kafka教程
01、Kafka 概述
02、Kafka 基础
03、Kafka 集群架构
04、Kafka 工作流程
05、Kafka 安装步骤
06、Kafka 基本操作
07、Kafka 简单生产者示例
08、Kafka 消费者组示例
09、Kafka 整合 Storm
10、Kafka 与Spark的集成
11、Kafka 实时应用程序(Twitter)
12、Kafka 工具
13、Kafka 应用
本文档使用 MrDoc 发布
-
+
首页
02、Kafka 基础
在深入了解Kafka之前,您必须了解主题,经纪人,生产者和消费者等主要术语。 下图说明了主要术语,表格详细描述了图表组件。 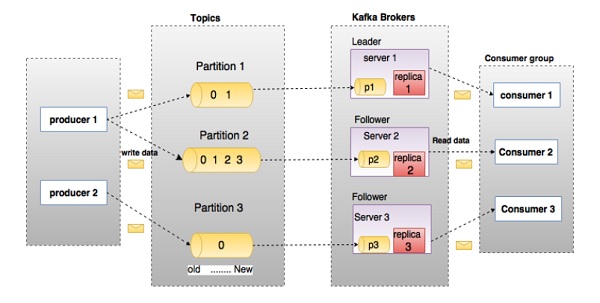 在上图中,主题配置为三个分区。 分区1具有两个偏移因子0和1.分区2具有四个偏移因子0,1,2和3.分区3具有一个偏移因子0.副本的id与承载它的服务器的id相同。 假设,如果主题的复制因子设置为3,那么Kafka将创建每个分区的3个相同的副本,并将它们放在集群中以使其可用于其所有操作。 为了平衡集群中的负载,每个代理都存储一个或多个这些分区。 多个生产者和消费者可以同时发布和检索消息。 | 列名 | 组件和说明 | | --- | --- | | 1 | **Topics(主题)**属于特定类别的消息流称为主题。 数据存储在主题中。主题被拆分成分区。 对于每个主题,Kafka保存一个分区的数据。 每个这样的分区包含不可变有序序列的消息。 分区被实现为具有相等大小的一组分段文件。 | | 2 | **Partition(分区)**主题可能有许多分区,因此它可以处理任意数量的数据。 | | 3 | **Partition offset(分区偏移)**每个分区消息具有称为 offset 的唯一序列标识。 | | 4 | **Replicas of partition(分区备份)**副本只是一个分区的备份。 副本从不读取或写入数据。 它们用于防止数据丢失。 | | 5 | **Brokers(经纪人)** **1、**代理是负责维护发布数据的简单系统。 每个代理中的每个主题可以具有零个或多个分区。 假设,如果在一个主题和N个代理中有N个分区,每个代理将有一个分区。 **2、**假设在一个主题中有N个分区并且多于N个代理(n + m),则第一个N代理将具有一个分区,并且下一个M代理将不具有用于该特定主题的任何分区 。 **3、** 假设在一个主题中有N个分区并且小于N个代理(n-m),每个代理将在它们之间具有一个或多个分区共享。 由于代理之间的负载分布不相等,不推荐使用此方案。 | | 6 | **Kafka Cluster(Kafka集群)**Kafka有多个代理被称为Kafka集群。 可以扩展Kafka集群,无需停机。 这些集群用于管理消息数据的持久性和复制。 | | 7 | **Producers(生产者)**生产者是发送给一个或多个Kafka主题的消息的发布者。 生产者向Kafka经纪人发送数据。 每当生产者将消息发布给代理时,代理只需将消息附加到最后一个段文件。 实际上,该消息将被附加到分区。 生产者还可以向他们选择的分区发送消息。 | | 8 | **Consumers(消费者)**Consumers从经纪人处读取数据。 消费者订阅一个或多个主题,并通过从代理中提取数据来使用已发布的消息。 | | 9 | **Leader(领导者)** Leader 是负责给定分区的所有读取和写入的节点。 每个分区都有一个服务器充当Leader。| | 10 | **Follower(追随者)** 跟随领导者指令的节点被称为Follower。 如果领导失败,一个追随者将自动成为新的领导者。 跟随者作为正常消费者,拉取消息并更新其自己的数据存储。|
李智
2025年3月17日 13:28
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
分享
链接
类型
密码
更新密码