来吧~ ``` #### 1.1.5 通义千问模型封装 1. OpenAI兼容接口 ```python from langchain_openai import ChatOpenAI import os chatLLM = ChatOpenAI( api_key=os.getenv("DASHSCOPE_API_KEY"), base_url="https://dashscope.aliyuncs.com/compatible-mode/v1", model="qwen-plus", # 此处以qwen-plus为例,您可按需更换模型名称。模型列表:https://help.aliyun.com/zh/model-studio/getting-started/models # other params... ) messages = [ {"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "你是谁?"}] response = chatLLM.invoke(messages) response ``` ```python AIMessage(content='我是通义千问,阿里巴巴集团旗下的通义实验室自主研发的超大规模语言模型。我可以帮助你回答问题、创作文字,比如写故事、写公文、写邮件、写剧本、逻辑推理、编程等等,还能表达观点,玩游戏等。如果你有任何问题或需要帮助,欢迎随时告诉我!', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 66, 'prompt_tokens': 26, 'total_tokens': 92, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}}, 'model_name': 'qwen-plus', 'system_fingerprint': None, 'id': 'chatcmpl-37010fed-34c9-96ba-ac5c-f257e40aef30', 'service_tier': None, 'finish_reason': 'stop', 'logprobs': None}, id='run--0124e2f8-c7f3-47bd-987e-62a46c1f56fe-0', usage_metadata={'input_tokens': 26, 'output_tokens': 66, 'total_tokens': 92, 'input_token_details': {'cache_read': 0}, 'output_token_details': {}}) ``` 2. DashScope 接口 ```python # !pip install langchain-community # !pip install dashscope ``` ```python from langchain_community.chat_models.tongyi import ChatTongyi from langchain_core.messages import HumanMessage chatLLM = ChatTongyi( model="qwen-max", # 此处以qwen-max为例,您可按需更换模型名称。模型列表:https://help.aliyun.com/zh/model-studio/getting-started/models streaming=True, # other params... ) res = chatLLM.stream([HumanMessage(content="hi")], streaming=True) for r in res: print("chat resp:", r.content) # chat resp: Hello # chat resp: ! How can # chat resp: I assist you # chat resp: today? # chat resp: ``` #### 1.1.6 Ollama模型封装 ```python # !pip install -U langchain-ollama ``` ```python from langchain_ollama import ChatOllama llm = ChatOllama( model="qwen3:8b", temperature=0.7, # other params... ) messages = [ ( "system", "你是一名专业的翻译家,可以将用户的中文翻译为英文。", ), ("human", "我喜欢编程。"), ] ai_msg = llm.invoke(messages) print(ai_msg.content) ``` ```python <think> 好的,用户让我翻译“我喜欢编程。”这句话。首先,我需要确认这句话的准确意思。用户可能是在表达对编程的兴趣或热情。接下来,我要考虑不同的翻译方式,确保自然且符合英语习惯。 首先,直译的话是“I like programming.” 这是最直接的翻译,但可能不够生动。用户可能希望表达更强烈的感情,比如“我热爱编程”或者“我对编程充满热情”。这时候可以考虑使用更丰富的词汇,比如“love”或者“am passionate about”。 另外,还要注意语法结构。中文的“喜欢”对应英文的“like”或“love”,但根据语境选择合适的词。如果用户只是简单表达兴趣,用“like”即可;如果想强调热情,用“love”更合适。 还要考虑用户的潜在需求。用户可能是在写简历、申请学校,或者只是日常交流。如果是正式场合,可能需要更专业的表达,比如“I enjoy programming”或者“I am passionate about programming.” 如果是日常对话,简单的“I like programming”就足够。 另外,用户可能有更深层次的需求,比如寻找编程学习资源,或者讨论编程相关的话题。这时候翻译可能需要更详细,但根据当前问题,用户只需要翻译这句话,所以不需要扩展。 还要检查是否有文化差异需要注意。中文中的“喜欢”在英文中可能有不同的程度,但通常“like”已经足够表达。如果用户想更强烈,可以建议使用“love”或“passionate about”。 最后,确保翻译准确且自然,符合英语母语者的表达习惯,避免直译导致的生硬。比如,中文的“我喜欢编程”在英文中更自然的表达是“I like programming”或者“I enjoy programming.”,而“love”可能显得过于强烈,除非用户特别强调。 总结一下,用户可能需要一个简洁且自然的翻译,所以给出几个选项,让用户选择最合适的。例如,直接翻译、更强烈的表达,或者更正式的说法。同时,确保没有语法错误,并且符合英语的使用习惯。 </think> I like programming. (或更生动地表达:I'm passionate about programming.) ``` ### 1.2 模型的输入与输出 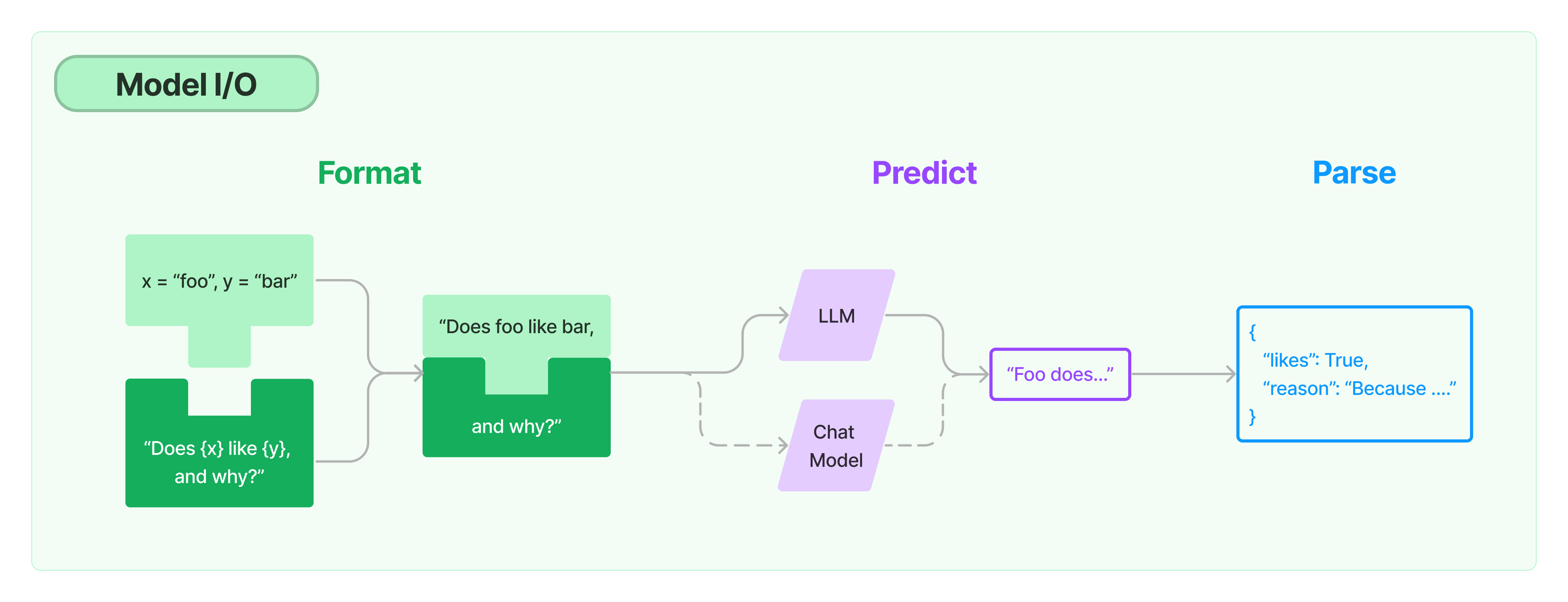 #### 1.2.1 Prompt 模板封装 1. PromptTemplate 可以在模板中自定义变量 ```python from langchain.prompts import PromptTemplate template = PromptTemplate.from_template("给我讲个关于{subject}的笑话") print("===Template===") print(template) print("===Prompt===") print(template.format(subject='小明')) # ===Template=== # input_variables=['subject'] input_types={} partial_variables={} template='给我讲个关于{subject}的笑话' # ===Prompt=== # 给我讲个关于小明的笑话 ``` ```python from langchain.chat_models import init_chat_model # 定义 LLM llm = init_chat_model("deepseek-chat", model_provider="deepseek") # 通过 Prompt 调用 LLM ret = llm.invoke(template.format(subject='小明')) # 打印输出 print(ret.content) # 好的!来一个关于小明的经典校园笑话: # **数学课的疑问** # 老师问小明:“如果你有5个苹果,我拿走3个,你还剩几个?” # 小明瞪大眼睛:“这不公平!” # 老师:“……我只是问数学题。” # 小明:“可您真的会拿走啊!上次您说‘下课后收作业’,结果全班都没剩!” # (笑点在于小明总把假设题当成现实,顺便吐槽老师收作业的严格😂) # 需要其他类型的小明笑话还可以再问我哦! ``` 2. ChatPromptTemplate 用模板表示的对话上下文 ```python from langchain.prompts import ( ChatPromptTemplate, HumanMessagePromptTemplate, SystemMessagePromptTemplate, ) from langchain.chat_models import init_chat_model llm = init_chat_model("deepseek-chat", model_provider="deepseek", temperature=0) template = ChatPromptTemplate.from_messages( [ SystemMessagePromptTemplate.from_template("你是{product}的客服助手。你的名字叫{name}"), HumanMessagePromptTemplate.from_template("{query}") ] ) prompt = template.format_messages( product="聚客AI大模型课程", name="小聚", query="你是谁" ) print(prompt) ret = llm.invoke(prompt) print(ret.content) ``` ```python [SystemMessage(content='你是聚客AI大模型课程的客服助手。你的名字叫小聚', additional_kwargs={}, response_metadata={}), HumanMessage(content='你是谁', additional_kwargs={}, response_metadata={})] 你好呀!我是聚客AI大模型课程的客服助手,你可以叫我小聚!有什么可以帮你的吗?😊 ``` 3. MessagesPlaceholder 把多轮对话变成模板 ```python from langchain.prompts import ( ChatPromptTemplate, HumanMessagePromptTemplate, MessagesPlaceholder, ) human_prompt = "Translate your answer to {language}." human_message_template = HumanMessagePromptTemplate.from_template(human_prompt) chat_prompt = ChatPromptTemplate.from_messages( # variable_name 是 message placeholder 在模板中的变量名 # 用于在赋值时使用 [MessagesPlaceholder("history"), human_message_template] ) ``` ```python from langchain_core.messages import AIMessage, HumanMessage human_message = HumanMessage(content="Who is Elon Musk?") ai_message = AIMessage( content="Elon Musk is a billionaire entrepreneur, inventor, and industrial designer" ) messages = chat_prompt.format_prompt( # 对 "history" 和 "language" 赋值 history=[human_message, ai_message], language="中文" ) print(messages.to_messages()) # [HumanMessage(content='Who is Elon Musk?', additional_kwargs={}, response_metadata={}), AIMessage(content='Elon Musk is a billionaire entrepreneur, inventor, and industrial designer', additional_kwargs={}, response_metadata={}), HumanMessage(content='Translate your answer to 中文.', additional_kwargs={}, response_metadata={})] ``` ```python result = llm.invoke(messages) print(result.content) # 埃隆·马斯克(Elon Musk)是一位亿万富翁企业家、发明家和工业设计师。他是多家知名科技公司的创始人或领导者,包括特斯拉(Tesla,电动汽车和清洁能源)、SpaceX(航天技术)、Neuralink(脑机接口)、The Boring Company(隧道与基础设施)以及X(原Twitter,社交媒体平台)。 # 马斯克以推动颠覆性创新而闻名,比如电动汽车的普及、可重复使用火箭技术、超级高铁(Hyperloop)概念等。他出生于南非,拥有美国、加拿大和南非三重国籍,并因其大胆的商业愿景和争议性言论而备受关注。 ``` <div class="alert alert-success"> <b>划重点:</b>把Prompt模板看作带有参数的函数 </div> #### 1.2.2 从文件加载 Prompt 模板 ```python from langchain.prompts import PromptTemplate template = PromptTemplate.from_file("example_prompt_template.txt", encoding="utf-8") print("===Template===") print(template) print("===Prompt===") print(template.format(topic='黑色幽默')) # ===Template=== # input_variables=['topic'] input_types={} partial_variables={} template='举一个关于{topic}的例子' # ===Prompt=== # 举一个关于黑色幽默的例子 ``` ### 1.3 结构化输出 #### 1.3.1 直接输出 Pydantic 对象 ```python from pydantic import BaseModel, Field # 定义你的输出对象 class Date(BaseModel): year: int = Field(description="Year") month: int = Field(description="Month") day: int = Field(description="Day") era: str = Field(description="BC or AD") ``` ```python from langchain.prompts import PromptTemplate, ChatPromptTemplate, HumanMessagePromptTemplate from langchain_core.output_parsers import PydanticOutputParser from langchain.chat_models import init_chat_model llm = init_chat_model("gpt-4o", model_provider="openai") # 定义结构化输出的模型 structured_llm = llm.with_structured_output(Date) template = """提取用户输入中的日期。 用户输入: {query}""" prompt = PromptTemplate( template=template, ) query = "2023年四月6日天气晴..." input_prompt = prompt.format_prompt(query=query) structured_llm.invoke(input_prompt) # Date(year=2023, month=4, day=6, era='AD') ``` #### 1.3.2 输出指定格式的 JSON ```python # OpenAI 模型的JSON格式 json_schema = { "title": "Date", "description": "Formated date expression", "type": "object", "properties": { "year": { "type": "integer", "description": "year, YYYY", }, "month": { "type": "integer", "description": "month, MM", }, "day": { "type": "integer", "description": "day, DD", }, "era": { "type": "string", "description": "BC or AD", }, }, } structured_llm = llm.with_structured_output(json_schema) structured_llm.invoke(input_prompt) # {'year': 2023, 'month': 4, 'day': 6, 'era': 'AD'} ``` #### 1.3.3 使用 OutputParser [`OutputParser`](https://python.langchain.com/v0.2/docs/concepts/#output-parsers) 可以按指定格式解析模型的输出 ```python from langchain_core.output_parsers import JsonOutputParser parser = JsonOutputParser(pydantic_object=Date) prompt = PromptTemplate( template="提取用户输入中的日期。\n用户输入:{query}\n{format_instructions}", input_variables=["query"], partial_variables={"format_instructions": parser.get_format_instructions()}, ) input_prompt = prompt.format_prompt(query=query) output = llm.invoke(input_prompt) print("原始输出:\n"+output.content) print("\n解析后:") parser.invoke(output) ``` 原始输出: To extract the date from the user's input, "2023年四月6日天气晴", we need to parse the information and format it according to the given JSON schema. The date is expressed in Chinese as "2023年四月6日", which corresponds to April 6, 2023. Here's how we structure the extracted date in a JSON format adhering to the schema: ```json { "year": 2023, "month": 4, "day": 6, "era": "AD" } ``` - `year`, `month`, and `day` are extracted directly from the input. - The `era` is set to "AD" since the year provided is 2023, which is in the Anno Domini era. 解析后: {'year': 2023, 'month': 4, 'day': 6, 'era': 'AD'} 也可以用 `PydanticOutputParser` ```python from langchain_core.output_parsers import PydanticOutputParser parser = PydanticOutputParser(pydantic_object=Date) input_prompt = prompt.format_prompt(query=query) output = llm.invoke(input_prompt) print("原始输出:\n"+output.content) print("\n解析后:") parser.invoke(output) ``` 原始输出: To extract and format the date from the user input "2023年四月6日天气晴" according to the provided JSON schema, we need to identify the year, month, and day, and assume the default era as "AD", since the date is in a contemporary format without BC designation. Here's the extraction and formatting process: 1. **Year**: "2023年" indicates the year 2023. 2. **Month**: "四月" indicates the 4th month, which is April. 3. **Day**: "6日" indicates the 6th day. Based on the schema, the formatted JSON instance is: ```json { "year": 2023, "month": 4, "day": 6, "era": "AD" } ``` 解析后: Date(year=2023, month=4, day=6, era='AD') `OutputFixingParser` 利用大模型做格式自动纠错 ```python from langchain.output_parsers import OutputFixingParser from langchain.chat_models import init_chat_model llm = init_chat_model(model="gpt-4o-mini", model_provider="openai") # 纠错能力与大模型能力相关 new_parser = OutputFixingParser.from_llm(parser=parser, llm=llm) bad_output = output.content.replace("4","四") print("PydanticOutputParser:") try: parser.invoke(bad_output) except Exception as e: print(e) print("OutputFixingParser:") new_parser.invoke(bad_output) ``` PydanticOutputParser: Invalid json output: To extract and format the date from the user input "2023年四月6日天气晴" according to the provided JSON schema, we need to identify the year, month, and day, and assume the default era as "AD", since the date is in a contemporary format without BC designation. Here's the extraction and formatting process: 1. **Year**: "2023年" indicates the year 2023. 2. **Month**: "四月" indicates the 四th month, which is April. 3. **Day**: "6日" indicates the 6th day. Based on the schema, the formatted JSON instance is: ```json { "year": 2023, "month": 四, "day": 6, "era": "AD" } ``` For troubleshooting, visit: https://python.langchain.com/docs/troubleshooting/errors/OUTPUT_PARSING_FAILURE OutputFixingParser: Date(year=2023, month=4, day=6, era='AD') ### 1.4 Function Calling ```python from langchain_core.tools import tool @tool def add(a: int, b: int) -> int: """Add two integers. Args: a: First integer b: Second integer """ return a + b @tool def multiply(a: float, b: float) -> float: """Multiply two integers. Args: a: First integer b: Second integer """ return a * b ``` ```python import json llm_with_tools = llm.bind_tools([add, multiply]) query = "3.5的4倍是多少?" messages = [HumanMessage(query)] output = llm_with_tools.invoke(messages) print(json.dumps(output.tool_calls, indent=4)) ``` ```python [ { "name": "multiply", "args": { "a": 3.5, "b": 4 }, "id": "call_CMNraBTMDVO16XPszbIHB2AV", "type": "tool_call" } ] 回传 Funtion Call 的结果 ``` ```python messages.append(output) available_tools = {"add": add, "multiply": multiply} for tool_call in output.tool_calls: selected_tool = available_tools[tool_call["name"].lower()] tool_msg = selected_tool.invoke(tool_call) messages.append(tool_msg) new_output = llm_with_tools.invoke(messages) for message in messages: print(json.dumps(message.model_dump(), indent=4, ensure_ascii=False)) print(new_output.content) ``` ```python { "content": "3.5的4倍是多少?", "additional_kwargs": {}, "response_metadata": {}, "type": "human", "name": null, "id": null, "example": false } { "content": "", "additional_kwargs": { "tool_calls": [ { "id": "call_CMNraBTMDVO16XPszbIHB2AV", "function": { "arguments": "{\"a\":3.5,\"b\":4}", "name": "multiply" }, "type": "function" } ], "refusal": null }, "response_metadata": { "token_usage": { "completion_tokens": 19, "prompt_tokens": 99, "total_tokens": 118, "completion_tokens_details": { "accepted_prediction_tokens": 0, "audio_tokens": 0, "reasoning_tokens": 0, "rejected_prediction_tokens": 0 }, "prompt_tokens_details": { "audio_tokens": 0, "cached_tokens": 0 } }, "model_name": "gpt-4o-mini-2024-07-18", "system_fingerprint": "fp_560af6e559", "id": "chatcmpl-C5tu7Ddu2brBpqelhJ9HfSSxs4WMZ", "service_tier": "default", "finish_reason": "tool_calls", "logprobs": null }, "type": "ai", "name": null, "id": "run--59a516ba-ed5b-4075-a7b5-d709551250c3-0", "example": false, "tool_calls": [ { "name": "multiply", "args": { "a": 3.5, "b": 4 }, "id": "call_CMNraBTMDVO16XPszbIHB2AV", "type": "tool_call" } ], "invalid_tool_calls": [], "usage_metadata": { "input_tokens": 99, "output_tokens": 19, "total_tokens": 118, "input_token_details": { "audio": 0, "cache_read": 0 }, "output_token_details": { "audio": 0, "reasoning": 0 } } } { "content": "14.0", "additional_kwargs": {}, "response_metadata": {}, "type": "tool", "name": "multiply", "id": null, "tool_call_id": "call_CMNraBTMDVO16XPszbIHB2AV", "artifact": null, "status": "success" } 3.5的4倍是14.0。 ``` ### 1.5 小结 1. LangChain 统一封装了各种模型的调用接口,包括补全型和对话型两种 2. LangChain 提供了 PromptTemplate 类,可以自定义带变量的模板 3. LangChain 提供了一些列输出解析器,用于将大模型的输出解析成结构化对象 4. LangChain 提供了 Function Calling 的封装 5. 上述模型属于 LangChain 中较为实用的部分 ## 2. 数据连接封装 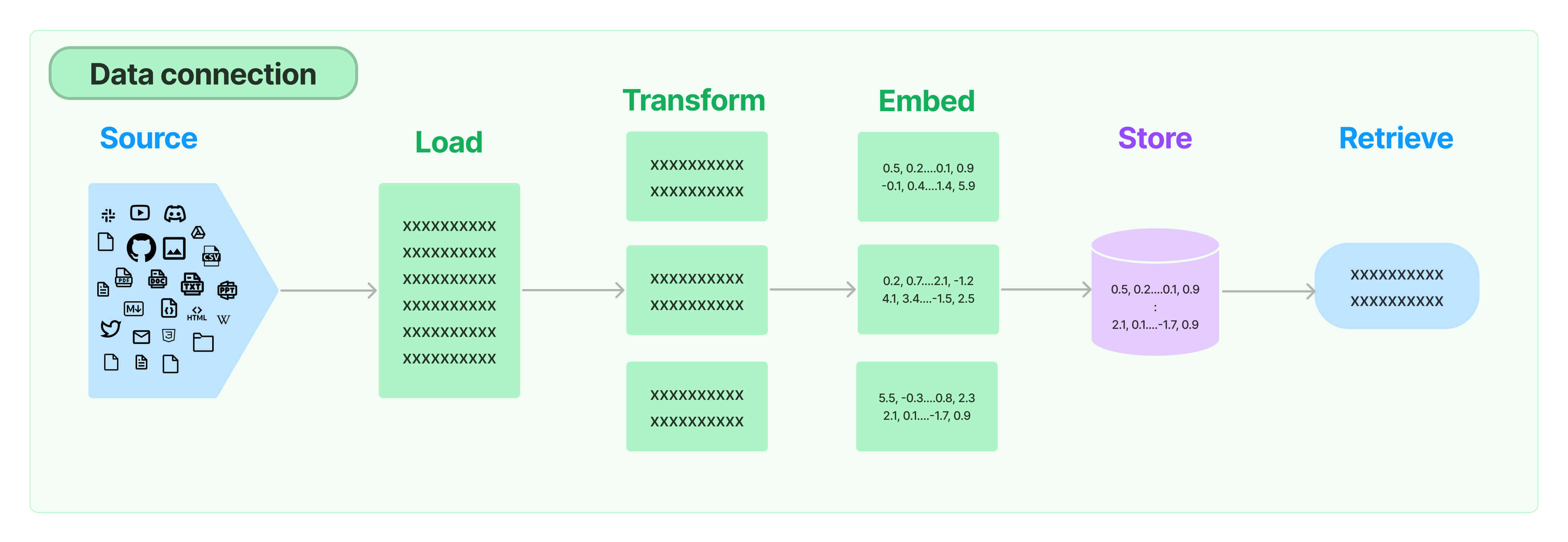 ### 2.1 文档加载器:Document Loaders ```python # !pip install -U langchain-community pymupdf ``` ```python from langchain_community.document_loaders import PyMuPDFLoader loader = PyMuPDFLoader("./data/deepseek-v3-1-4.pdf") pages = loader.load_and_split() print(pages[0].page_content) ``` ### 2.2 文档处理器 #### 2.2.1 TextSplitter ```python # !pip install --upgrade langchain-text-splitters ``` ```python from langchain_text_splitters import RecursiveCharacterTextSplitter text_splitter = RecursiveCharacterTextSplitter( chunk_size=512, chunk_overlap=200, length_function=len, add_start_index=True, ) paragraphs = text_splitter.create_documents([pages[0].page_content]) for para in paragraphs: print(para.page_content) print('-------') ``` <div class="alert alert-info"> 类似 LlamaIndex,LangChain 也提供了丰富的 <code><a href="https://python.langchain.com/v0.2/docs/how_to/#document-loaders">Document Loaders</a></code> 和 <code><a href="https://python.langchain.com/v0.2/docs/how_to/#text-splitters">Text Splitters</a></code>。 </div> ### 2.3、向量数据库与向量检索 ```python # !pip install dashscope # !pip install faiss-cpu ``` ```python import os from langchain_text_splitters import RecursiveCharacterTextSplitter from langchain_community.embeddings import DashScopeEmbeddings from langchain_community.vectorstores import FAISS from langchain_community.document_loaders import PyMuPDFLoader # 加载文档 loader = PyMuPDFLoader("./data/deepseek-v3-1-4.pdf") pages = loader.load_and_split() # 文档切分 text_splitter = RecursiveCharacterTextSplitter( chunk_size=512, chunk_overlap=200, length_function=len, add_start_index=True, ) texts = text_splitter.create_documents( [page.page_content for page in pages[:1]] ) # 灌库 embeddings = DashScopeEmbeddings( model="text-embedding-v1", dashscope_api_key=os.getenv("DASHSCOPE_API_KEY") ) index = FAISS.from_documents(texts, embeddings) # 检索 top-5 结果 retriever = index.as_retriever(search_kwargs={"k": 5}) docs = retriever.invoke("deepseek v3有多少参数") for doc in docs: print(doc.page_content) print("----") ``` 更多的三方检索组件链接,参考:https://python.langchain.com/docs/integrations/vectorstores/ ### 2.4 小结 1. 文档处理部分,建议在实际应用中详细测试后使用 2. 与向量数据库的链接部分本质是接口封装,向量数据库需要自己选型 ## 3. Chain 和 LangChain Expression Language (LCEL) LangChain Expression Language(LCEL)是一种声明式语言,可轻松组合不同的调用顺序构成 Chain。LCEL 自创立之初就被设计为能够支持将原型投入生产环境,**无需代码更改**,从最简单的“提示+LLM”链到最复杂的链(已有用户成功在生产环境中运行包含数百个步骤的 LCEL Chain)。 LCEL 的一些亮点包括: 1. **流支持**:使用 LCEL 构建 Chain 时,你可以获得最佳的首个令牌时间(即从输出开始到首批输出生成的时间)。对于某些 Chain,这意味着可以直接从 LLM 流式传输令牌到流输出解析器,从而以与 LLM 提供商输出原始令牌相同的速率获得解析后的、增量的输出。 2. **异步支持**:任何使用 LCEL 构建的链条都可以通过同步 API(例如,在 Jupyter 笔记本中进行原型设计时)和异步 API(例如,在 LangServe 服务器中)调用。这使得相同的代码可用于原型设计和生产环境,具有出色的性能,并能够在同一服务器中处理多个并发请求。 3. **优化的并行执行**:当你的 LCEL 链条有可以并行执行的步骤时(例如,从多个检索器中获取文档),我们会自动执行,无论是在同步还是异步接口中,以实现最小的延迟。 4. **重试和回退**:为 LCEL 链的任何部分配置重试和回退。这是使链在规模上更可靠的绝佳方式。目前我们正在添加重试/回退的流媒体支持,因此你可以在不增加任何延迟成本的情况下获得增加的可靠性。 5. **访问中间结果**:对于更复杂的链条,访问在最终输出产生之前的中间步骤的结果通常非常有用。这可以用于让最终用户知道正在发生一些事情,甚至仅用于调试链条。你可以流式传输中间结果,并且在每个 LangServe 服务器上都可用。 6. **输入和输出模式**:输入和输出模式为每个 LCEL 链提供了从链的结构推断出的 Pydantic 和 JSONSchema 模式。这可以用于输入和输出的验证,是 LangServe 的一个组成部分。 7. **无缝 LangSmith 跟踪集成**:随着链条变得越来越复杂,理解每一步发生了什么变得越来越重要。通过 LCEL,所有步骤都自动记录到 LangSmith,以实现最大的可观察性和可调试性。 8. **无缝 LangServe 部署集成**:任何使用 LCEL 创建的链都可以轻松地使用 LangServe 进行部署。 原文:https://python.langchain.com/docs/expression_language/ ### 3.1 Pipeline 式调用 PromptTemplate, LLM 和 OutputParser ```python from langchain.prompts import ChatPromptTemplate from langchain_core.output_parsers import StrOutputParser from langchain_core.runnables import RunnablePassthrough from pydantic import BaseModel, Field from typing import List, Dict, Optional from enum import Enum import json from langchain.chat_models import init_chat_model ``` ```python # 输出结构 class SortEnum(str, Enum): data = 'data' price = 'price' class OrderingEnum(str, Enum): ascend = 'ascend' descend = 'descend' class Semantics(BaseModel): name: Optional[str] = Field(description="流量包名称", default=None) price_lower: Optional[int] = Field(description="价格下限", default=None) price_upper: Optional[int] = Field(description="价格上限", default=None) data_lower: Optional[int] = Field(description="流量下限", default=None) data_upper: Optional[int] = Field(description="流量上限", default=None) sort_by: Optional[SortEnum] = Field(description="按价格或流量排序", default=None) ordering: Optional[OrderingEnum] = Field( description="升序或降序排列", default=None) # Prompt 模板 prompt = ChatPromptTemplate.from_messages( [ ("system", "你是一个语义解析器。你的任务是将用户的输入解析成JSON表示。不要回答用户的问题。"), ("human", "{text}"), ] ) # 模型 llm = init_chat_model("deepseek-chat", model_provider="deepseek") structured_llm = llm.with_structured_output(Semantics) # LCEL 表达式 runnable = ( {"text": RunnablePassthrough()} | prompt | structured_llm ) # 直接运行 ret = runnable.invoke("不超过100元的流量大的套餐有哪些") print( json.dumps( ret.model_dump(), indent = 4, ensure_ascii=False ) ) ``` ```python <div class="alert alert-success"> <b>使用 LCEL 的价值,也就是 LangChain 的核心价值。</b> <br /> 官方从不同角度给出了举例说明:<a href="https://python.langchain.com/docs/concepts/lcel/">https://python.langchain.com/docs/concepts/lcel/</a> </div> ``` ### 3.2 用 LCEL 实现 RAG ```python import os from langchain_text_splitters import RecursiveCharacterTextSplitter from langchain_community.vectorstores import FAISS from langchain.chains import RetrievalQA from langchain_community.document_loaders import PyMuPDFLoader from langchain_community.embeddings.dashscope import DashScopeEmbeddings # 加载文档 loader = PyMuPDFLoader("./data/deepseek-v3-1-4.pdf") pages = loader.load_and_split() # 文档切分 text_splitter = RecursiveCharacterTextSplitter( chunk_size=512, chunk_overlap=200, length_function=len, add_start_index=True, ) texts = text_splitter.create_documents( [page.page_content for page in pages[:1]] ) # 灌库 embeddings = DashScopeEmbeddings( model="text-embedding-v1", dashscope_api_key=os.getenv("DASHSCOPE_API_KEY") ) db = FAISS.from_documents(texts, embeddings) # 检索 top-5 结果 retriever = db.as_retriever(search_kwargs={"k": 5}) ``` ```python from langchain.schema.output_parser import StrOutputParser from langchain.schema.runnable import RunnablePassthrough # Prompt模板 template = """Answer the question based only on the following context: {context} Question: {question} """ prompt = ChatPromptTemplate.from_template(template) # Chain rag_chain = ( {"question": RunnablePassthrough(), "context": retriever} | prompt | llm | StrOutputParser() ) response = rag_chain.stream("deepseek V3有多少参数") for value in response: print(value, end='', flush=True) ``` DeepSeek-V3 是一个混合专家(Mixture-of-Experts, MoE)语言模型,总参数为 **6710 亿(671B)**,其中每个 token 激活 **370 亿(37B)** 参数。 ### 3.3 用 LCEL 实现模型切换(工厂模式) ```python from langchain_core.runnables.utils import ConfigurableField from langchain_community.chat_models import QianfanChatEndpoint from langchain.prompts import ( ChatPromptTemplate, HumanMessagePromptTemplate, ) from langchain.chat_models import init_chat_model from langchain.schema import HumanMessage import os # 模型1 ds_model = init_chat_model("deepseek-chat", model_provider="deepseek") # 模型2 gpt_model = init_chat_model("gpt-4o-mini", model_provider="openai") # 通过 configurable_alternatives 按指定字段选择模型 model = gpt_model.configurable_alternatives( ConfigurableField(id="llm"), default_key="gpt", deepseek=ds_model, # claude=claude_model, ) # Prompt 模板 prompt = ChatPromptTemplate.from_messages( [ HumanMessagePromptTemplate.from_template("{query}"), ] ) # LCEL chain = ( {"query": RunnablePassthrough()} | prompt | model | StrOutputParser() ) # 运行时指定模型 "gpt" or "deepseek" ret = chain.with_config(configurable={"llm": "gpt"}).invoke("请自我介绍") print(ret) # 你好!我是一个人工智能助手,旨在为你提供信息和支持。我可以回答问题、提供建议、帮助学习新知识,或者协助处理各种事务。如果你有任何特定的问题或需要帮助的地方,请随时告诉我! ``` 扩展阅读:什么是[**工厂模式**](https://www.runoob.com/design-pattern/factory-pattern.html);[**设计模式**](https://www.runoob.com/design-pattern/design-pattern-intro.html)概览。 <div class="alert alert-warning"> <b>思考:</b>从模块间解依赖角度,LCEL的意义是什么? </div> ### 3.4 通过 LCEL,还可以实现 1. 配置运行时变量:https://python.langchain.com/docs/how_to/configure/ 2. 故障回退:https://python.langchain.com/docs/how_to/fallbacks/ 3. 并行调用:https://python.langchain.com/docs/how_to/parallel/ 4. 逻辑分支:https://python.langchain.com/docs/how_to/routing/ 5. 动态创建 Chain: https://python.langchain.com/docs/how_to/dynamic_chain/ 更多例子:https://python.langchain.com/docs/how_to/lcel_cheatsheet/ ## 4. LangChain 与 LlamaIndex 的错位竞争 - LangChain 侧重与 LLM 本身交互的封装 - Prompt、LLM、Message、OutputParser 等工具丰富 - 在数据处理和 RAG 方面提供的工具相对粗糙 - 主打 LCEL 流程封装 - 配套 Agent、LangGraph 等智能体与工作流工具 - 另有 LangServe 部署工具和 LangSmith 监控调试工具 - LlamaIndex 侧重与数据交互的封装 - 数据加载、切割、索引、检索、排序等相关工具丰富 - Prompt、LLM 等底层封装相对单薄 - 配套实现 RAG 相关工具 - 同样配套智能体与工作流工具 - 提供 LlamaDeploy 部署工具,通过与三方合作提供过程监控调试工具 ## 5. 总结 1. LangChain 随着版本迭代可用性有明显提升 2. 使用 LangChain 要注意维护自己的 Prompt,尽量 Prompt 与代码逻辑解依赖 3. 它的内置基础工具,建议充分测试效果后再决定是否使用
李智
2025年9月30日 11:53
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
分享
链接
类型
密码
更新密码